 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMind the Pause: Disfluency-Aware Objective Tuning for Multilingual Speech Correction with LLMs
May 12, 2026Automatic Speech Recognition (ASR) transcripts often contain disfluencies, such as fillers, repetitions, and false starts, which reduce readability and hinder downstream applications like chatbots and voice assistants. If left unaddressed, such disfluencies can significantly degrade the reliability of downstream systems. Most existing approaches rely on classical models that focus on identifying disfluent tokens for removal. While this strategy is effective to some extent, it often disrupts grammatical structure and semantic coherence, leading to incomplete or unnatural sentences. Recent literature explored the use of large language models (LLMs); however, these efforts have primarily focused on disfluency detection or data augmentation, rather than performing comprehensive correction. We propose a multilingual correction pipeline where a sequence tagger first marks disfluent tokens, and these signals guide instruction fine-tuning of an LLM to rewrite transcripts into fluent text. To further improve reliability, we add a contrastive learning objective that penalizes the reproduction of disfluent tokens, encouraging the model to preserve grammar and meaning while removing disfluent artifacts. Our experiments across three Indian languages, namely Hindi, Bengali, and Marathi show consistent improvements over strong baselines, including multilingual sequence-to-sequence models. These results highlight that detection-only strategies are insufficient. Combining token-level cues with instruction tuning and contrastive learning provides a practical and scalable solution for multilingual disfluency correction in speech-driven NLP systems. We make the codes publicly available at https://github.com/deepak-kumar-98/Mind-the-Pause.
One Model to Translate Them All? A Journey to Mount Doom for Multilingual Model Merging
Apr 03, 2026Weight-space model merging combines independently fine-tuned models without accessing original training data, offering a practical alternative to joint training. While merging succeeds in multitask settings, its behavior in multilingual contexts remains poorly understood. We systematically study weight-space merging for multilingual machine translation by fully fine-tuning language model on large-scale bilingual corpora and evaluating standard merging strategies. Our experiments reveal that merging degrades performance, especially when target languages differ. To explain this failure, we analyze internal representations using span-conditioned neuron selectivity and layer-wise centered kernel alignment. We find that language-specific neurons concentrate in embedding layers and upper transformer blocks, while intermediate layers remain largely shared across languages. Critically, fine-tuning redistributes rather than sharpens language selectivity: neurons for supervised and related languages become less exclusive, while those for unsupervised languages grow more isolated. This redistribution increases representational divergence in higher layers that govern generation. These findings suggest that multilingual fine-tuning may reshape geometry in ways that reduce compatibility with standard weight-space merging assumptions. Our work thus provides an explanation for why merging fails in multilingual translation scenarios.
Beyond the Sentence: A Survey on Context-Aware Machine Translation with Large Language Models
Jun 09, 2025
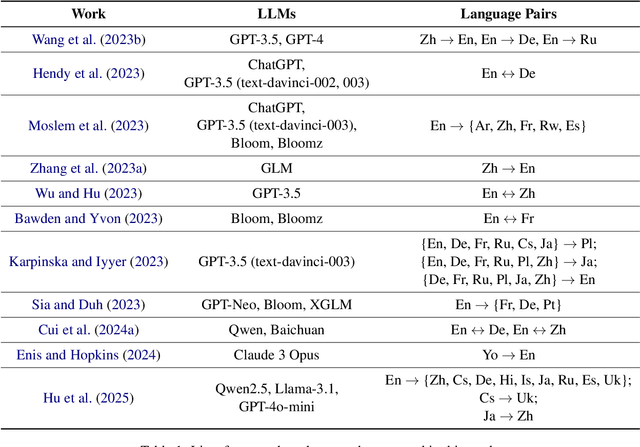
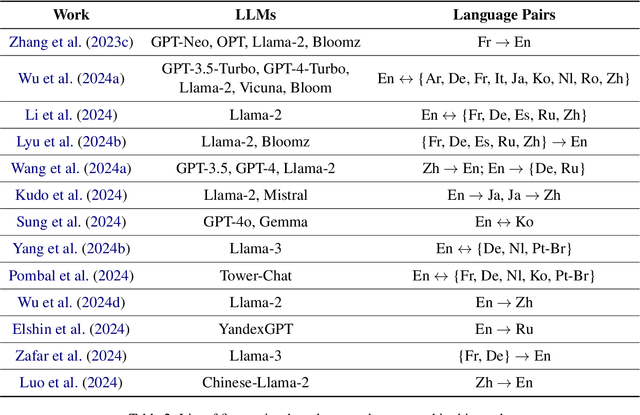
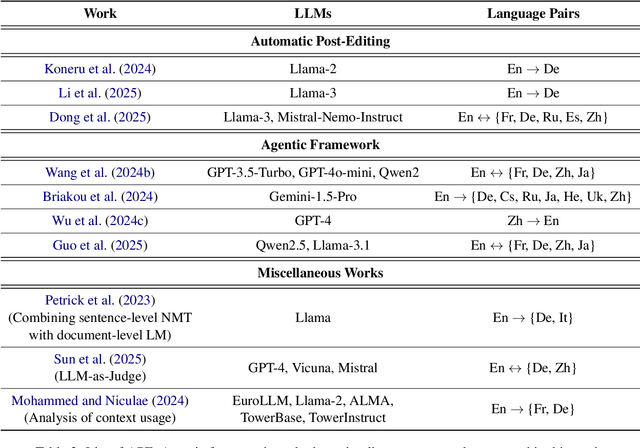
Despite the popularity of the large language models (LLMs), their application to machine translation is relatively underexplored, especially in context-aware settings. This work presents a literature review of context-aware translation with LLMs. The existing works utilise prompting and fine-tuning approaches, with few focusing on automatic post-editing and creating translation agents for context-aware machine translation. We observed that the commercial LLMs (such as ChatGPT and Tower LLM) achieved better results than the open-source LLMs (such as Llama and Bloom LLMs), and prompt-based approaches serve as good baselines to assess the quality of translations. Finally, we present some interesting future directions to explore.
Bridging the Linguistic Divide: A Survey on Leveraging Large Language Models for Machine Translation
Apr 03, 2025The advent of Large Language Models (LLMs) has significantly reshaped the landscape of machine translation (MT), particularly for low-resource languages and domains that lack sufficient parallel corpora, linguistic tools, and computational infrastructure. This survey presents a comprehensive overview of recent progress in leveraging LLMs for MT. We analyze techniques such as few-shot prompting, cross-lingual transfer, and parameter-efficient fine-tuning that enable effective adaptation to under-resourced settings. The paper also explores synthetic data generation strategies using LLMs, including back-translation and lexical augmentation. Additionally, we compare LLM-based translation with traditional encoder-decoder models across diverse language pairs, highlighting the strengths and limitations of each. We discuss persistent challenges such as hallucinations, evaluation inconsistencies, and inherited biases while also evaluating emerging LLM-driven metrics for translation quality. This survey offers practical insights and outlines future directions for building robust, inclusive, and scalable MT systems in the era of large-scale generative models.
Quality Estimation based Feedback Training for Improving Pronoun Translation
Jan 06, 2025



Pronoun translation is a longstanding challenge in neural machine translation (NMT), often requiring inter-sentential context to ensure linguistic accuracy. To address this, we introduce ProNMT, a novel framework designed to enhance pronoun and overall translation quality in context-aware machine translation systems. ProNMT leverages Quality Estimation (QE) models and a unique Pronoun Generation Likelihood-Based Feedback mechanism to iteratively fine-tune pre-trained NMT models without relying on extensive human annotations. The framework combines QE scores with pronoun-specific rewards to guide training, ensuring improved handling of linguistic nuances. Extensive experiments demonstrate significant gains in pronoun translation accuracy and general translation quality across multiple metrics. ProNMT offers an efficient, scalable, and context-aware approach to improving NMT systems, particularly in translating context-dependent elements like pronouns.
A Case Study on Context-Aware Neural Machine Translation with Multi-Task Learning
Jul 03, 2024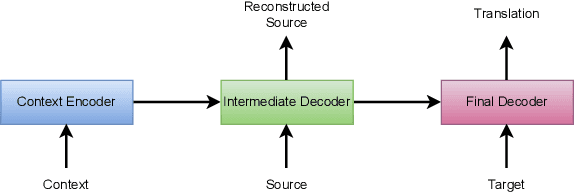
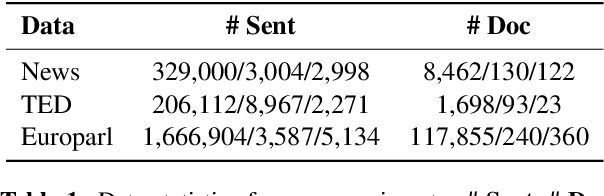
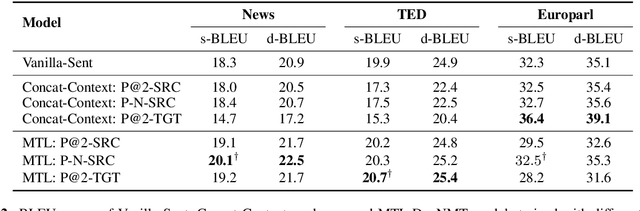
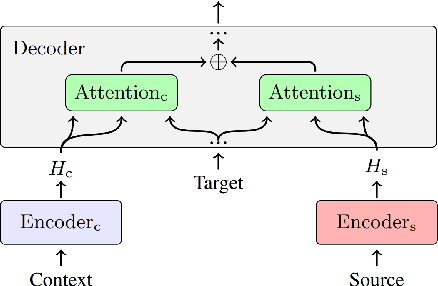
In document-level neural machine translation (DocNMT), multi-encoder approaches are common in encoding context and source sentences. Recent studies \cite{li-etal-2020-multi-encoder} have shown that the context encoder generates noise and makes the model robust to the choice of context. This paper further investigates this observation by explicitly modelling context encoding through multi-task learning (MTL) to make the model sensitive to the choice of context. We conduct experiments on cascade MTL architecture, which consists of one encoder and two decoders. Generation of the source from the context is considered an auxiliary task, and generation of the target from the source is the main task. We experimented with German--English language pairs on News, TED, and Europarl corpora. Evaluation results show that the proposed MTL approach performs better than concatenation-based and multi-encoder DocNMT models in low-resource settings and is sensitive to the choice of context. However, we observe that the MTL models are failing to generate the source from the context. These observations align with the previous studies, and this might suggest that the available document-level parallel corpora are not context-aware, and a robust sentence-level model can outperform the context-aware models.
Universal Adversarial Framework to Improve Adversarial Robustness for Diabetic Retinopathy Detection
Dec 13, 2023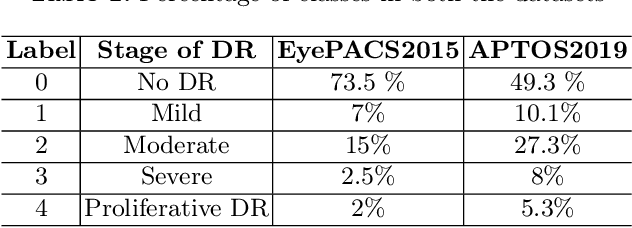
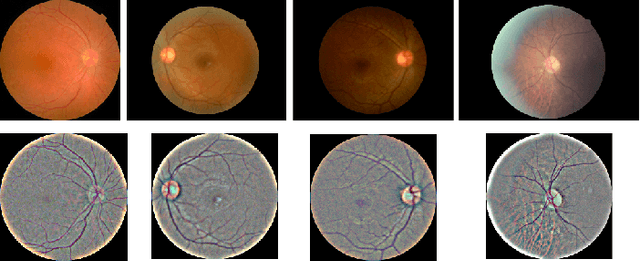
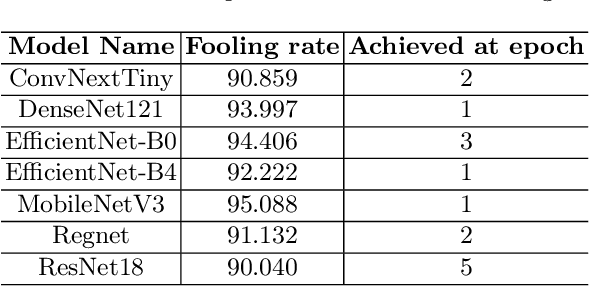
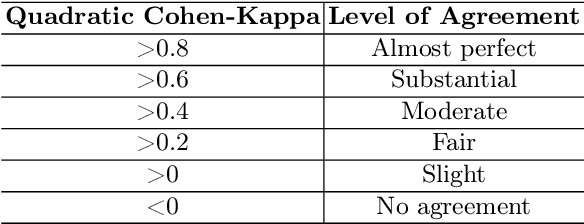
Diabetic Retinopathy (DR) is a prevalent illness associated with Diabetes which, if left untreated, can result in irreversible blindness. Deep Learning based systems are gradually being introduced as automated support for clinical diagnosis. Since healthcare has always been an extremely important domain demanding error-free performance, any adversaries could pose a big threat to the applicability of such systems. In this work, we use Universal Adversarial Perturbations (UAPs) to quantify the vulnerability of Medical Deep Neural Networks (DNNs) for detecting DR. To the best of our knowledge, this is the very first attempt that works on attacking complete fine-grained classification of DR images using various UAPs. Also, as a part of this work, we use UAPs to fine-tune the trained models to defend against adversarial samples. We experiment on several models and observe that the performance of such models towards unseen adversarial attacks gets boosted on average by $3.41$ Cohen-kappa value and maximum by $31.92$ Cohen-kappa value. The performance degradation on normal data upon ensembling the fine-tuned models was found to be statistically insignificant using t-test, highlighting the benefits of UAP-based adversarial fine-tuning.
Reference Free Domain Adaptation for Translation of Noisy Questions with Question Specific Rewards
Oct 23, 2023
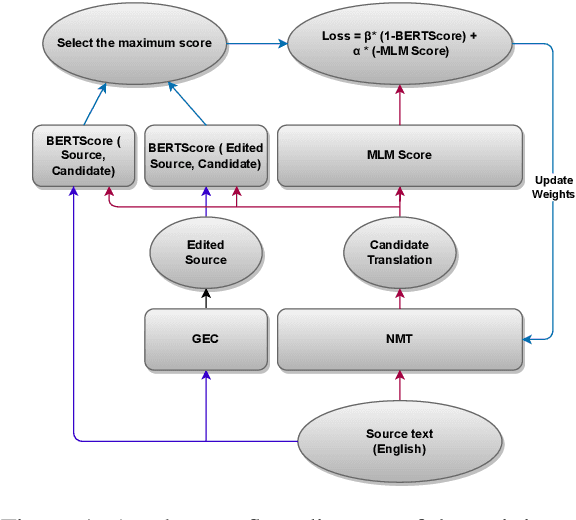


Community Question-Answering (CQA) portals serve as a valuable tool for helping users within an organization. However, making them accessible to non-English-speaking users continues to be a challenge. Translating questions can broaden the community's reach, benefiting individuals with similar inquiries in various languages. Translating questions using Neural Machine Translation (NMT) poses more challenges, especially in noisy environments, where the grammatical correctness of the questions is not monitored. These questions may be phrased as statements by non-native speakers, with incorrect subject-verb order and sometimes even missing question marks. Creating a synthetic parallel corpus from such data is also difficult due to its noisy nature. To address this issue, we propose a training methodology that fine-tunes the NMT system only using source-side data. Our approach balances adequacy and fluency by utilizing a loss function that combines BERTScore and Masked Language Model (MLM) Score. Our method surpasses the conventional Maximum Likelihood Estimation (MLE) based fine-tuning approach, which relies on synthetic target data, by achieving a 1.9 BLEU score improvement. Our model exhibits robustness while we add noise to our baseline, and still achieve 1.1 BLEU improvement and large improvements on TER and BLEURT metrics. Our proposed methodology is model-agnostic and is only necessary during the training phase. We make the codes and datasets publicly available at \url{https://www.iitp.ac.in/~ai-nlp-ml/resources.html#DomainAdapt} for facilitating further research.
Impact of Visual Context on Noisy Multimodal NMT: An Empirical Study for English to Indian Languages
Aug 30, 2023The study investigates the effectiveness of utilizing multimodal information in Neural Machine Translation (NMT). While prior research focused on using multimodal data in low-resource scenarios, this study examines how image features impact translation when added to a large-scale, pre-trained unimodal NMT system. Surprisingly, the study finds that images might be redundant in this context. Additionally, the research introduces synthetic noise to assess whether images help the model deal with textual noise. Multimodal models slightly outperform text-only models in noisy settings, even with random images. The study's experiments translate from English to Hindi, Bengali, and Malayalam, outperforming state-of-the-art benchmarks significantly. Interestingly, the effect of visual context varies with source text noise: no visual context works best for non-noisy translations, cropped image features are optimal for low noise, and full image features work better in high-noise scenarios. This sheds light on the role of visual context, especially in noisy settings, opening up a new research direction for Noisy Neural Machine Translation in multimodal setups. The research emphasizes the importance of combining visual and textual information for improved translation in various environments.
A Case Study on Context Encoding in Multi-Encoder based Document-Level Neural Machine Translation
Aug 11, 2023



Recent studies have shown that the multi-encoder models are agnostic to the choice of context, and the context encoder generates noise which helps improve the models in terms of BLEU score. In this paper, we further explore this idea by evaluating with context-aware pronoun translation test set by training multi-encoder models trained on three different context settings viz, previous two sentences, random two sentences, and a mix of both as context. Specifically, we evaluate the models on the ContraPro test set to study how different contexts affect pronoun translation accuracy. The results show that the model can perform well on the ContraPro test set even when the context is random. We also analyze the source representations to study whether the context encoder generates noise. Our analysis shows that the context encoder provides sufficient information to learn discourse-level information. Additionally, we observe that mixing the selected context (the previous two sentences in this case) and the random context is generally better than the other settings.