 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Teacher Is Worth A Million Instructions
Jun 27, 2024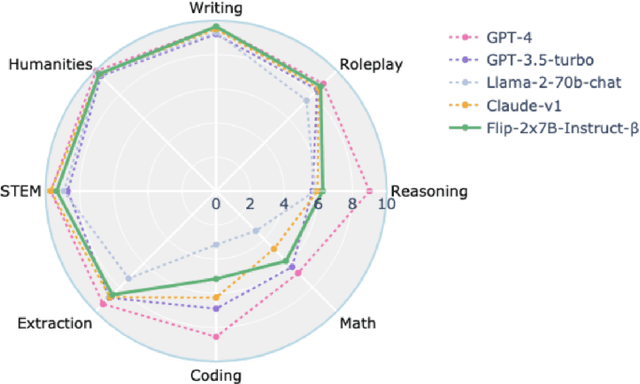
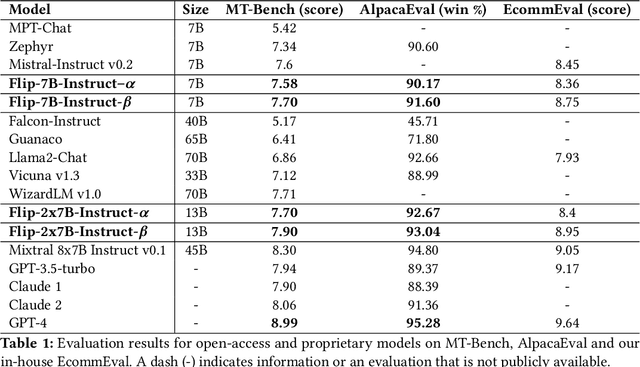
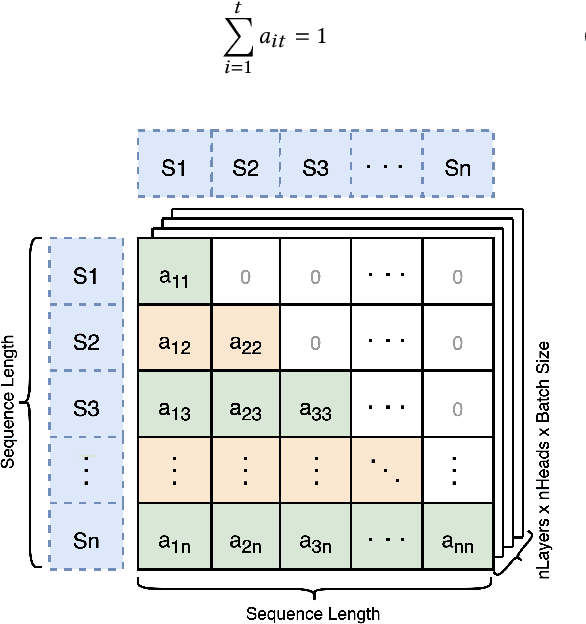
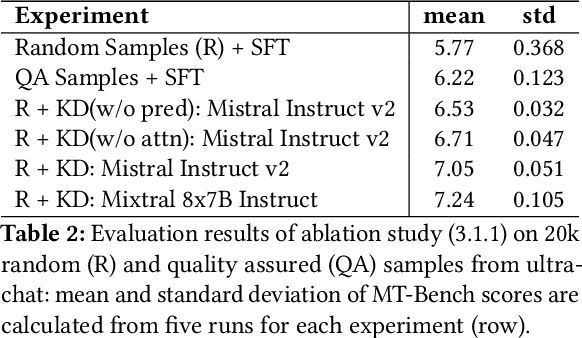
Large Language Models(LLMs) have shown exceptional abilities, yet training these models can be quite challenging. There is a strong dependence on the quality of data and finding the best instruction tuning set. Further, the inherent limitations in training methods create substantial difficulties to train relatively smaller models with 7B and 13B parameters. In our research, we suggest an improved training method for these models by utilising knowledge from larger models, such as a mixture of experts (8x7B) architectures. The scale of these larger models allows them to capture a wide range of variations from data alone, making them effective teachers for smaller models. Moreover, we implement a novel post-training domain alignment phase that employs domain-specific expert models to boost domain-specific knowledge during training while preserving the model's ability to generalise. Fine-tuning Mistral 7B and 2x7B with our method surpasses the performance of state-of-the-art language models with more than 7B and 13B parameters: achieving up to $7.9$ in MT-Bench and $93.04\%$ on AlpacaEval.
Distilling Opinions at Scale: Incremental Opinion Summarization using XL-OPSUMM
Jun 16, 2024



Opinion summarization in e-commerce encapsulates the collective views of numerous users about a product based on their reviews. Typically, a product on an e-commerce platform has thousands of reviews, each review comprising around 10-15 words. While Large Language Models (LLMs) have shown proficiency in summarization tasks, they struggle to handle such a large volume of reviews due to context limitations. To mitigate, we propose a scalable framework called Xl-OpSumm that generates summaries incrementally. However, the existing test set, AMASUM has only 560 reviews per product on average. Due to the lack of a test set with thousands of reviews, we created a new test set called Xl-Flipkart by gathering data from the Flipkart website and generating summaries using GPT-4. Through various automatic evaluations and extensive analysis, we evaluated the framework's efficiency on two datasets, AMASUM and Xl-Flipkart. Experimental results show that our framework, Xl-OpSumm powered by Llama-3-8B-8k, achieves an average ROUGE-1 F1 gain of 4.38% and a ROUGE-L F1 gain of 3.70% over the next best-performing model.
Product Description and QA Assisted Self-Supervised Opinion Summarization
Apr 08, 2024



In e-commerce, opinion summarization is the process of summarizing the consensus opinions found in product reviews. However, the potential of additional sources such as product description and question-answers (QA) has been considered less often. Moreover, the absence of any supervised training data makes this task challenging. To address this, we propose a novel synthetic dataset creation (SDC) strategy that leverages information from reviews as well as additional sources for selecting one of the reviews as a pseudo-summary to enable supervised training. Our Multi-Encoder Decoder framework for Opinion Summarization (MEDOS) employs a separate encoder for each source, enabling effective selection of information while generating the summary. For evaluation, due to the unavailability of test sets with additional sources, we extend the Amazon, Oposum+, and Flipkart test sets and leverage ChatGPT to annotate summaries. Experiments across nine test sets demonstrate that the combination of our SDC approach and MEDOS model achieves on average a 14.5% improvement in ROUGE-1 F1 over the SOTA. Moreover, comparative analysis underlines the significance of incorporating additional sources for generating more informative summaries. Human evaluations further indicate that MEDOS scores relatively higher in coherence and fluency with 0.41 and 0.5 (-1 to 1) respectively, compared to existing models. To the best of our knowledge, we are the first to generate opinion summaries leveraging additional sources in a self-supervised setting.
Leveraging Domain Knowledge for Efficient Reward Modelling in RLHF: A Case-Study in E-Commerce Opinion Summarization
Feb 23, 2024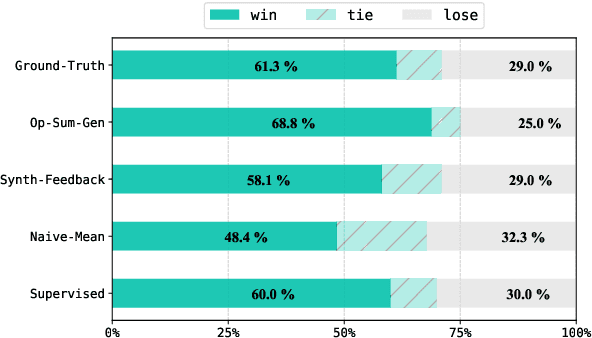



Reinforcement Learning from Human Feedback (RLHF) has become a dominating strategy in steering Language Models (LMs) towards human values/goals. The key to the strategy is employing a reward model ({$\varphi$}) which can reflect a latent reward model with humans. While this strategy has proven to be effective, the training methodology requires a lot of human preference annotation (usually of the order of tens of thousands) to train {$\varphi$}. Such large-scale preference annotations can be achievable if the reward model can be ubiquitously used. However, human values/goals are subjective and depend on the nature of the task. This poses a challenge in collecting diverse preferences for downstream applications. To address this, we propose a novel methodology to infuse domain knowledge into {$\varphi$}, which reduces the size of preference annotation required. We validate our approach in E-Commerce Opinion Summarization, with a significant reduction in dataset size (just $940$ samples) while advancing the state-of-the-art. Our contributions include a novel Reward Modelling technique, a new dataset (PromptOpinSumm) for Opinion Summarization, and a human preference dataset (OpinPref). The proposed methodology opens avenues for efficient RLHF, making it more adaptable to diverse applications with varying human values. We release the artifacts for usage under MIT License.
One Prompt To Rule Them All: LLMs for Opinion Summary Evaluation
Feb 18, 2024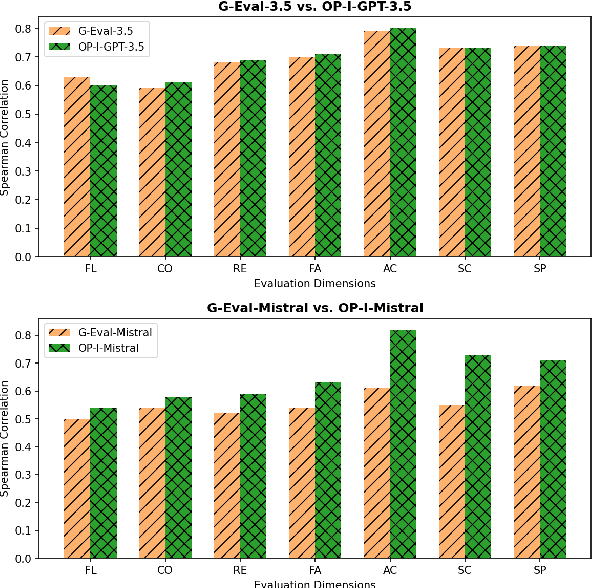



Evaluation of opinion summaries using conventional reference-based metrics rarely provides a holistic evaluation and has been shown to have a relatively low correlation with human judgments. Recent studies suggest using Large Language Models (LLMs) as reference-free metrics for NLG evaluation, however, they remain unexplored for opinion summary evaluation. Moreover, limited opinion summary evaluation datasets inhibit progress. To address this, we release the SUMMEVAL-OP dataset covering 7 dimensions related to the evaluation of opinion summaries: fluency, coherence, relevance, faithfulness, aspect coverage, sentiment consistency, and specificity. We investigate Op-I-Prompt a dimension-independent prompt, and Op-Prompts, a dimension-dependent set of prompts for opinion summary evaluation. Experiments indicate that Op-I-Prompt emerges as a good alternative for evaluating opinion summaries achieving an average Spearman correlation of 0.70 with humans, outperforming all previous approaches. To the best of our knowledge, we are the first to investigate LLMs as evaluators on both closed-source and open-source models in the opinion summarization domain.
Code-Mixed Text to Speech Synthesis under Low-Resource Constraints
Dec 02, 2023Text-to-speech (TTS) systems are an important component in voice-based e-commerce applications. These applications include end-to-end voice assistant and customer experience (CX) voice bot. Code-mixed TTS is also relevant in these applications since the product names are commonly described in English while the surrounding text is in a regional language. In this work, we describe our approaches for production quality code-mixed Hindi-English TTS systems built for e-commerce applications. We propose a data-oriented approach by utilizing monolingual data sets in individual languages. We leverage a transliteration model to convert the Roman text into a common Devanagari script and then combine both datasets for training. We show that such single script bi-lingual training without any code-mixing works well for pure code-mixed test sets. We further present an exhaustive evaluation of single-speaker adaptation and multi-speaker training with Tacotron2 + Waveglow setup to show that the former approach works better. These approaches are also coupled with transfer learning and decoder-only fine-tuning to improve performance. We compare these approaches with the Google TTS and report a positive CMOS score of 0.02 with the proposed transfer learning approach. We also perform low-resource voice adaptation experiments to show that a new voice can be onboarded with just 3 hrs of data. This highlights the importance of our pre-trained models in resource-constrained settings. This subjective evaluation is performed on a large number of out-of-domain pure code-mixed sentences to demonstrate the high quality of the systems.
Rapid Speaker Adaptation in Low Resource Text to Speech Systems using Synthetic Data and Transfer learning
Dec 02, 2023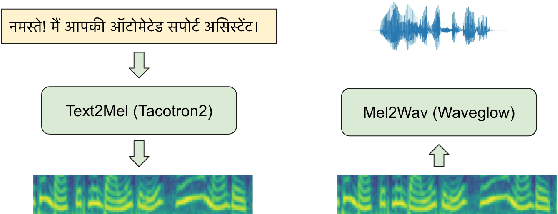

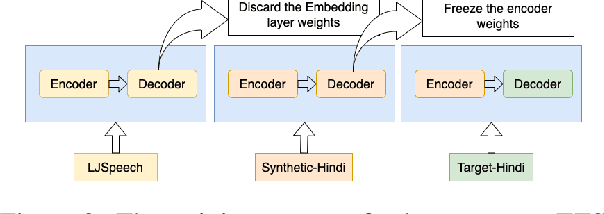
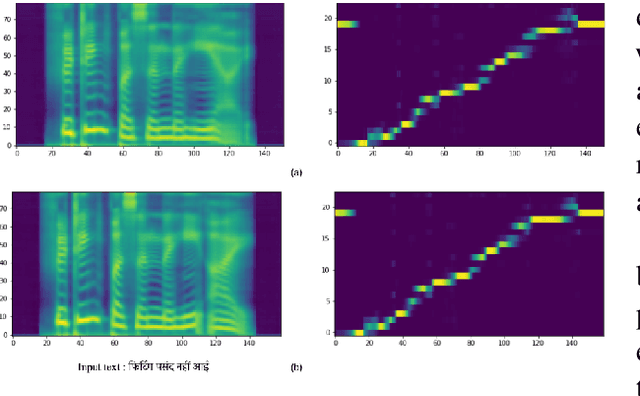
Text-to-speech (TTS) systems are being built using end-to-end deep learning approaches. However, these systems require huge amounts of training data. We present our approach to built production quality TTS and perform speaker adaptation in extremely low resource settings. We propose a transfer learning approach using high-resource language data and synthetically generated data. We transfer the learnings from the out-domain high-resource English language. Further, we make use of out-of-the-box single-speaker TTS in the target language to generate in-domain synthetic data. We employ a three-step approach to train a high-quality single-speaker TTS system in a low-resource Indian language Hindi. We use a Tacotron2 like setup with a spectrogram prediction network and a waveglow vocoder. The Tacotron2 acoustic model is trained on English data, followed by synthetic Hindi data from the existing TTS system. Finally, the decoder of this model is fine-tuned on only 3 hours of target Hindi speaker data to enable rapid speaker adaptation. We show the importance of this dual pre-training and decoder-only fine-tuning using subjective MOS evaluation. Using transfer learning from high-resource language and synthetic corpus we present a low-cost solution to train a custom TTS model.
Reference Free Domain Adaptation for Translation of Noisy Questions with Question Specific Rewards
Oct 23, 2023
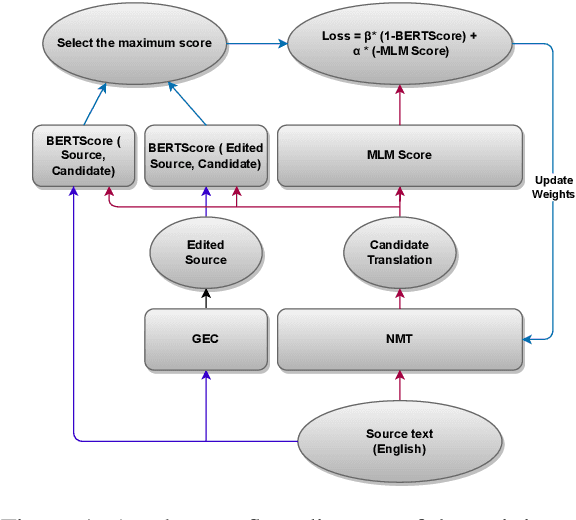


Community Question-Answering (CQA) portals serve as a valuable tool for helping users within an organization. However, making them accessible to non-English-speaking users continues to be a challenge. Translating questions can broaden the community's reach, benefiting individuals with similar inquiries in various languages. Translating questions using Neural Machine Translation (NMT) poses more challenges, especially in noisy environments, where the grammatical correctness of the questions is not monitored. These questions may be phrased as statements by non-native speakers, with incorrect subject-verb order and sometimes even missing question marks. Creating a synthetic parallel corpus from such data is also difficult due to its noisy nature. To address this issue, we propose a training methodology that fine-tunes the NMT system only using source-side data. Our approach balances adequacy and fluency by utilizing a loss function that combines BERTScore and Masked Language Model (MLM) Score. Our method surpasses the conventional Maximum Likelihood Estimation (MLE) based fine-tuning approach, which relies on synthetic target data, by achieving a 1.9 BLEU score improvement. Our model exhibits robustness while we add noise to our baseline, and still achieve 1.1 BLEU improvement and large improvements on TER and BLEURT metrics. Our proposed methodology is model-agnostic and is only necessary during the training phase. We make the codes and datasets publicly available at \url{https://www.iitp.ac.in/~ai-nlp-ml/resources.html#DomainAdapt} for facilitating further research.
Building Accurate Low Latency ASR for Streaming Voice Search
May 29, 2023Automatic Speech Recognition (ASR) plays a crucial role in voice-based applications. For applications requiring real-time feedback like Voice Search, streaming capability becomes vital. While LSTM/RNN and CTC based ASR systems are commonly employed for low-latency streaming applications, they often exhibit lower accuracy compared to state-of-the-art models due to a lack of future audio frames. In this work, we focus on developing accurate LSTM, attention, and CTC based streaming ASR models for large-scale Hinglish (a blend of Hindi and English) Voice Search. We investigate various modifications in vanilla LSTM training which enhance the system's accuracy while preserving its streaming capabilities. We also address the critical requirement of end-of-speech (EOS) detection in streaming applications. We present a simple training and inference strategy for end-to-end CTC models that enables joint ASR and EOS detection. The evaluation of our model on Flipkart's Voice Search, which handles substantial traffic of approximately 6 million queries per day, demonstrates significant performance gains over the vanilla LSTM-CTC model. Our model achieves a word error rate (WER) of 3.69% without EOS and 4.78% with EOS while also reducing the search latency by approximately ~1300 ms (equivalent to 46.64% reduction) when compared to an independent voice activity detection (VAD) model.
End-to-End Speech to Intent Prediction to improve E-commerce Customer Support Voicebot in Hindi and English
Oct 26, 2022Automation of on-call customer support relies heavily on accurate and efficient speech-to-intent (S2I) systems. Building such systems using multi-component pipelines can pose various challenges because they require large annotated datasets, have higher latency, and have complex deployment. These pipelines are also prone to compounding errors. To overcome these challenges, we discuss an end-to-end (E2E) S2I model for customer support voicebot task in a bilingual setting. We show how we can solve E2E intent classification by leveraging a pre-trained automatic speech recognition (ASR) model with slight modification and fine-tuning on small annotated datasets. Experimental results show that our best E2E model outperforms a conventional pipeline by a relative ~27% on the F1 score.