 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantization-Aware Distillation for NVFP4 Inference Accuracy Recovery
Jan 27, 2026This technical report presents quantization-aware distillation (QAD) and our best practices for recovering accuracy of NVFP4-quantized large language models (LLMs) and vision-language models (VLMs). QAD distills a full-precision teacher model into a quantized student model using a KL divergence loss. While applying distillation to quantized models is not a new idea, we observe key advantages of QAD for today's LLMs: 1. It shows remarkable effectiveness and stability for models trained through multi-stage post-training pipelines, including supervised fine-tuning (SFT), reinforcement learning (RL), and model merging, where traditional quantization-aware training (QAT) suffers from engineering complexity and training instability; 2. It is robust to data quality and coverage, enabling accuracy recovery without full training data. We evaluate QAD across multiple post-trained models including AceReason Nemotron, Nemotron 3 Nano, Nemotron Nano V2, Nemotron Nano V2 VL (VLM), and Llama Nemotron Super v1, showing consistent recovery to near-BF16 accuracy.
NVIDIA Nemotron 3: Efficient and Open Intelligence
Dec 24, 2025We introduce the Nemotron 3 family of models - Nano, Super, and Ultra. These models deliver strong agentic, reasoning, and conversational capabilities. The Nemotron 3 family uses a Mixture-of-Experts hybrid Mamba-Transformer architecture to provide best-in-class throughput and context lengths of up to 1M tokens. Super and Ultra models are trained with NVFP4 and incorporate LatentMoE, a novel approach that improves model quality. The two larger models also include MTP layers for faster text generation. All Nemotron 3 models are post-trained using multi-environment reinforcement learning enabling reasoning, multi-step tool use, and support granular reasoning budget control. Nano, the smallest model, outperforms comparable models in accuracy while remaining extremely cost-efficient for inference. Super is optimized for collaborative agents and high-volume workloads such as IT ticket automation. Ultra, the largest model, provides state-of-the-art accuracy and reasoning performance. Nano is released together with its technical report and this white paper, while Super and Ultra will follow in the coming months. We will openly release the model weights, pre- and post-training software, recipes, and all data for which we hold redistribution rights.
Nemotron 3 Nano: Open, Efficient Mixture-of-Experts Hybrid Mamba-Transformer Model for Agentic Reasoning
Dec 23, 2025We present Nemotron 3 Nano 30B-A3B, a Mixture-of-Experts hybrid Mamba-Transformer language model. Nemotron 3 Nano was pretrained on 25 trillion text tokens, including more than 3 trillion new unique tokens over Nemotron 2, followed by supervised fine tuning and large-scale RL on diverse environments. Nemotron 3 Nano achieves better accuracy than our previous generation Nemotron 2 Nano while activating less than half of the parameters per forward pass. It achieves up to 3.3x higher inference throughput than similarly-sized open models like GPT-OSS-20B and Qwen3-30B-A3B-Thinking-2507, while also being more accurate on popular benchmarks. Nemotron 3 Nano demonstrates enhanced agentic, reasoning, and chat abilities and supports context lengths up to 1M tokens. We release both our pretrained Nemotron 3 Nano 30B-A3B Base and post-trained Nemotron 3 Nano 30B-A3B checkpoints on Hugging Face.
NVIDIA Nemotron Nano V2 VL
Nov 07, 2025We introduce Nemotron Nano V2 VL, the latest model of the Nemotron vision-language series designed for strong real-world document understanding, long video comprehension, and reasoning tasks. Nemotron Nano V2 VL delivers significant improvements over our previous model, Llama-3.1-Nemotron-Nano-VL-8B, across all vision and text domains through major enhancements in model architecture, datasets, and training recipes. Nemotron Nano V2 VL builds on Nemotron Nano V2, a hybrid Mamba-Transformer LLM, and innovative token reduction techniques to achieve higher inference throughput in long document and video scenarios. We are releasing model checkpoints in BF16, FP8, and FP4 formats and sharing large parts of our datasets, recipes and training code.
NVIDIA Nemotron Nano 2: An Accurate and Efficient Hybrid Mamba-Transformer Reasoning Model
Aug 21, 2025



We introduce Nemotron-Nano-9B-v2, a hybrid Mamba-Transformer language model designed to increase throughput for reasoning workloads while achieving state-of-the-art accuracy compared to similarly-sized models. Nemotron-Nano-9B-v2 builds on the Nemotron-H architecture, in which the majority of the self-attention layers in the common Transformer architecture are replaced with Mamba-2 layers, to achieve improved inference speed when generating the long thinking traces needed for reasoning. We create Nemotron-Nano-9B-v2 by first pre-training a 12-billion-parameter model (Nemotron-Nano-12B-v2-Base) on 20 trillion tokens using an FP8 training recipe. After aligning Nemotron-Nano-12B-v2-Base, we employ the Minitron strategy to compress and distill the model with the goal of enabling inference on up to 128k tokens on a single NVIDIA A10G GPU (22GiB of memory, bfloat16 precision). Compared to existing similarly-sized models (e.g., Qwen3-8B), we show that Nemotron-Nano-9B-v2 achieves on-par or better accuracy on reasoning benchmarks while achieving up to 6x higher inference throughput in reasoning settings like 8k input and 16k output tokens. We are releasing Nemotron-Nano-9B-v2, Nemotron-Nano12B-v2-Base, and Nemotron-Nano-9B-v2-Base checkpoints along with the majority of our pre- and post-training datasets on Hugging Face.
Llama-Nemotron: Efficient Reasoning Models
May 02, 2025



We introduce the Llama-Nemotron series of models, an open family of heterogeneous reasoning models that deliver exceptional reasoning capabilities, inference efficiency, and an open license for enterprise use. The family comes in three sizes -- Nano (8B), Super (49B), and Ultra (253B) -- and performs competitively with state-of-the-art reasoning models such as DeepSeek-R1 while offering superior inference throughput and memory efficiency. In this report, we discuss the training procedure for these models, which entails using neural architecture search from Llama 3 models for accelerated inference, knowledge distillation, and continued pretraining, followed by a reasoning-focused post-training stage consisting of two main parts: supervised fine-tuning and large scale reinforcement learning. Llama-Nemotron models are the first open-source models to support a dynamic reasoning toggle, allowing users to switch between standard chat and reasoning modes during inference. To further support open research and facilitate model development, we provide the following resources: 1. We release the Llama-Nemotron reasoning models -- LN-Nano, LN-Super, and LN-Ultra -- under the commercially permissive NVIDIA Open Model License Agreement. 2. We release the complete post-training dataset: Llama-Nemotron-Post-Training-Dataset. 3. We also release our training codebases: NeMo, NeMo-Aligner, and Megatron-LM.
Efficient Hybrid Language Model Compression through Group-Aware SSM Pruning
Apr 15, 2025Hybrid LLM architectures that combine Attention and State Space Models (SSMs) achieve state-of-the-art accuracy and runtime performance. Recent work has demonstrated that applying compression and distillation to Attention-only models yields smaller, more accurate models at a fraction of the training cost. In this work, we explore the effectiveness of compressing Hybrid architectures. We introduce a novel group-aware pruning strategy that preserves the structural integrity of SSM blocks and their sequence modeling capabilities. Furthermore, we demonstrate the necessity of such SSM pruning to achieve improved accuracy and inference speed compared to traditional approaches. Our compression recipe combines SSM, FFN, embedding dimension, and layer pruning, followed by knowledge distillation-based retraining, similar to the MINITRON technique. Using this approach, we compress the Nemotron-H 8B Hybrid model down to 4B parameters with up to 40x fewer training tokens. The resulting model surpasses the accuracy of similarly-sized models while achieving 2x faster inference, significantly advancing the Pareto frontier.
DLGNet: A Transformer-based Model for Dialogue Response Generation
Sep 04, 2019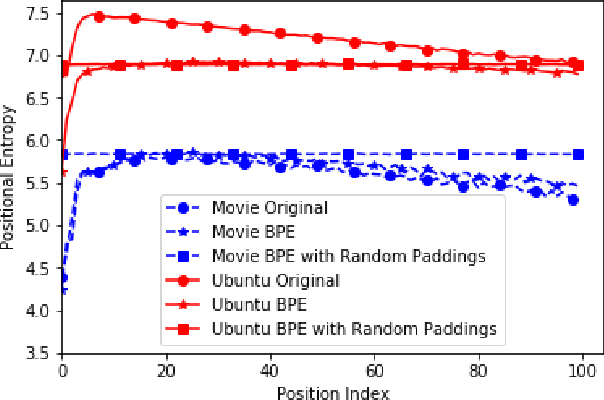

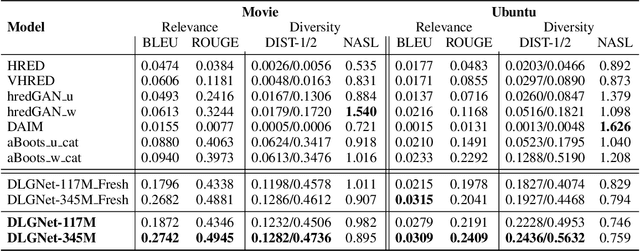
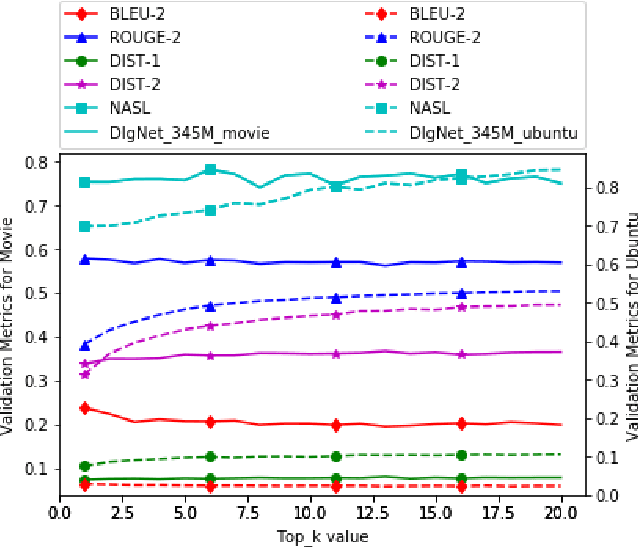
Neural dialogue models, despite their successes, still suffer from lack of relevance, diversity, and in many cases coherence in their generated responses. These issues can attributed to reasons including (1) short-range model architectures that capture limited temporal dependencies, (2) limitations of the maximum likelihood training objective, (3) the concave entropy profile of dialogue datasets resulting in short and generic responses, and (4) the out-of-vocabulary problem leading to generation of a large number of <UNK> tokens. On the other hand, transformer-based models such as GPT-2 have demonstrated an excellent ability to capture long-range structures in language modeling tasks. In this paper, we present DLGNet, a transformer-based model for dialogue modeling. We specifically examine the use of DLGNet for multi-turn dialogue response generation. In our experiments, we evaluate DLGNet on the open-domain Movie Triples dataset and the closed-domain Ubuntu Dialogue dataset. DLGNet models, although trained with only the maximum likelihood objective, achieve significant improvements over state-of-the-art multi-turn dialogue models. They also produce best performance to date on the two datasets based on several metrics, including BLEU, ROUGE, and distinct n-gram. Our analysis shows that the performance improvement is mostly due to the combination of (1) the long-range transformer architecture with (2) the injection of random informative paddings. Other contributing factors include the joint modeling of dialogue context and response, and the 100% tokenization coverage from the byte pair encoding (BPE).
Adversarial Bootstrapping for Dialogue Model Training
Sep 04, 2019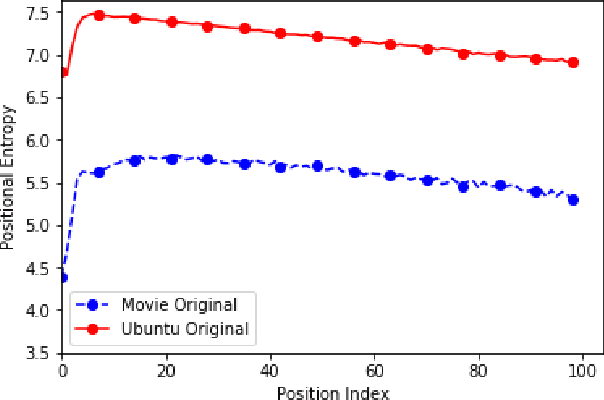
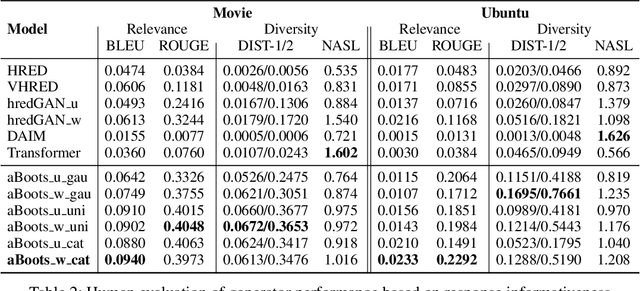
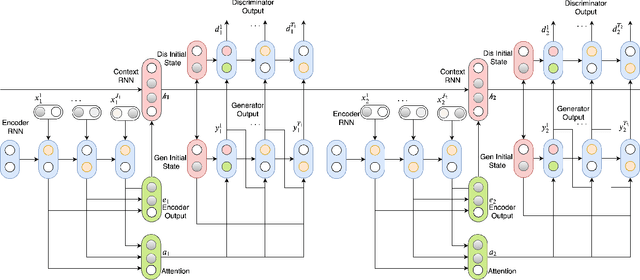
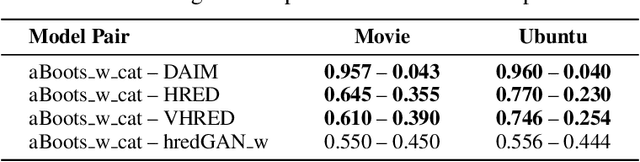
Open domain neural dialogue models, despite their successes, are known to produce responses that lack relevance, diversity, and in many cases coherence. These shortcomings stem from the limited ability of common training objectives to directly express these properties as well as their interplay with training datasets and model architectures. Toward addressing these problems, this paper proposes bootstrapping a dialogue response generator with an adversarially trained discriminator. The method involves training a neural generator in both autoregressive and traditional teacher-forcing modes, with the maximum likelihood loss of the auto-regressive outputs weighted by the score from a metric-based discriminator model. The discriminator input is a mixture of ground truth labels, the teacher-forcing outputs of the generator, and distractors sampled from the dataset, thereby allowing for richer feedback on the autoregressive outputs of the generator. To improve the calibration of the discriminator output, we also bootstrap the discriminator with the matching of the intermediate features of the ground truth and the generator's autoregressive output. We explore different sampling and adversarial policy optimization strategies during training in order to understand how to encourage response diversity without sacrificing relevance. Our experiments shows that adversarial bootstrapping is effective at addressing exposure bias, leading to improvement in response relevance and coherence. The improvement is demonstrated with the state-of-the-art results on the Movie and Ubuntu dialogue datasets with respect to human evaluations and BLUE, ROGUE, and distinct n-gram scores.
An Adversarial Learning Framework For A Persona-Based Multi-Turn Dialogue Model
Apr 29, 2019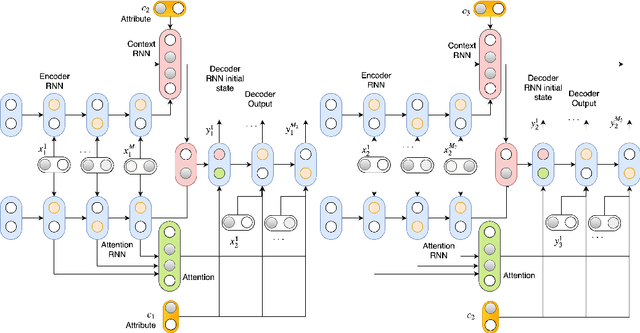
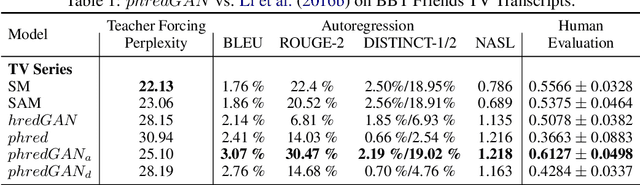
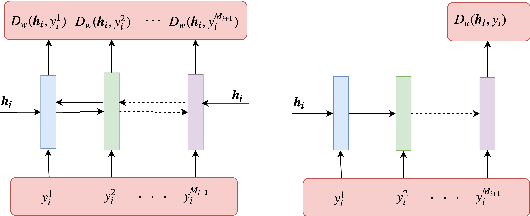
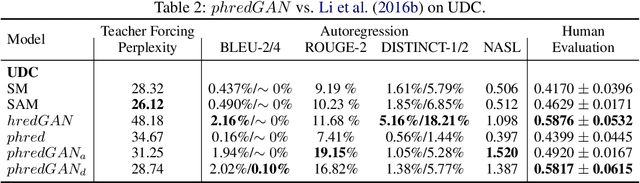
In this paper, we extend the persona-based sequence-to-sequence (Seq2Seq) neural network conversation model to a multi-turn dialogue scenario by modifying the state-of-the-art hredGAN architecture to simultaneously capture utterance attributes such as speaker identity, dialogue topic, speaker sentiments and so on. The proposed system, phredGAN has a persona-based HRED generator (PHRED) and a conditional discriminator. We also explore two approaches to accomplish the conditional discriminator: (1) phredGAN_a, a system that passes the attribute representation as an additional input into a traditional adversarial discriminator, and (2) phredGAN_d, a dual discriminator system which in addition to the adversarial discriminator, collaboratively predicts the attribute(s) that generated the input utterance. To demonstrate the superior performance of phredGAN over the persona Seq2Seq model, we experiment with two conversational datasets, the Ubuntu Dialogue Corpus (UDC) and TV series transcripts from the Big Bang Theory and Friends. Performance comparison is made with respect to a variety of quantitative measures as well as crowd-sourced human evaluation. We also explore the trade-offs from using either variant of phredGAN on datasets with many but weak attribute modalities (such as with Big Bang Theory and Friends) and ones with few but strong attribute modalities (customer-agent interactions in Ubuntu dataset).