 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Importance of Pruning and Distillation for Efficient Low Resource NLP
Sep 21, 2024


The rise of large transformer models has revolutionized Natural Language Processing, leading to significant advances in tasks like text classification. However, this progress demands substantial computational resources, escalating training duration, and expenses with larger model sizes. Efforts have been made to downsize and accelerate English models (e.g., Distilbert, MobileBert). Yet, research in this area is scarce for low-resource languages. In this study, we explore the case of the low-resource Indic language Marathi. Leveraging the marathi-topic-all-doc-v2 model as our baseline, we implement optimization techniques to reduce computation time and memory usage. Our focus is on enhancing the efficiency of Marathi transformer models while maintaining top-tier accuracy and reducing computational demands. Using the MahaNews document classification dataset and the marathi-topic-all-doc-v2 model from L3Cube, we apply Block Movement Pruning, Knowledge Distillation, and Mixed Precision methods individually and in combination to boost efficiency. We demonstrate the importance of strategic pruning levels in achieving desired efficiency gains. Furthermore, we analyze the balance between efficiency improvements and environmental impact, highlighting how optimized model architectures can contribute to a more sustainable computational ecosystem. Implementing these techniques on a single GPU system, we determine that the optimal configuration is 25\% pruning + knowledge distillation. This approach yielded a 2.56x speedup in computation time while maintaining baseline accuracy levels.
Multilingual Evaluation of Semantic Textual Relatedness
Apr 13, 2024
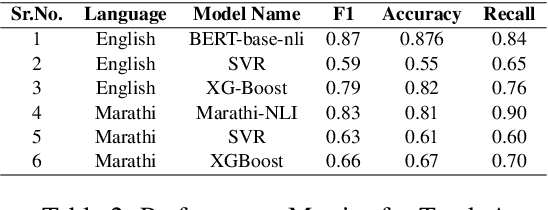


The explosive growth of online content demands robust Natural Language Processing (NLP) techniques that can capture nuanced meanings and cultural context across diverse languages. Semantic Textual Relatedness (STR) goes beyond superficial word overlap, considering linguistic elements and non-linguistic factors like topic, sentiment, and perspective. Despite its pivotal role, prior NLP research has predominantly focused on English, limiting its applicability across languages. Addressing this gap, our paper dives into capturing deeper connections between sentences beyond simple word overlap. Going beyond English-centric NLP research, we explore STR in Marathi, Hindi, Spanish, and English, unlocking the potential for information retrieval, machine translation, and more. Leveraging the SemEval-2024 shared task, we explore various language models across three learning paradigms: supervised, unsupervised, and cross-lingual. Our comprehensive methodology gains promising results, demonstrating the effectiveness of our approach. This work aims to not only showcase our achievements but also inspire further research in multilingual STR, particularly for low-resourced languages.
L3Cube-IndicNews: News-based Short Text and Long Document Classification Datasets in Indic Languages
Jan 04, 2024



In this work, we introduce L3Cube-IndicNews, a multilingual text classification corpus aimed at curating a high-quality dataset for Indian regional languages, with a specific focus on news headlines and articles. We have centered our work on 10 prominent Indic languages, including Hindi, Bengali, Marathi, Telugu, Tamil, Gujarati, Kannada, Odia, Malayalam, and Punjabi. Each of these news datasets comprises 10 or more classes of news articles. L3Cube-IndicNews offers 3 distinct datasets tailored to handle different document lengths that are classified as: Short Headlines Classification (SHC) dataset containing the news headline and news category, Long Document Classification (LDC) dataset containing the whole news article and the news category, and Long Paragraph Classification (LPC) containing sub-articles of the news and the news category. We maintain consistent labeling across all 3 datasets for in-depth length-based analysis. We evaluate each of these Indic language datasets using 4 different models including monolingual BERT, multilingual Indic Sentence BERT (IndicSBERT), and IndicBERT. This research contributes significantly to expanding the pool of available text classification datasets and also makes it possible to develop topic classification models for Indian regional languages. This also serves as an excellent resource for cross-lingual analysis owing to the high overlap of labels among languages. The datasets and models are shared publicly at https://github.com/l3cube-pune/indic-nlp