 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRapid Speaker Adaptation in Low Resource Text to Speech Systems using Synthetic Data and Transfer learning
Paper and Code
Dec 02, 2023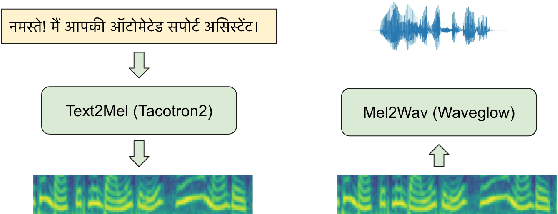

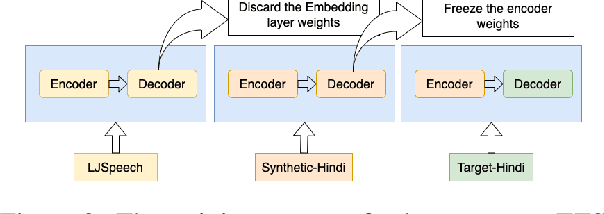
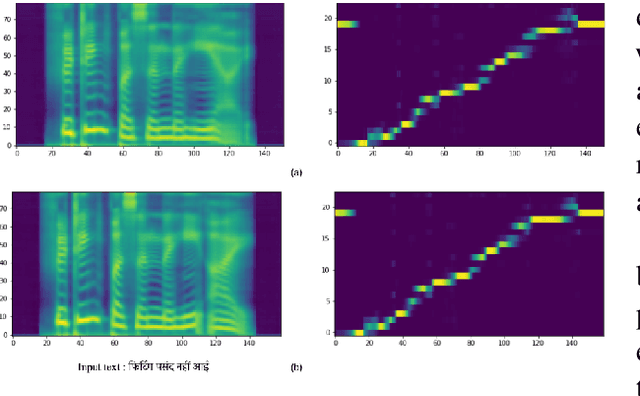
Text-to-speech (TTS) systems are being built using end-to-end deep learning approaches. However, these systems require huge amounts of training data. We present our approach to built production quality TTS and perform speaker adaptation in extremely low resource settings. We propose a transfer learning approach using high-resource language data and synthetically generated data. We transfer the learnings from the out-domain high-resource English language. Further, we make use of out-of-the-box single-speaker TTS in the target language to generate in-domain synthetic data. We employ a three-step approach to train a high-quality single-speaker TTS system in a low-resource Indian language Hindi. We use a Tacotron2 like setup with a spectrogram prediction network and a waveglow vocoder. The Tacotron2 acoustic model is trained on English data, followed by synthetic Hindi data from the existing TTS system. Finally, the decoder of this model is fine-tuned on only 3 hours of target Hindi speaker data to enable rapid speaker adaptation. We show the importance of this dual pre-training and decoder-only fine-tuning using subjective MOS evaluation. Using transfer learning from high-resource language and synthetic corpus we present a low-cost solution to train a custom TTS model.