 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAssessing metadata privacy in neuroimaging
Sep 18, 2025



The ethical and legal imperative to share research data without causing harm requires careful attention to privacy risks. While mounting evidence demonstrates that data sharing benefits science, legitimate concerns persist regarding the potential leakage of personal information that could lead to reidentification and subsequent harm. We reviewed metadata accompanying neuroimaging datasets from six heterogeneous studies openly available on OpenNeuro, involving participants across the lifespan, from children to older adults, with and without clinical diagnoses, and including associated clinical score data. Using metaprivBIDS (https://github.com/CPernet/metaprivBIDS), a novel tool for the systematic assessment of privacy in tabular data, we found that privacy is generally well maintained, with serious vulnerabilities being rare. Nonetheless, minor issues were identified in nearly all datasets and warrant mitigation. Notably, clinical score data (e.g., neuropsychological results) posed minimal reidentification risk, whereas demographic variables (age, sex, race, income, and geolocation) represented the principal privacy vulnerabilities. We outline practical measures to address these risks, enabling safer data sharing practices.
REFORMS: Reporting Standards for Machine Learning Based Science
Aug 15, 2023
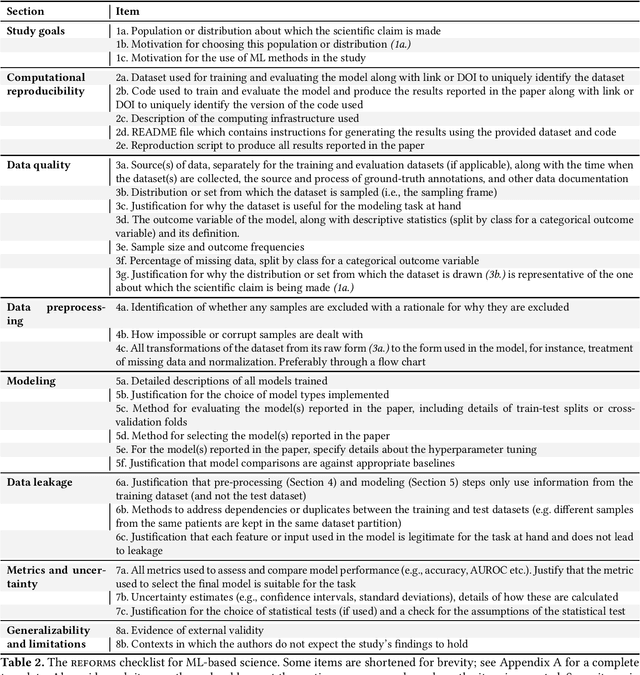
Machine learning (ML) methods are proliferating in scientific research. However, the adoption of these methods has been accompanied by failures of validity, reproducibility, and generalizability. These failures can hinder scientific progress, lead to false consensus around invalid claims, and undermine the credibility of ML-based science. ML methods are often applied and fail in similar ways across disciplines. Motivated by this observation, our goal is to provide clear reporting standards for ML-based science. Drawing from an extensive review of past literature, we present the REFORMS checklist ($\textbf{Re}$porting Standards $\textbf{For}$ $\textbf{M}$achine Learning Based $\textbf{S}$cience). It consists of 32 questions and a paired set of guidelines. REFORMS was developed based on a consensus of 19 researchers across computer science, data science, mathematics, social sciences, and biomedical sciences. REFORMS can serve as a resource for researchers when designing and implementing a study, for referees when reviewing papers, and for journals when enforcing standards for transparency and reproducibility.
Differentiable programming for functional connectomics
May 31, 2022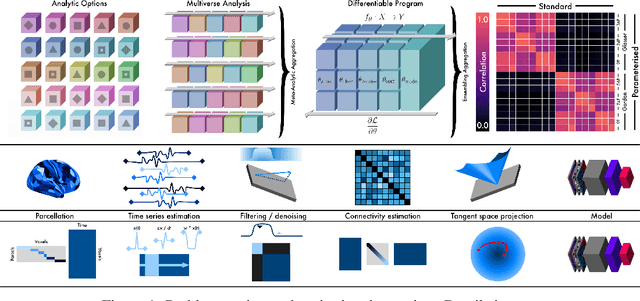

Mapping the functional connectome has the potential to uncover key insights into brain organisation. However, existing workflows for functional connectomics are limited in their adaptability to new data, and principled workflow design is a challenging combinatorial problem. We introduce a new analytic paradigm and software toolbox that implements common operations used in functional connectomics as fully differentiable processing blocks. Under this paradigm, workflow configurations exist as reparameterisations of a differentiable functional that interpolates them. The differentiable program that we envision occupies a niche midway between traditional pipelines and end-to-end neural networks, combining the glass-box tractability and domain knowledge of the former with the amenability to optimisation of the latter. In this preliminary work, we provide a proof of concept for differentiable connectomics, demonstrating the capacity of our processing blocks both to recapitulate canonical knowledge in neuroscience and to make new discoveries in an unsupervised setting. Our differentiable modules are competitive with state-of-the-art methods in problem domains including functional parcellation, denoising, and covariance modelling. Taken together, our results and software demonstrate the promise of differentiable programming for functional connectomics.
Comparing interpretation methods in mental state decoding analyses with deep learning models
May 31, 2022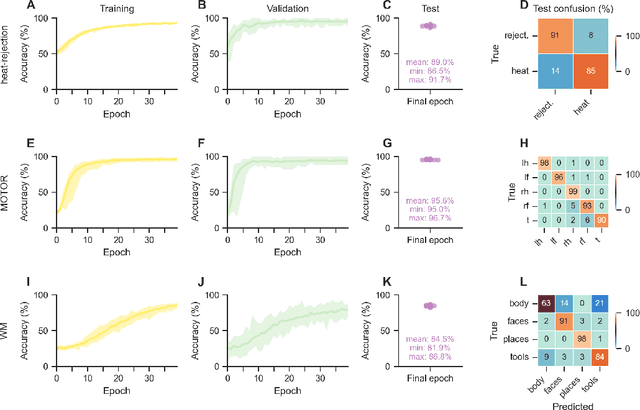
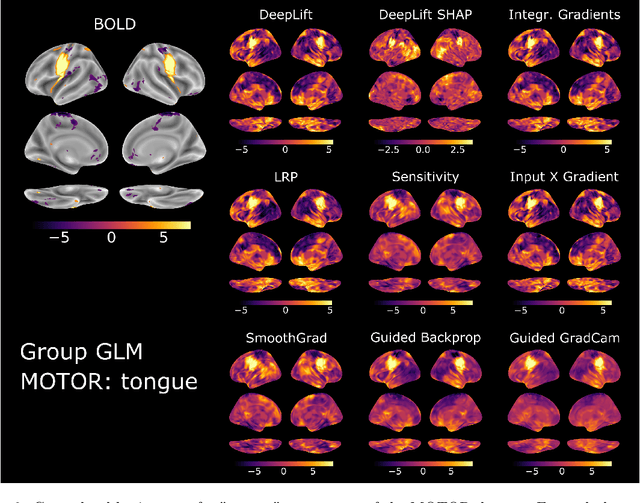
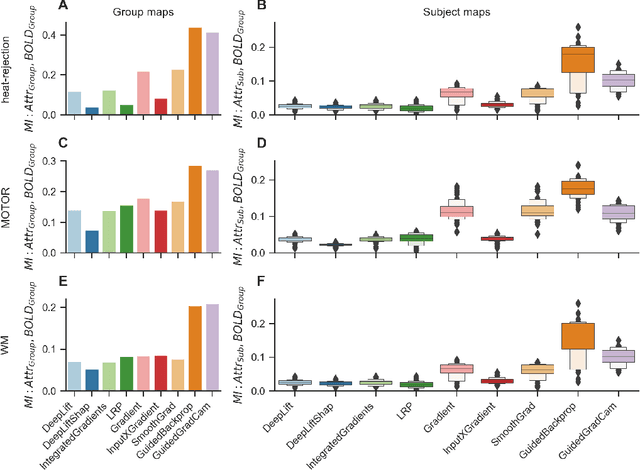
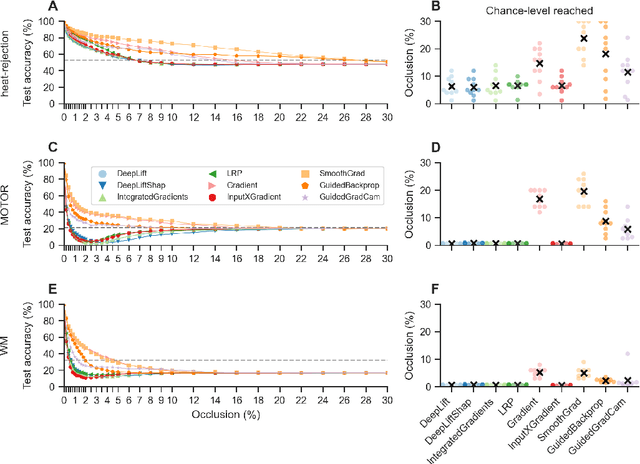
Deep learning (DL) methods find increasing application in mental state decoding, where researchers seek to understand the mapping between mental states (such as accepting or rejecting a gamble) and brain activity, by identifying those brain regions (and networks) whose activity allows to accurately identify (i.e., decode) these states. Once DL models have been trained to accurately decode a set of mental states, neuroimaging researchers often make use of interpretation methods from explainable artificial intelligence research to understand their learned mappings between mental states and brain activity. Here, we compare the explanations of prominent interpretation methods for the mental state decoding decisions of DL models trained on three functional Magnetic Resonance Imaging (fMRI) datasets. We find that interpretation methods that capture the model's decision process well, by producing faithful explanations, generally produce explanations that are less in line with the results of standard analyses of the fMRI data, when compared to the explanations of interpretation methods with less explanation faithfulness. Specifically, we find that interpretation methods that focus on how sensitively a model's decoding decision changes with the values of the input produce explanations that better match with the results of a standard general linear model analysis of the fMRI data, while interpretation methods that focus on identifying the specific contribution of an input feature's value to the decoding decision produce overall more faithful explanations that align less well with the results of standard analyses of the fMRI data.
DeepDefacer: Automatic Removal of Facial Features via U-Net Image Segmentation
May 31, 2022



Recent advancements in the field of magnetic resonance imaging (MRI) have enabled large-scale collaboration among clinicians and researchers for neuroimaging tasks. However, researchers are often forced to use outdated and slow software to anonymize MRI images for publication. These programs specifically perform expensive mathematical operations over 3D images that rapidly slow down anonymization speed as an image's volume increases in size. In this paper, we introduce DeepDefacer, an application of deep learning to MRI anonymization that uses a streamlined 3D U-Net network to mask facial regions in MRI images with a significant increase in speed over traditional de-identification software. We train DeepDefacer on MRI images from the Brain Development Organization (IXI) and International Consortium for Brain Mapping (ICBM) and quantitatively evaluate our model against a baseline 3D U-Net model with regards to Dice, recall, and precision scores. We also evaluate DeepDefacer against Pydeface, a traditional defacing application, with regards to speed on a range of CPU and GPU devices and qualitatively evaluate our model's defaced output versus the ground truth images produced by Pydeface. We provide a link to a PyPi program at the end of this manuscript to encourage further research into the application of deep learning to MRI anonymization.
Challenges for cognitive decoding using deep learning methods
Aug 16, 2021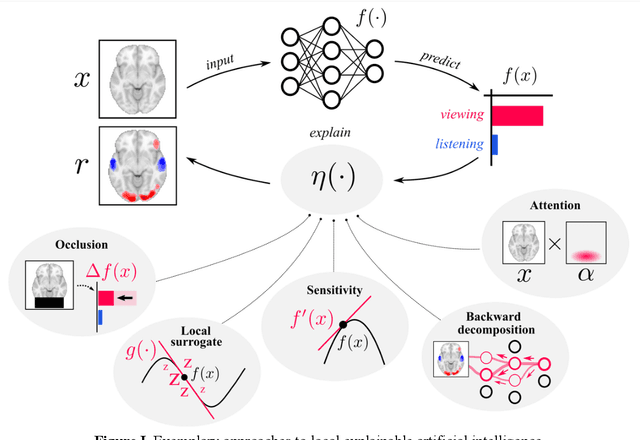
In cognitive decoding, researchers aim to characterize a brain region's representations by identifying the cognitive states (e.g., accepting/rejecting a gamble) that can be identified from the region's activity. Deep learning (DL) methods are highly promising for cognitive decoding, with their unmatched ability to learn versatile representations of complex data. Yet, their widespread application in cognitive decoding is hindered by their general lack of interpretability as well as difficulties in applying them to small datasets and in ensuring their reproducibility and robustness. We propose to approach these challenges by leveraging recent advances in explainable artificial intelligence and transfer learning, while also providing specific recommendations on how to improve the reproducibility and robustness of DL modeling results.
Computational and informatics advances for reproducible data analysis in neuroimaging
Sep 24, 2018

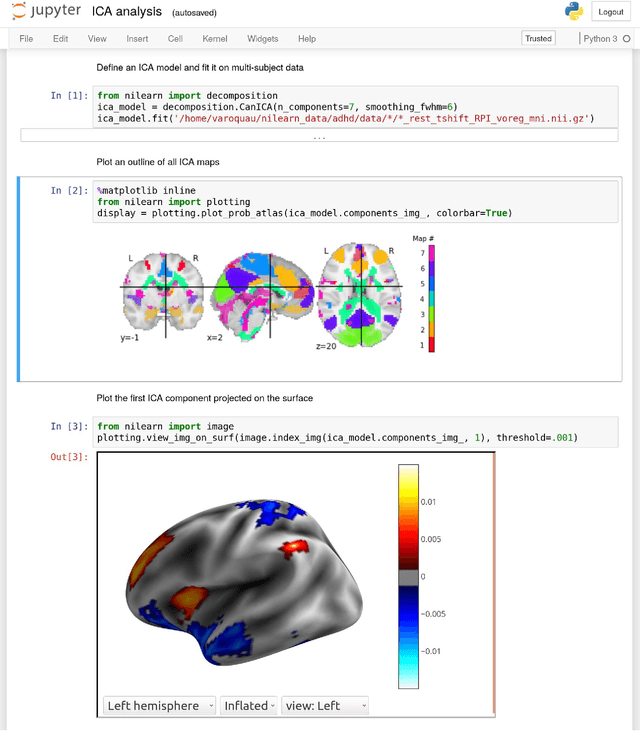

The reproducibility of scientific research has become a point of critical concern. We argue that openness and transparency are critical for reproducibility, and we outline an ecosystem for open and transparent science that has emerged within the human neuroimaging community. We discuss the range of open data sharing resources that have been developed for neuroimaging data, and the role of data standards (particularly the Brain Imaging Data Structure) in enabling the automated sharing, processing, and reuse of large neuroimaging datasets. We outline how the open-source Python language has provided the basis for a data science platform that enables reproducible data analysis and visualization. We also discuss how new advances in software engineering, such as containerization, provide the basis for greater reproducibility in data analysis. The emergence of this new ecosystem provides an example for many areas of science that are currently struggling with reproducibility.