 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBetter To Ask in English? Evaluating Factual Accuracy of Multilingual LLMs in English and Low-Resource Languages
Apr 28, 2025



Multilingual Large Language Models (LLMs) have demonstrated significant effectiveness across various languages, particularly in high-resource languages such as English. However, their performance in terms of factual accuracy across other low-resource languages, especially Indic languages, remains an area of investigation. In this study, we assess the factual accuracy of LLMs - GPT-4o, Gemma-2-9B, Gemma-2-2B, and Llama-3.1-8B - by comparing their performance in English and Indic languages using the IndicQuest dataset, which contains question-answer pairs in English and 19 Indic languages. By asking the same questions in English and their respective Indic translations, we analyze whether the models are more reliable for regional context questions in Indic languages or when operating in English. Our findings reveal that LLMs often perform better in English, even for questions rooted in Indic contexts. Notably, we observe a higher tendency for hallucination in responses generated in low-resource Indic languages, highlighting challenges in the multilingual understanding capabilities of current LLMs.
L3Cube-IndicQuest: A Benchmark Questing Answering Dataset for Evaluating Knowledge of LLMs in Indic Context
Sep 13, 2024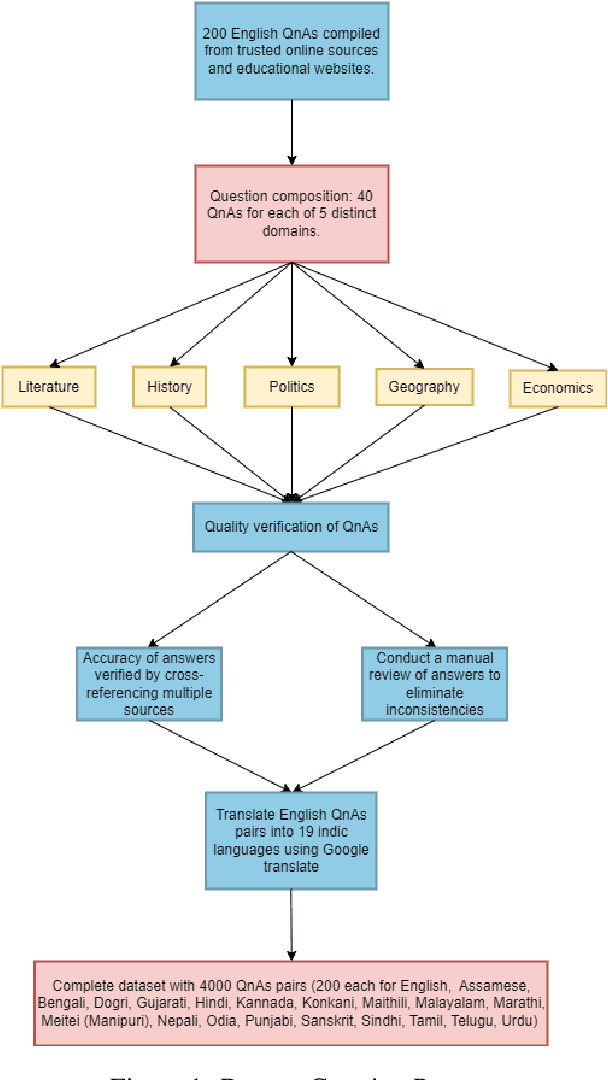


Large Language Models (LLMs) have made significant progress in incorporating Indic languages within multilingual models. However, it is crucial to quantitatively assess whether these languages perform comparably to globally dominant ones, such as English. Currently, there is a lack of benchmark datasets specifically designed to evaluate the regional knowledge of LLMs in various Indic languages. In this paper, we present the L3Cube-IndicQuest, a gold-standard question-answering benchmark dataset designed to evaluate how well multilingual LLMs capture regional knowledge across various Indic languages. The dataset contains 200 question-answer pairs, each for English and 19 Indic languages, covering five domains specific to the Indic region. We aim for this dataset to serve as a benchmark, providing ground truth for evaluating the performance of LLMs in understanding and representing knowledge relevant to the Indian context. The IndicQuest can be used for both reference-based evaluation and LLM-as-a-judge evaluation. The dataset is shared publicly at https://github.com/l3cube-pune/indic-nlp .
Multilingual Evaluation of Semantic Textual Relatedness
Apr 13, 2024
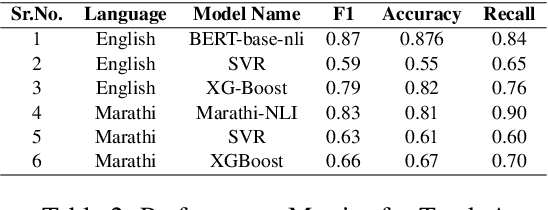


The explosive growth of online content demands robust Natural Language Processing (NLP) techniques that can capture nuanced meanings and cultural context across diverse languages. Semantic Textual Relatedness (STR) goes beyond superficial word overlap, considering linguistic elements and non-linguistic factors like topic, sentiment, and perspective. Despite its pivotal role, prior NLP research has predominantly focused on English, limiting its applicability across languages. Addressing this gap, our paper dives into capturing deeper connections between sentences beyond simple word overlap. Going beyond English-centric NLP research, we explore STR in Marathi, Hindi, Spanish, and English, unlocking the potential for information retrieval, machine translation, and more. Leveraging the SemEval-2024 shared task, we explore various language models across three learning paradigms: supervised, unsupervised, and cross-lingual. Our comprehensive methodology gains promising results, demonstrating the effectiveness of our approach. This work aims to not only showcase our achievements but also inspire further research in multilingual STR, particularly for low-resourced languages.