 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFindings of the Counter Turing Test: AI-Generated Image Detection
May 21, 2026The rapid advancements in generative AI technologies, such as Stable Diffusion, DALL-E, and Midjourney, have significantly transformed the creation of synthetic visual content. While these models enable innovation across industries, they also pose serious challenges, including misinformation, disinformation, and biased content generation. The increasing realism of AI-generated images makes their detection a pressing concern for researchers, policymakers, and industry stakeholders. In this paper, we present the findings of the Defactify 4.0 workshop, which introduced the Counter Turing Test (CT2) for AI-Generated Image Detection. The competition consisted of two key tasks: (1) binary classification of images as either AI-generated or real and (2) identification of the specific generative model responsible for an AI-generated image. To facilitate this, we developed the MS COCOAI dataset, consisting of 50,000 synthetic images from multiple generative models alongside real-world images from the MS COCO dataset. Participants employed diverse detection strategies, including convolutional neural networks (CNNs), Vision Transformers (ViTs), frequency-based analysis, contrastive learning, and multimodal techniques. The results demonstrated that while AI-generated images can be detected with high accuracy (F1-score > 0.83), identifying the exact model used remains significantly more challenging (highest F1-score: 0.4986). These findings highlight the need for improved model fingerprinting, adversarial robustness, and real-time detection mechanisms.
A Comprehensive Dataset for Human vs. AI Generated Text Detection
Oct 26, 2025
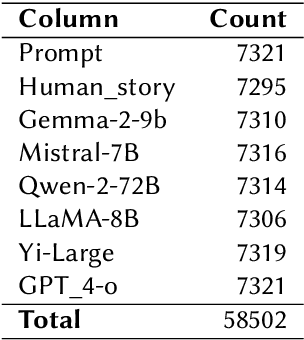
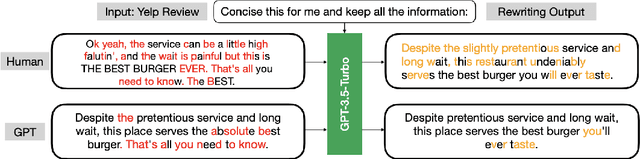

The rapid advancement of large language models (LLMs) has led to increasingly human-like AI-generated text, raising concerns about content authenticity, misinformation, and trustworthiness. Addressing the challenge of reliably detecting AI-generated text and attributing it to specific models requires large-scale, diverse, and well-annotated datasets. In this work, we present a comprehensive dataset comprising over 58,000 text samples that combine authentic New York Times articles with synthetic versions generated by multiple state-of-the-art LLMs including Gemma-2-9b, Mistral-7B, Qwen-2-72B, LLaMA-8B, Yi-Large, and GPT-4-o. The dataset provides original article abstracts as prompts, full human-authored narratives. We establish baseline results for two key tasks: distinguishing human-written from AI-generated text, achieving an accuracy of 58.35\%, and attributing AI texts to their generating models with an accuracy of 8.92\%. By bridging real-world journalistic content with modern generative models, the dataset aims to catalyze the development of robust detection and attribution methods, fostering trust and transparency in the era of generative AI. Our dataset is available at: https://huggingface.co/datasets/gsingh1-py/train.
Visual Counter Turing Test (VCT^2): Discovering the Challenges for AI-Generated Image Detection and Introducing Visual AI Index (V_AI)
Nov 24, 2024



The proliferation of AI techniques for image generation, coupled with their increasing accessibility, has raised significant concerns about the potential misuse of these images to spread misinformation. Recent AI-generated image detection (AGID) methods include CNNDetection, NPR, DM Image Detection, Fake Image Detection, DIRE, LASTED, GAN Image Detection, AIDE, SSP, DRCT, RINE, OCC-CLIP, De-Fake, and Deep Fake Detection. However, we argue that the current state-of-the-art AGID techniques are inadequate for effectively detecting contemporary AI-generated images and advocate for a comprehensive reevaluation of these methods. We introduce the Visual Counter Turing Test (VCT^2), a benchmark comprising ~130K images generated by contemporary text-to-image models (Stable Diffusion 2.1, Stable Diffusion XL, Stable Diffusion 3, DALL-E 3, and Midjourney 6). VCT^2 includes two sets of prompts sourced from tweets by the New York Times Twitter account and captions from the MS COCO dataset. We also evaluate the performance of the aforementioned AGID techniques on the VCT$^2$ benchmark, highlighting their ineffectiveness in detecting AI-generated images. As image-generative AI models continue to evolve, the need for a quantifiable framework to evaluate these models becomes increasingly critical. To meet this need, we propose the Visual AI Index (V_AI), which assesses generated images from various visual perspectives, including texture complexity and object coherence, setting a new standard for evaluating image-generative AI models. To foster research in this domain, we make our https://huggingface.co/datasets/anonymous1233/COCO_AI and https://huggingface.co/datasets/anonymous1233/twitter_AI datasets publicly available.
The Brittleness of AI-Generated Image Watermarking Techniques: Examining Their Robustness Against Visual Paraphrasing Attacks
Aug 19, 2024The rapid advancement of text-to-image generation systems, exemplified by models like Stable Diffusion, Midjourney, Imagen, and DALL-E, has heightened concerns about their potential misuse. In response, companies like Meta and Google have intensified their efforts to implement watermarking techniques on AI-generated images to curb the circulation of potentially misleading visuals. However, in this paper, we argue that current image watermarking methods are fragile and susceptible to being circumvented through visual paraphrase attacks. The proposed visual paraphraser operates in two steps. First, it generates a caption for the given image using KOSMOS-2, one of the latest state-of-the-art image captioning systems. Second, it passes both the original image and the generated caption to an image-to-image diffusion system. During the denoising step of the diffusion pipeline, the system generates a visually similar image that is guided by the text caption. The resulting image is a visual paraphrase and is free of any watermarks. Our empirical findings demonstrate that visual paraphrase attacks can effectively remove watermarks from images. This paper provides a critical assessment, empirically revealing the vulnerability of existing watermarking techniques to visual paraphrase attacks. While we do not propose solutions to this issue, this paper serves as a call to action for the scientific community to prioritize the development of more robust watermarking techniques. Our first-of-its-kind visual paraphrase dataset and accompanying code are publicly available.