 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Visually-Guided Movie Subtitle Translation for Indic Languages
May 12, 2026Movie subtitle translation is inherently multimodal, yet text-only systems often miss visual cues needed to convey emotion, action, and social nuance, especially for low-resource Indic languages (English to Hindi, Bengali, Telugu, Tamil and Kannada). We present a case study on five full-length films and compare two lightweight visual grounding strategies: structured attribute summaries from a 5-minute sliding window and free-text summaries of inter-subtitle visual gaps. Our analysis shows that temporal misalignment between subtitles and frames is a major obstacle in long-form video, often rendering indiscriminate visual grounding ineffective. However, oracle selective grounding, which replaces only the lowest-quality 20-30\% of baseline segments with visual-enhanced outputs, consistently improves COMET over the text-only baseline while requiring far less visual processing. Among the two approaches, coarse attribute-based visual context summarization is more robust, capturing scene-level emotion and contextual subtle cues that text alone often misses
Mind the Pause: Disfluency-Aware Objective Tuning for Multilingual Speech Correction with LLMs
May 12, 2026Automatic Speech Recognition (ASR) transcripts often contain disfluencies, such as fillers, repetitions, and false starts, which reduce readability and hinder downstream applications like chatbots and voice assistants. If left unaddressed, such disfluencies can significantly degrade the reliability of downstream systems. Most existing approaches rely on classical models that focus on identifying disfluent tokens for removal. While this strategy is effective to some extent, it often disrupts grammatical structure and semantic coherence, leading to incomplete or unnatural sentences. Recent literature explored the use of large language models (LLMs); however, these efforts have primarily focused on disfluency detection or data augmentation, rather than performing comprehensive correction. We propose a multilingual correction pipeline where a sequence tagger first marks disfluent tokens, and these signals guide instruction fine-tuning of an LLM to rewrite transcripts into fluent text. To further improve reliability, we add a contrastive learning objective that penalizes the reproduction of disfluent tokens, encouraging the model to preserve grammar and meaning while removing disfluent artifacts. Our experiments across three Indian languages, namely Hindi, Bengali, and Marathi show consistent improvements over strong baselines, including multilingual sequence-to-sequence models. These results highlight that detection-only strategies are insufficient. Combining token-level cues with instruction tuning and contrastive learning provides a practical and scalable solution for multilingual disfluency correction in speech-driven NLP systems. We make the codes publicly available at https://github.com/deepak-kumar-98/Mind-the-Pause.
When Reviews Disagree: Fine-Grained Contradiction Analysis in Scientific Peer Reviews
May 11, 2026Scientific peer reviews frequently contain conflicting expert judgments, and the increasing scale of conference submissions makes it challenging for Area Chairs and editors to reliably identify and interpret such disagreements. Existing approaches typically frame reviewer disagreement as binary contradiction detection over isolated sentence pairs, abstracting away the review-level context and obscuring differences in the severity of evaluative conflict. In this work, we introduce a fine-grained formulation of reviewer contradiction analysis that operates over full peer reviews by explicitly identifying contradiction evidence spans and assigning graded disagreement intensity scores. To support this task, we present RevCI, an expert-annotated benchmark of peer-review pairs with evidence-level contradiction annotations with graded intensity labels. We further propose IMPACT, a structured multi-agent framework that integrates aspect-conditioned evidence extraction, deliberative reasoning, and adjudication to model reviewer contradictions and their intensity. To support efficient deployment, we distill IMPACT into TIDE, a small language model that predicts contradiction evidence and intensity in a single forward pass. Experimental results show that IMPACT substantially outperforms strong single-agent and generic multi-agent baselines in both evidence identification and intensity agreement, while TIDE achieves competitive performance at significantly lower inference cost.
PRISMA: Preference-Reinforced Self-Training Approach for Interpretable Emotionally Intelligent Negotiation Dialogues
Apr 20, 2026Emotion plays a pivotal role in shaping negotiation outcomes, influencing trust, cooperation, and long-term relationships. Developing negotiation dialog systems that can recognize and respond strategically to emotions is, therefore, essential to create more effective human-centered interactions. Beyond generating emotionally appropriate responses, interpretability - understanding how a system generates a particular emotion-aware response, is critical for fostering reliability and building rapport. Driven by these aspects, in this work, we introduce PRISMA, an interpretable emotionally intelligent negotiation dialogue system targeting two application domains, viz. job interviews and resource allocation. To enable interpretability, we propose an Emotion-aware Negotiation Strategy-informed Chain-of-Thought (ENS-CoT) reasoning mechanism, which mimics human negotiation by perceiving, understanding, using, and managing emotions. Leveraging ENS-CoT, we curate two new datasets: JobNego (for job interview negotiation) and ResNego (for resource allocation negotiation). We then leverage these datasets to develop PRISMA by augmenting self-training with Direct Preference Optimization (DPO), guiding agents toward more accurate, interpretable, and emotionally appropriate negotiation responses. Automatic and human evaluation on JobNego and ResNego datasets demonstrate that PRISMA substantially enhances interpretability and generates appropriate emotion-aware responses, while improving overall negotiation effectiveness.
One Model to Translate Them All? A Journey to Mount Doom for Multilingual Model Merging
Apr 03, 2026Weight-space model merging combines independently fine-tuned models without accessing original training data, offering a practical alternative to joint training. While merging succeeds in multitask settings, its behavior in multilingual contexts remains poorly understood. We systematically study weight-space merging for multilingual machine translation by fully fine-tuning language model on large-scale bilingual corpora and evaluating standard merging strategies. Our experiments reveal that merging degrades performance, especially when target languages differ. To explain this failure, we analyze internal representations using span-conditioned neuron selectivity and layer-wise centered kernel alignment. We find that language-specific neurons concentrate in embedding layers and upper transformer blocks, while intermediate layers remain largely shared across languages. Critically, fine-tuning redistributes rather than sharpens language selectivity: neurons for supervised and related languages become less exclusive, while those for unsupervised languages grow more isolated. This redistribution increases representational divergence in higher layers that govern generation. These findings suggest that multilingual fine-tuning may reshape geometry in ways that reduce compatibility with standard weight-space merging assumptions. Our work thus provides an explanation for why merging fails in multilingual translation scenarios.
Sparse Semantic Dimension as a Generalization Certificate for LLMs
Feb 11, 2026Standard statistical learning theory predicts that Large Language Models (LLMs) should overfit because their parameter counts vastly exceed the number of training tokens. Yet, in practice, they generalize robustly. We propose that the effective capacity controlling generalization lies in the geometry of the model's internal representations: while the parameter space is high-dimensional, the activation states lie on a low-dimensional, sparse manifold. To formalize this, we introduce the Sparse Semantic Dimension (SSD), a complexity measure derived from the active feature vocabulary of a Sparse Autoencoder (SAE) trained on the model's layers. Treating the LLM and SAE as frozen oracles, we utilize this framework to attribute the model's generalization capabilities to the sparsity of the dictionary rather than the total parameter count. Empirically, we validate this framework on GPT-2 Small and Gemma-2B, demonstrating that our bound provides non-vacuous certificates at realistic sample sizes. Crucially, we uncover a counter-intuitive "feature sharpness" scaling law: despite being an order of magnitude larger, Gemma-2B requires significantly fewer calibration samples to identify its active manifold compared to GPT-2, suggesting that larger models learn more compressible, distinct semantic structures. Finally, we show that this framework functions as a reliable safety monitor: out-of-distribution inputs trigger a measurable "feature explosion" (a sharp spike in active features), effectively signaling epistemic uncertainty through learned feature violation. Code is available at: https://github.com/newcodevelop/sparse-semantic-dimension.
VideoChain: A Transformer-Based Framework for Multi-hop Video Question Generation
Nov 11, 2025Multi-hop Question Generation (QG) effectively evaluates reasoning but remains confined to text; Video Question Generation (VideoQG) is limited to zero-hop questions over single segments. To address this, we introduce VideoChain, a novel Multi-hop Video Question Generation (MVQG) framework designed to generate questions that require reasoning across multiple, temporally separated video segments. VideoChain features a modular architecture built on a modified BART backbone enhanced with video embeddings, capturing textual and visual dependencies. Using the TVQA+ dataset, we automatically construct the large-scale MVQ-60 dataset by merging zero-hop QA pairs, ensuring scalability and diversity. Evaluations show VideoChain's strong performance across standard generation metrics: ROUGE-L (0.6454), ROUGE-1 (0.6854), BLEU-1 (0.6711), BERTScore-F1 (0.7967), and semantic similarity (0.8110). These results highlight the model's ability to generate coherent, contextually grounded, and reasoning-intensive questions.
Beyond the Sentence: A Survey on Context-Aware Machine Translation with Large Language Models
Jun 09, 2025
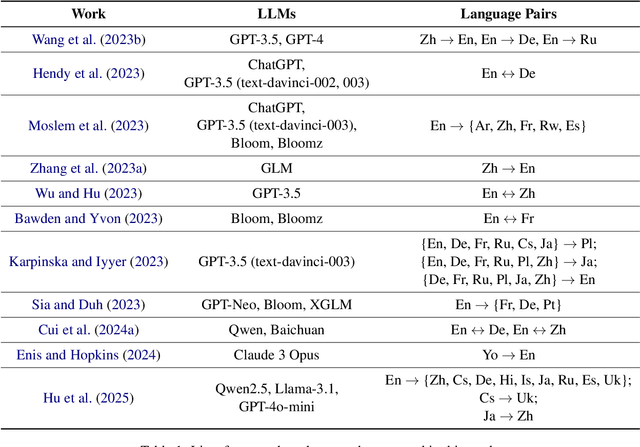
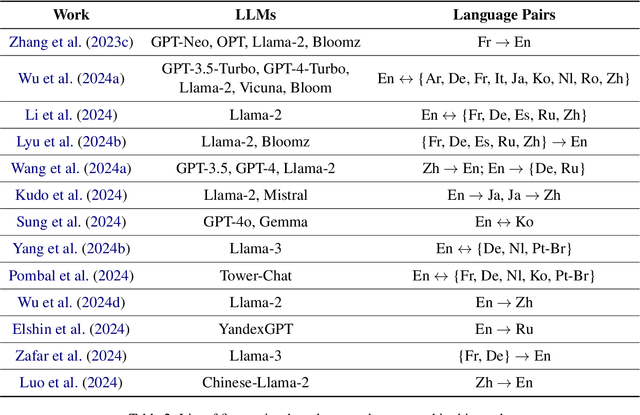
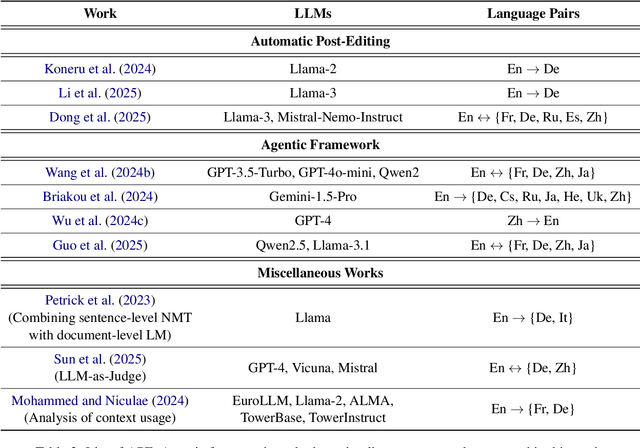
Despite the popularity of the large language models (LLMs), their application to machine translation is relatively underexplored, especially in context-aware settings. This work presents a literature review of context-aware translation with LLMs. The existing works utilise prompting and fine-tuning approaches, with few focusing on automatic post-editing and creating translation agents for context-aware machine translation. We observed that the commercial LLMs (such as ChatGPT and Tower LLM) achieved better results than the open-source LLMs (such as Llama and Bloom LLMs), and prompt-based approaches serve as good baselines to assess the quality of translations. Finally, we present some interesting future directions to explore.
Just a Scratch: Enhancing LLM Capabilities for Self-harm Detection through Intent Differentiation and Emoji Interpretation
Jun 05, 2025Self-harm detection on social media is critical for early intervention and mental health support, yet remains challenging due to the subtle, context-dependent nature of such expressions. Identifying self-harm intent aids suicide prevention by enabling timely responses, but current large language models (LLMs) struggle to interpret implicit cues in casual language and emojis. This work enhances LLMs' comprehension of self-harm by distinguishing intent through nuanced language-emoji interplay. We present the Centennial Emoji Sensitivity Matrix (CESM-100), a curated set of 100 emojis with contextual self-harm interpretations and the Self-Harm Identification aNd intent Extraction with Supportive emoji sensitivity (SHINES) dataset, offering detailed annotations for self-harm labels, casual mentions (CMs), and serious intents (SIs). Our unified framework: a) enriches inputs using CESM-100; b) fine-tunes LLMs for multi-task learning: self-harm detection (primary) and CM/SI span detection (auxiliary); c) generates explainable rationales for self-harm predictions. We evaluate the framework on three state-of-the-art LLMs-Llama 3, Mental-Alpaca, and MentalLlama, across zero-shot, few-shot, and fine-tuned scenarios. By coupling intent differentiation with contextual cues, our approach commendably enhances LLM performance in both detection and explanation tasks, effectively addressing the inherent ambiguity in self-harm signals. The SHINES dataset, CESM-100 and codebase are publicly available at: https://www.iitp.ac.in/~ai-nlp-ml/resources.html#SHINES .
Bridging the Linguistic Divide: A Survey on Leveraging Large Language Models for Machine Translation
Apr 03, 2025The advent of Large Language Models (LLMs) has significantly reshaped the landscape of machine translation (MT), particularly for low-resource languages and domains that lack sufficient parallel corpora, linguistic tools, and computational infrastructure. This survey presents a comprehensive overview of recent progress in leveraging LLMs for MT. We analyze techniques such as few-shot prompting, cross-lingual transfer, and parameter-efficient fine-tuning that enable effective adaptation to under-resourced settings. The paper also explores synthetic data generation strategies using LLMs, including back-translation and lexical augmentation. Additionally, we compare LLM-based translation with traditional encoder-decoder models across diverse language pairs, highlighting the strengths and limitations of each. We discuss persistent challenges such as hallucinations, evaluation inconsistencies, and inherited biases while also evaluating emerging LLM-driven metrics for translation quality. This survey offers practical insights and outlines future directions for building robust, inclusive, and scalable MT systems in the era of large-scale generative models.