 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultilingual Evaluation of Semantic Textual Relatedness
Paper and Code
Apr 13, 2024
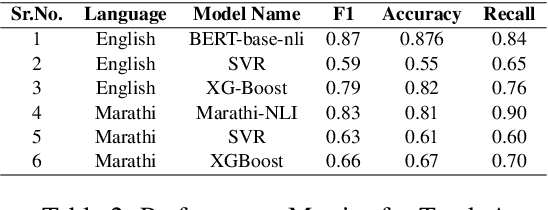


The explosive growth of online content demands robust Natural Language Processing (NLP) techniques that can capture nuanced meanings and cultural context across diverse languages. Semantic Textual Relatedness (STR) goes beyond superficial word overlap, considering linguistic elements and non-linguistic factors like topic, sentiment, and perspective. Despite its pivotal role, prior NLP research has predominantly focused on English, limiting its applicability across languages. Addressing this gap, our paper dives into capturing deeper connections between sentences beyond simple word overlap. Going beyond English-centric NLP research, we explore STR in Marathi, Hindi, Spanish, and English, unlocking the potential for information retrieval, machine translation, and more. Leveraging the SemEval-2024 shared task, we explore various language models across three learning paradigms: supervised, unsupervised, and cross-lingual. Our comprehensive methodology gains promising results, demonstrating the effectiveness of our approach. This work aims to not only showcase our achievements but also inspire further research in multilingual STR, particularly for low-resourced languages.