 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFiMI: A Domain-Specific Language Model for Indian Finance Ecosystem
Feb 05, 2026We present FiMI (Finance Model for India), a domain-specialized financial language model developed for Indian digital payment systems. We develop two model variants: FiMI Base and FiMI Instruct. FiMI adapts the Mistral Small 24B architecture through a multi-stage training pipeline, beginning with continuous pre-training on 68 Billion tokens of curated financial, multilingual (English, Hindi, Hinglish), and synthetic data. This is followed by instruction fine-tuning and domain-specific supervised fine-tuning focused on multi-turn, tool-driven conversations that model real-world workflows, such as transaction disputes and mandate lifecycle management. Evaluations reveal that FiMI Base achieves a 20% improvement over the Mistral Small 24B Base model on finance reasoning benchmark, while FiMI Instruct outperforms the Mistral Small 24B Instruct model by 87% on domain-specific tool-calling. Moreover, FiMI achieves these significant domain gains while maintaining comparable performance to models of similar size on general benchmarks.
L3Cube-MahaSTS: A Marathi Sentence Similarity Dataset and Models
Aug 29, 2025



We present MahaSTS, a human-annotated Sentence Textual Similarity (STS) dataset for Marathi, along with MahaSBERT-STS-v2, a fine-tuned Sentence-BERT model optimized for regression-based similarity scoring. The MahaSTS dataset consists of 16,860 Marathi sentence pairs labeled with continuous similarity scores in the range of 0-5. To ensure balanced supervision, the dataset is uniformly distributed across six score-based buckets spanning the full 0-5 range, thus reducing label bias and enhancing model stability. We fine-tune the MahaSBERT model on this dataset and benchmark its performance against other alternatives like MahaBERT, MuRIL, IndicBERT, and IndicSBERT. Our experiments demonstrate that MahaSTS enables effective training for sentence similarity tasks in Marathi, highlighting the impact of human-curated annotations, targeted fine-tuning, and structured supervision in low-resource settings. The dataset and model are publicly shared at https://github.com/l3cube-pune/MarathiNLP
Benchmarking Hindi LLMs: A New Suite of Datasets and a Comparative Analysis
Aug 27, 2025



Evaluating instruction-tuned Large Language Models (LLMs) in Hindi is challenging due to a lack of high-quality benchmarks, as direct translation of English datasets fails to capture crucial linguistic and cultural nuances. To address this, we introduce a suite of five Hindi LLM evaluation datasets: IFEval-Hi, MT-Bench-Hi, GSM8K-Hi, ChatRAG-Hi, and BFCL-Hi. These were created using a methodology that combines from-scratch human annotation with a translate-and-verify process. We leverage this suite to conduct an extensive benchmarking of open-source LLMs supporting Hindi, providing a detailed comparative analysis of their current capabilities. Our curation process also serves as a replicable methodology for developing benchmarks in other low-resource languages.
Efficient Zero-Shot Long Document Classification by Reducing Context Through Sentence Ranking
Aug 24, 2025



Transformer-based models like BERT excel at short text classification but struggle with long document classification (LDC) due to input length limitations and computational inefficiencies. In this work, we propose an efficient, zero-shot approach to LDC that leverages sentence ranking to reduce input context without altering the model architecture. Our method enables the adaptation of models trained on short texts, such as headlines, to long-form documents by selecting the most informative sentences using a TF-IDF-based ranking strategy. Using the MahaNews dataset of long Marathi news articles, we evaluate three context reduction strategies that prioritize essential content while preserving classification accuracy. Our results show that retaining only the top 50\% ranked sentences maintains performance comparable to full-document inference while reducing inference time by up to 35\%. This demonstrates that sentence ranking is a simple yet effective technique for scalable and efficient zero-shot LDC.
MahaParaphrase: A Marathi Paraphrase Detection Corpus and BERT-based Models
Aug 24, 2025



Paraphrases are a vital tool to assist language understanding tasks such as question answering, style transfer, semantic parsing, and data augmentation tasks. Indic languages are complex in natural language processing (NLP) due to their rich morphological and syntactic variations, diverse scripts, and limited availability of annotated data. In this work, we present the L3Cube-MahaParaphrase Dataset, a high-quality paraphrase corpus for Marathi, a low resource Indic language, consisting of 8,000 sentence pairs, each annotated by human experts as either Paraphrase (P) or Non-paraphrase (NP). We also present the results of standard transformer-based BERT models on these datasets. The dataset and model are publicly shared at https://github.com/l3cube-pune/MarathiNLP
Improving the Efficiency of Long Document Classification using Sentence Ranking Approach
Jun 08, 2025



Long document classification poses challenges due to the computational limitations of transformer-based models, particularly BERT, which are constrained by fixed input lengths and quadratic attention complexity. Moreover, using the full document for classification is often redundant, as only a subset of sentences typically carries the necessary information. To address this, we propose a TF-IDF-based sentence ranking method that improves efficiency by selecting the most informative content. Our approach explores fixed-count and percentage-based sentence selection, along with an enhanced scoring strategy combining normalized TF-IDF scores and sentence length. Evaluated on the MahaNews LDC dataset of long Marathi news articles, the method consistently outperforms baselines such as first, last, and random sentence selection. With MahaBERT-v2, we achieve near-identical classification accuracy with just a 0.33 percent drop compared to the full-context baseline, while reducing input size by over 50 percent and inference latency by 43 percent. This demonstrates that significant context reduction is possible without sacrificing performance, making the method practical for real-world long document classification tasks.
IndicSQuAD: A Comprehensive Multilingual Question Answering Dataset for Indic Languages
May 06, 2025

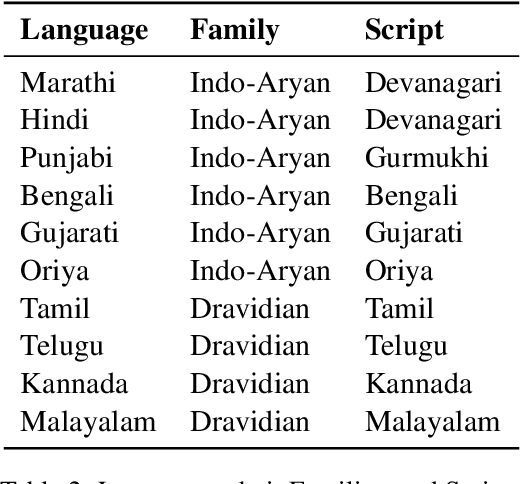

The rapid progress in question-answering (QA) systems has predominantly benefited high-resource languages, leaving Indic languages largely underrepresented despite their vast native speaker base. In this paper, we present IndicSQuAD, a comprehensive multi-lingual extractive QA dataset covering nine major Indic languages, systematically derived from the SQuAD dataset. Building on previous work with MahaSQuAD for Marathi, our approach adapts and extends translation techniques to maintain high linguistic fidelity and accurate answer-span alignment across diverse languages. IndicSQuAD comprises extensive training, validation, and test sets for each language, providing a robust foundation for model development. We evaluate baseline performances using language-specific monolingual BERT models and the multilingual MuRIL-BERT. The results indicate some challenges inherent in low-resource settings. Moreover, our experiments suggest potential directions for future work, including expanding to additional languages, developing domain-specific datasets, and incorporating multimodal data. The dataset and models are publicly shared at https://github.com/l3cube-pune/indic-nlp
Better To Ask in English? Evaluating Factual Accuracy of Multilingual LLMs in English and Low-Resource Languages
Apr 28, 2025



Multilingual Large Language Models (LLMs) have demonstrated significant effectiveness across various languages, particularly in high-resource languages such as English. However, their performance in terms of factual accuracy across other low-resource languages, especially Indic languages, remains an area of investigation. In this study, we assess the factual accuracy of LLMs - GPT-4o, Gemma-2-9B, Gemma-2-2B, and Llama-3.1-8B - by comparing their performance in English and Indic languages using the IndicQuest dataset, which contains question-answer pairs in English and 19 Indic languages. By asking the same questions in English and their respective Indic translations, we analyze whether the models are more reliable for regional context questions in Indic languages or when operating in English. Our findings reveal that LLMs often perform better in English, even for questions rooted in Indic contexts. Notably, we observe a higher tendency for hallucination in responses generated in low-resource Indic languages, highlighting challenges in the multilingual understanding capabilities of current LLMs.
Efficient Hybrid Language Model Compression through Group-Aware SSM Pruning
Apr 15, 2025Hybrid LLM architectures that combine Attention and State Space Models (SSMs) achieve state-of-the-art accuracy and runtime performance. Recent work has demonstrated that applying compression and distillation to Attention-only models yields smaller, more accurate models at a fraction of the training cost. In this work, we explore the effectiveness of compressing Hybrid architectures. We introduce a novel group-aware pruning strategy that preserves the structural integrity of SSM blocks and their sequence modeling capabilities. Furthermore, we demonstrate the necessity of such SSM pruning to achieve improved accuracy and inference speed compared to traditional approaches. Our compression recipe combines SSM, FFN, embedding dimension, and layer pruning, followed by knowledge distillation-based retraining, similar to the MINITRON technique. Using this approach, we compress the Nemotron-H 8B Hybrid model down to 4B parameters with up to 40x fewer training tokens. The resulting model surpasses the accuracy of similarly-sized models while achieving 2x faster inference, significantly advancing the Pareto frontier.
Nemotron-H: A Family of Accurate and Efficient Hybrid Mamba-Transformer Models
Apr 10, 2025



As inference-time scaling becomes critical for enhanced reasoning capabilities, it is increasingly becoming important to build models that are efficient to infer. We introduce Nemotron-H, a family of 8B and 56B/47B hybrid Mamba-Transformer models designed to reduce inference cost for a given accuracy level. To achieve this goal, we replace the majority of self-attention layers in the common Transformer model architecture with Mamba layers that perform constant computation and require constant memory per generated token. We show that Nemotron-H models offer either better or on-par accuracy compared to other similarly-sized state-of-the-art open-sourced Transformer models (e.g., Qwen-2.5-7B/72B and Llama-3.1-8B/70B), while being up to 3$\times$ faster at inference. To further increase inference speed and reduce the memory required at inference time, we created Nemotron-H-47B-Base from the 56B model using a new compression via pruning and distillation technique called MiniPuzzle. Nemotron-H-47B-Base achieves similar accuracy to the 56B model, but is 20% faster to infer. In addition, we introduce an FP8-based training recipe and show that it can achieve on par results with BF16-based training. This recipe is used to train the 56B model. All Nemotron-H models will be released, with support in Hugging Face, NeMo, and Megatron-LM.