 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Comprehensive Dataset for Human vs. AI Generated Text Detection
Oct 26, 2025
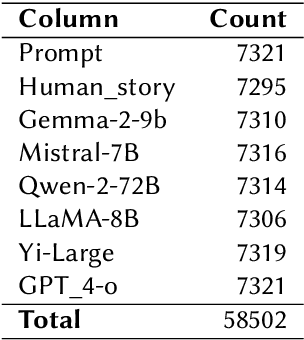

The rapid advancement of large language models (LLMs) has led to increasingly human-like AI-generated text, raising concerns about content authenticity, misinformation, and trustworthiness. Addressing the challenge of reliably detecting AI-generated text and attributing it to specific models requires large-scale, diverse, and well-annotated datasets. In this work, we present a comprehensive dataset comprising over 58,000 text samples that combine authentic New York Times articles with synthetic versions generated by multiple state-of-the-art LLMs including Gemma-2-9b, Mistral-7B, Qwen-2-72B, LLaMA-8B, Yi-Large, and GPT-4-o. The dataset provides original article abstracts as prompts, full human-authored narratives. We establish baseline results for two key tasks: distinguishing human-written from AI-generated text, achieving an accuracy of 58.35\%, and attributing AI texts to their generating models with an accuracy of 8.92\%. By bridging real-world journalistic content with modern generative models, the dataset aims to catalyze the development of robust detection and attribution methods, fostering trust and transparency in the era of generative AI. Our dataset is available at: https://huggingface.co/datasets/gsingh1-py/train.
LLMsAgainstHate @ NLU of Devanagari Script Languages 2025: Hate Speech Detection and Target Identification in Devanagari Languages via Parameter Efficient Fine-Tuning of LLMs
Dec 26, 2024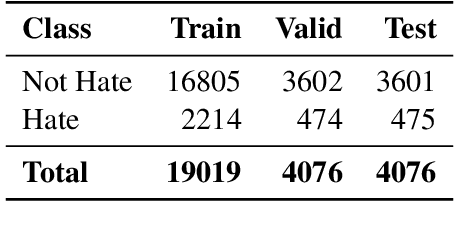



The detection of hate speech has become increasingly important in combating online hostility and its real-world consequences. Despite recent advancements, there is limited research addressing hate speech detection in Devanagari-scripted languages, where resources and tools are scarce. While large language models (LLMs) have shown promise in language-related tasks, traditional fine-tuning approaches are often infeasible given the size of the models. In this paper, we propose a Parameter Efficient Fine tuning (PEFT) based solution for hate speech detection and target identification. We evaluate multiple LLMs on the Devanagari dataset provided by (Thapa et al., 2025), which contains annotated instances in 2 languages - Hindi and Nepali. The results demonstrate the efficacy of our approach in handling Devanagari-scripted content.
Hate Speech Detection and Target Identification in Devanagari Languages via Parameter Efficient Fine-Tuning of LLMs
Dec 22, 2024The detection of hate speech has become increasingly important in combating online hostility and its real-world consequences. Despite recent advancements, there is limited research addressing hate speech detection in Devanagari-scripted languages, where resources and tools are scarce. While large language models (LLMs) have shown promise in language-related tasks, traditional fine-tuning approaches are often infeasible given the size of the models. In this paper, we propose a Parameter Efficient Fine tuning (PEFT) based solution for hate speech detection and target identification. We evaluate multiple LLMs on the Devanagari dataset provided by (Thapa et al., 2025), which contains annotated instances in 2 languages - Hindi and Nepali. The results demonstrate the efficacy of our approach in handling Devanagari-scripted content.
Overview of Factify5WQA: Fact Verification through 5W Question-Answering
Oct 05, 2024



Researchers have found that fake news spreads much times faster than real news. This is a major problem, especially in today's world where social media is the key source of news for many among the younger population. Fact verification, thus, becomes an important task and many media sites contribute to the cause. Manual fact verification is a tedious task, given the volume of fake news online. The Factify5WQA shared task aims to increase research towards automated fake news detection by providing a dataset with an aspect-based question answering based fact verification method. Each claim and its supporting document is associated with 5W questions that help compare the two information sources. The objective performance measure in the task is done by comparing answers using BLEU score to measure the accuracy of the answers, followed by an accuracy measure of the classification. The task had submissions using custom training setup and pre-trained language-models among others. The best performing team posted an accuracy of 69.56%, which is a near 35% improvement over the baseline.
Evidence-backed Fact Checking using RAG and Few-Shot In-Context Learning with LLMs
Aug 22, 2024

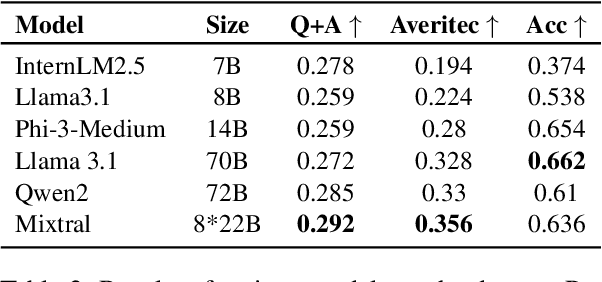
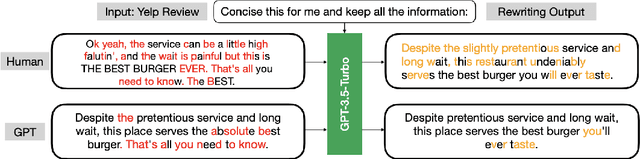
Given the widespread dissemination of misinformation on social media, implementing fact-checking mechanisms for online claims is essential. Manually verifying every claim is highly challenging, underscoring the need for an automated fact-checking system. This paper presents our system designed to address this issue. We utilize the Averitec dataset to assess the veracity of claims. In addition to veracity prediction, our system provides supporting evidence, which is extracted from the dataset. We develop a Retrieve and Generate (RAG) pipeline to extract relevant evidence sentences from a knowledge base, which are then inputted along with the claim into a large language model (LLM) for classification. We also evaluate the few-shot In-Context Learning (ICL) capabilities of multiple LLMs. Our system achieves an 'Averitec' score of 0.33, which is a 22% absolute improvement over the baseline. All code will be made available on All code will be made available on https://github.com/ronit-singhal/evidence-backed-fact-checking-using-rag-and-few-shot-in-context-learning-with-llms.
Enhancing Low-Resource LLMs Classification with PEFT and Synthetic Data
Apr 03, 2024Large Language Models (LLMs) operating in 0-shot or few-shot settings achieve competitive results in Text Classification tasks. In-Context Learning (ICL) typically achieves better accuracy than the 0-shot setting, but it pays in terms of efficiency, due to the longer input prompt. In this paper, we propose a strategy to make LLMs as efficient as 0-shot text classifiers, while getting comparable or better accuracy than ICL. Our solution targets the low resource setting, i.e., when only 4 examples per class are available. Using a single LLM and few-shot real data we perform a sequence of generation, filtering and Parameter-Efficient Fine-Tuning steps to create a robust and efficient classifier. Experimental results show that our approach leads to competitive results on multiple text classification datasets.
Improved Contextual Recognition In Automatic Speech Recognition Systems By Semantic Lattice Rescoring
Oct 27, 2023Automatic Speech Recognition (ASR) has witnessed a profound research interest. Recent breakthroughs have given ASR systems different prospects such as faithfully transcribing spoken language, which is a pivotal advancement in building conversational agents. However, there is still an imminent challenge of accurately discerning context-dependent words and phrases. In this work, we propose a novel approach for enhancing contextual recognition within ASR systems via semantic lattice processing leveraging the power of deep learning models in accurately delivering spot-on transcriptions across a wide variety of vocabularies and speaking styles. Our solution consists of using Hidden Markov Models and Gaussian Mixture Models (HMM-GMM) along with Deep Neural Networks (DNN) models integrating both language and acoustic modeling for better accuracy. We infused our network with the use of a transformer-based model to properly rescore the word lattice achieving remarkable capabilities with a palpable reduction in Word Error Rate (WER). We demonstrate the effectiveness of our proposed framework on the LibriSpeech dataset with empirical analyses.
Overview of Memotion 3: Sentiment and Emotion Analysis of Codemixed Hinglish Memes
Sep 12, 2023
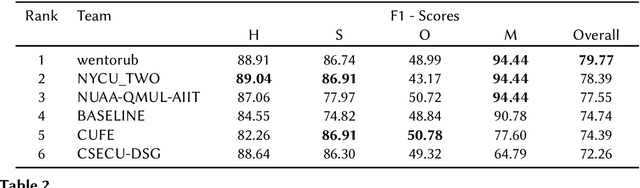

Analyzing memes on the internet has emerged as a crucial endeavor due to the impact this multi-modal form of content wields in shaping online discourse. Memes have become a powerful tool for expressing emotions and sentiments, possibly even spreading hate and misinformation, through humor and sarcasm. In this paper, we present the overview of the Memotion 3 shared task, as part of the DeFactify 2 workshop at AAAI-23. The task released an annotated dataset of Hindi-English code-mixed memes based on their Sentiment (Task A), Emotion (Task B), and Emotion intensity (Task C). Each of these is defined as an individual task and the participants are ranked separately for each task. Over 50 teams registered for the shared task and 5 made final submissions to the test set of the Memotion 3 dataset. CLIP, BERT modifications, ViT etc. were the most popular models among the participants along with approaches such as Student-Teacher model, Fusion, and Ensembling. The best final F1 score for Task A is 34.41, Task B is 79.77 and Task C is 59.82.
CONFLATOR: Incorporating Switching Point based Rotatory Positional Encodings for Code-Mixed Language Modeling
Sep 11, 2023



The mixing of two or more languages is called Code-Mixing (CM). CM is a social norm in multilingual societies. Neural Language Models (NLMs) like transformers have been very effective on many NLP tasks. However, NLM for CM is an under-explored area. Though transformers are capable and powerful, they cannot always encode positional/sequential information since they are non-recurrent. Therefore, to enrich word information and incorporate positional information, positional encoding is defined. We hypothesize that Switching Points (SPs), i.e., junctions in the text where the language switches (L1 -> L2 or L2-> L1), pose a challenge for CM Language Models (LMs), and hence give special emphasis to switching points in the modeling process. We experiment with several positional encoding mechanisms and show that rotatory positional encodings along with switching point information yield the best results. We introduce CONFLATOR: a neural language modeling approach for code-mixed languages. CONFLATOR tries to learn to emphasize switching points using smarter positional encoding, both at unigram and bigram levels. CONFLATOR outperforms the state-of-the-art on two tasks based on code-mixed Hindi and English (Hinglish): (i) sentiment analysis and (ii) machine translation.
Findings of Factify 2: Multimodal Fake News Detection
Jul 19, 2023With social media usage growing exponentially in the past few years, fake news has also become extremely prevalent. The detrimental impact of fake news emphasizes the need for research focused on automating the detection of false information and verifying its accuracy. In this work, we present the outcome of the Factify 2 shared task, which provides a multi-modal fact verification and satire news dataset, as part of the DeFactify 2 workshop at AAAI'23. The data calls for a comparison based approach to the task by pairing social media claims with supporting documents, with both text and image, divided into 5 classes based on multi-modal relations. In the second iteration of this task we had over 60 participants and 9 final test-set submissions. The best performances came from the use of DeBERTa for text and Swinv2 and CLIP for image. The highest F1 score averaged for all five classes was 81.82%.