 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTaxonomic Recommendations of Real Estate Properties with Textual Attribute Information
Oct 27, 2022


In this extended abstract, we present an end to end approach for building a taxonomy of home attribute terms that enables hierarchical recommendations of real estate properties. We cover the methodology for building a real-estate taxonomy, metrics for measuring this structure's quality, and then conclude with a production use-case of making recommendations from search keywords at different levels of topical similarity.
DeepDefacer: Automatic Removal of Facial Features via U-Net Image Segmentation
May 31, 2022



Recent advancements in the field of magnetic resonance imaging (MRI) have enabled large-scale collaboration among clinicians and researchers for neuroimaging tasks. However, researchers are often forced to use outdated and slow software to anonymize MRI images for publication. These programs specifically perform expensive mathematical operations over 3D images that rapidly slow down anonymization speed as an image's volume increases in size. In this paper, we introduce DeepDefacer, an application of deep learning to MRI anonymization that uses a streamlined 3D U-Net network to mask facial regions in MRI images with a significant increase in speed over traditional de-identification software. We train DeepDefacer on MRI images from the Brain Development Organization (IXI) and International Consortium for Brain Mapping (ICBM) and quantitatively evaluate our model against a baseline 3D U-Net model with regards to Dice, recall, and precision scores. We also evaluate DeepDefacer against Pydeface, a traditional defacing application, with regards to speed on a range of CPU and GPU devices and qualitatively evaluate our model's defaced output versus the ground truth images produced by Pydeface. We provide a link to a PyPi program at the end of this manuscript to encourage further research into the application of deep learning to MRI anonymization.
DeepTrax: Embedding Graphs of Financial Transactions
Jul 16, 2019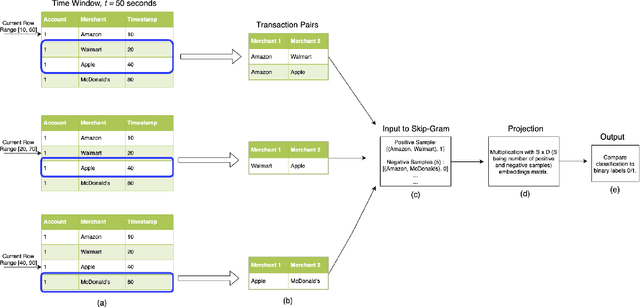
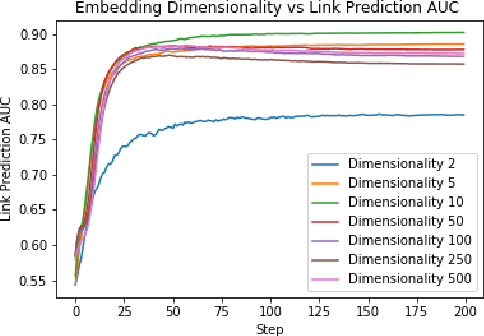
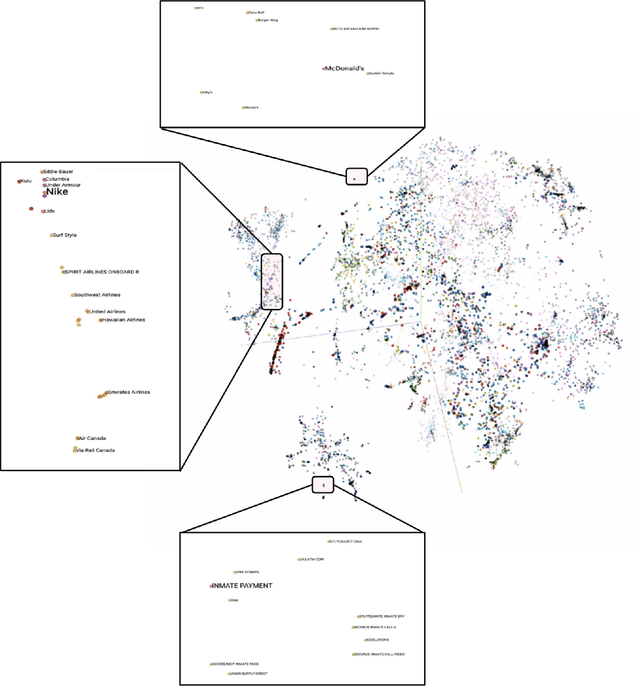
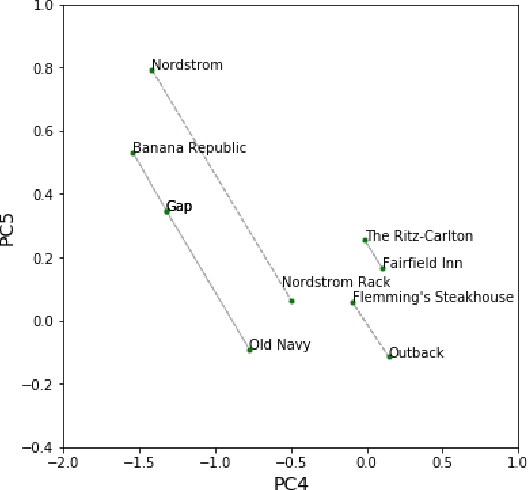
Financial transactions can be considered edges in a heterogeneous graph between entities sending money and entities receiving money. For financial institutions, such a graph is likely large (with millions or billions of edges) while also sparsely connected. It becomes challenging to apply machine learning to such large and sparse graphs. Graph representation learning seeks to embed the nodes of a graph into a Euclidean vector space such that graph topological properties are preserved after the transformation. In this paper, we present a novel application of representation learning to bipartite graphs of credit card transactions in order to learn embeddings of account and merchant entities. Our framework is inspired by popular approaches in graph embeddings and is trained on two internal transaction datasets. This approach yields highly effective embeddings, as quantified by link prediction AUC and F1 score. Further, the resulting entity vectors retain intuitive semantic similarity that is explored through visualizations and other qualitative analyses. Finally, we show how these embeddings can be used as features in downstream machine learning business applications such as fraud detection.
Graph Embeddings at Scale
Jul 03, 2019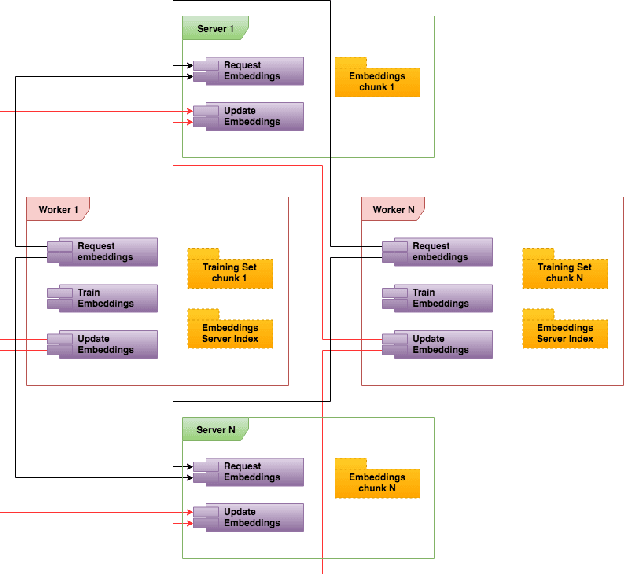

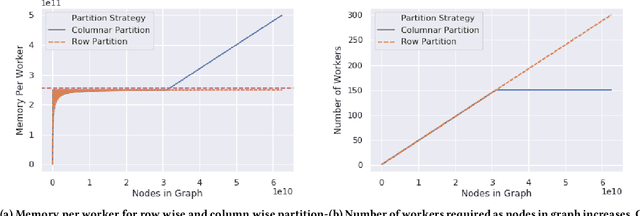

Graph embedding is a popular algorithmic approach for creating vector representations for individual vertices in networks. Training these algorithms at scale is important for creating embeddings that can be used for classification, ranking, recommendation and other common applications in industry. While industrial systems exist for training graph embeddings on large datasets, many of these distributed architectures are forced to partition copious amounts of data and model logic across many worker nodes. In this paper, we propose a distributed infrastructure that completely avoids graph partitioning, dynamically creates size constrained computational graphs across worker nodes, and uses highly efficient indexing operations for updating embeddings that allow the system to function at scale. We show that our system can scale an existing embeddings algorithm - skip-gram - to train on the open-source Friendster network (68 million vertices) and on an internal heterogeneous graph (50 million vertices). We measure the performance of our system on two key quantitative metrics: link-prediction accuracy and rate of convergence. We conclude this work by analyzing how a greater number of worker nodes actually improves our system's performance on the aforementioned metrics and discuss our next steps for rigorously evaluating the embedding vectors produced by our system.
An Adversarial Learning Framework For A Persona-Based Multi-Turn Dialogue Model
Apr 29, 2019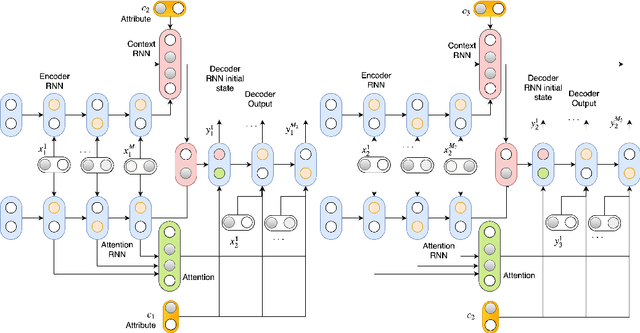
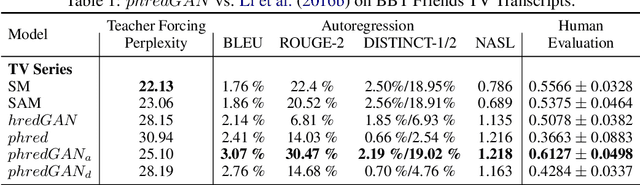
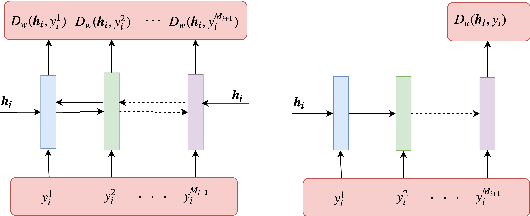
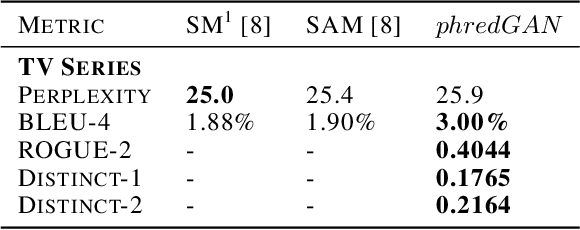
In this paper, we extend the persona-based sequence-to-sequence (Seq2Seq) neural network conversation model to a multi-turn dialogue scenario by modifying the state-of-the-art hredGAN architecture to simultaneously capture utterance attributes such as speaker identity, dialogue topic, speaker sentiments and so on. The proposed system, phredGAN has a persona-based HRED generator (PHRED) and a conditional discriminator. We also explore two approaches to accomplish the conditional discriminator: (1) phredGAN_a, a system that passes the attribute representation as an additional input into a traditional adversarial discriminator, and (2) phredGAN_d, a dual discriminator system which in addition to the adversarial discriminator, collaboratively predicts the attribute(s) that generated the input utterance. To demonstrate the superior performance of phredGAN over the persona Seq2Seq model, we experiment with two conversational datasets, the Ubuntu Dialogue Corpus (UDC) and TV series transcripts from the Big Bang Theory and Friends. Performance comparison is made with respect to a variety of quantitative measures as well as crowd-sourced human evaluation. We also explore the trade-offs from using either variant of phredGAN on datasets with many but weak attribute modalities (such as with Big Bang Theory and Friends) and ones with few but strong attribute modalities (customer-agent interactions in Ubuntu dataset).
A Persona-based Multi-turn Conversation Model in an Adversarial Learning Framework
Apr 29, 2019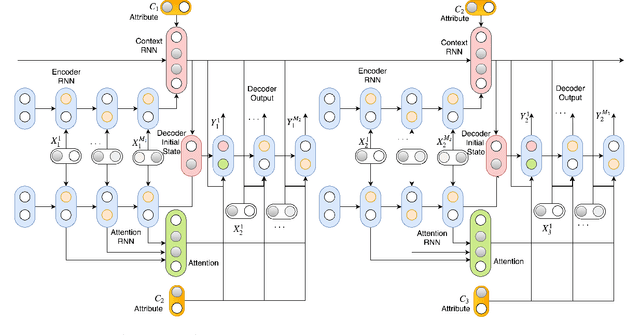


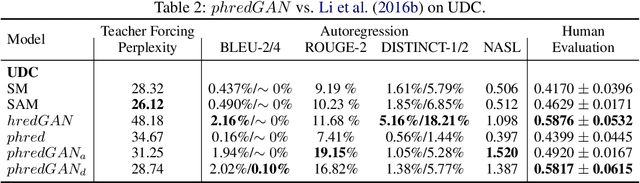
In this paper, we extend the persona-based sequence-to-sequence (Seq2Seq) neural network conversation model to multi-turn dialogue by modifying the state-of-the-art hredGAN architecture. To achieve this, we introduce an additional input modality into the encoder and decoder of hredGAN to capture other attributes such as speaker identity, location, sub-topics, and other external attributes that might be available from the corpus of human-to-human interactions. The resulting persona hredGAN ($phredGAN$) shows better performance than both the existing persona-based Seq2Seq and hredGAN models when those external attributes are available in a multi-turn dialogue corpus. This superiority is demonstrated on TV drama series with character consistency (such as Big Bang Theory and Friends) and customer service interaction datasets such as Ubuntu dialogue corpus in terms of perplexity, BLEU, ROUGE, and Distinct n-gram scores.
Multi-turn Dialogue Response Generation in an Adversarial Learning Framework
Sep 19, 2018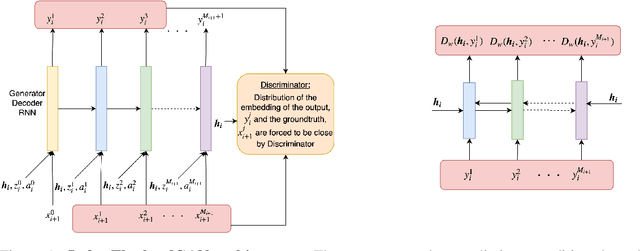
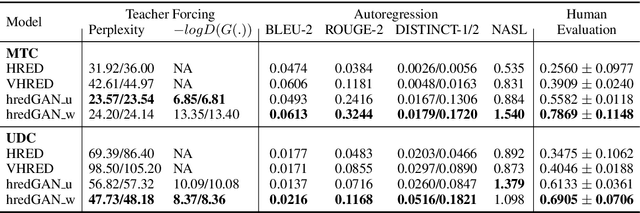
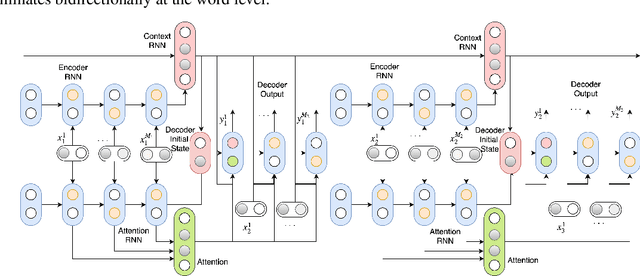
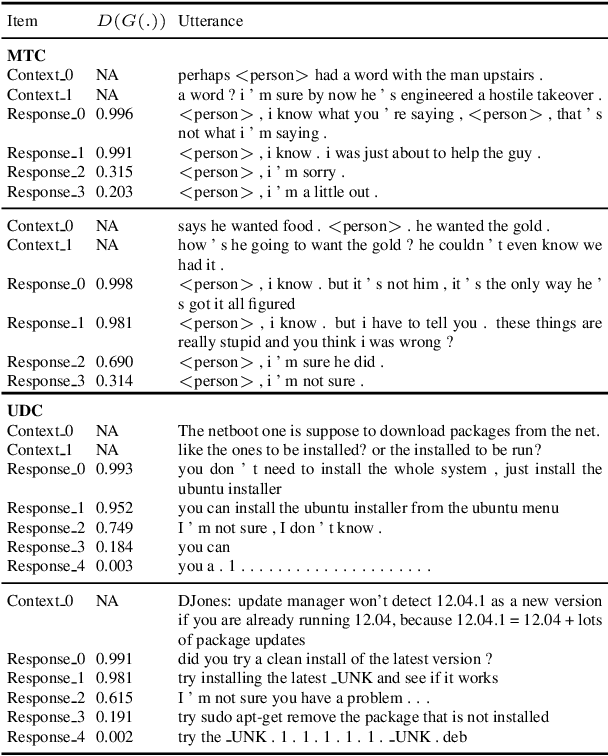
We propose an adversarial learning approach to the generation of multi-turn dialogue responses. Our proposed framework, hredGAN, is based on conditional generative adversarial networks (GANs). The GAN's generator is a modified hierarchical recurrent encoder-decoder network (HRED) and the discriminator is a word-level bidirectional RNN that shares context and word embedding with the generator. During inference, noise samples conditioned on the dialogue history are used to perturb the generator's latent space to generate several possible responses. The final response is the one ranked best by the discriminator. The hredGAN shows major advantages over existing methods: (1) it generalizes better than networks trained using only the log-likelihood criterion, and (2) it generates longer, more informative and more diverse responses with high utterance and topic relevance even with limited training data. This superiority is demonstrated on the Movie triples and Ubuntu dialogue datasets in terms of perplexity, BLEU, ROUGE and Distinct n-gram scores.