 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNavigating Pitfalls: Evaluating LLMs in Machine Learning Programming Education
May 23, 2025The rapid advancement of Large Language Models (LLMs) has opened new avenues in education. This study examines the use of LLMs in supporting learning in machine learning education; in particular, it focuses on the ability of LLMs to identify common errors of practice (pitfalls) in machine learning code, and their ability to provide feedback that can guide learning. Using a portfolio of code samples, we consider four different LLMs: one closed model and three open models. Whilst the most basic pitfalls are readily identified by all models, many common pitfalls are not. They particularly struggle to identify pitfalls in the early stages of the ML pipeline, especially those which can lead to information leaks, a major source of failure within applied ML projects. They also exhibit limited success at identifying pitfalls around model selection, which is a concept that students often struggle with when first transitioning from theory to practice. This questions the use of current LLMs to support machine learning education, and also raises important questions about their use by novice practitioners. Nevertheless, when LLMs successfully identify pitfalls in code, they do provide feedback that includes advice on how to proceed, emphasising their potential role in guiding learners. We also compare the capability of closed and open LLM models, and find that the gap is relatively small given the large difference in model sizes. This presents an opportunity to deploy, and potentially customise, smaller more efficient LLM models within education, avoiding risks around cost and data sharing associated with commercial models.
Self-Supervised Learning for Pre-training Capsule Networks: Overcoming Medical Imaging Dataset Challenges
Feb 07, 2025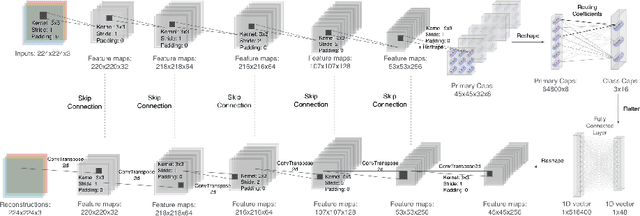
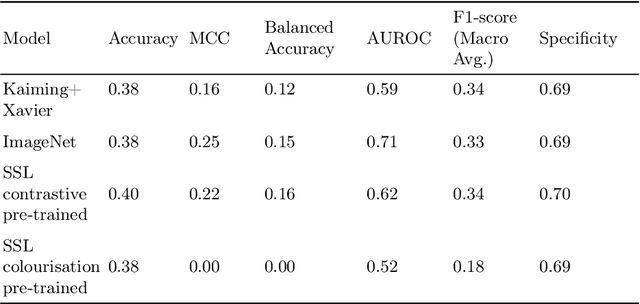
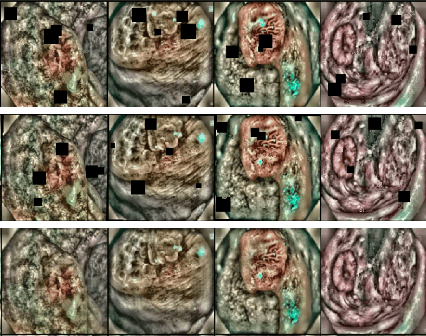
Deep learning techniques are increasingly being adopted in diagnostic medical imaging. However, the limited availability of high-quality, large-scale medical datasets presents a significant challenge, often necessitating the use of transfer learning approaches. This study investigates self-supervised learning methods for pre-training capsule networks in polyp diagnostics for colon cancer. We used the PICCOLO dataset, comprising 3,433 samples, which exemplifies typical challenges in medical datasets: small size, class imbalance, and distribution shifts between data splits. Capsule networks offer inherent interpretability due to their architecture and inter-layer information routing mechanism. However, their limited native implementation in mainstream deep learning frameworks and the lack of pre-trained versions pose a significant challenge. This is particularly true if aiming to train them on small medical datasets, where leveraging pre-trained weights as initial parameters would be beneficial. We explored two auxiliary self-supervised learning tasks, colourisation and contrastive learning, for capsule network pre-training. We compared self-supervised pre-trained models against alternative initialisation strategies. Our findings suggest that contrastive learning and in-painting techniques are suitable auxiliary tasks for self-supervised learning in the medical domain. These techniques helped guide the model to capture important visual features that are beneficial for the downstream task of polyp classification, increasing its accuracy by 5.26% compared to other weight initialisation methods.
Individual Packet Features are a Risk to Model Generalisation in ML-Based Intrusion Detection
Jun 07, 2024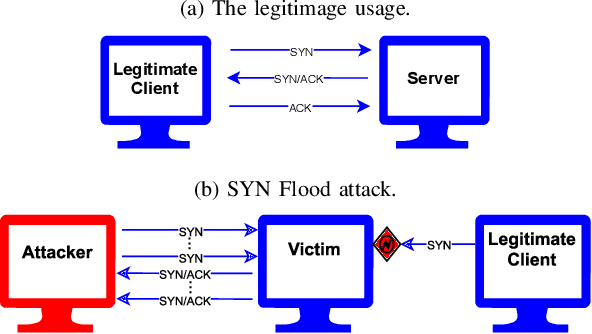

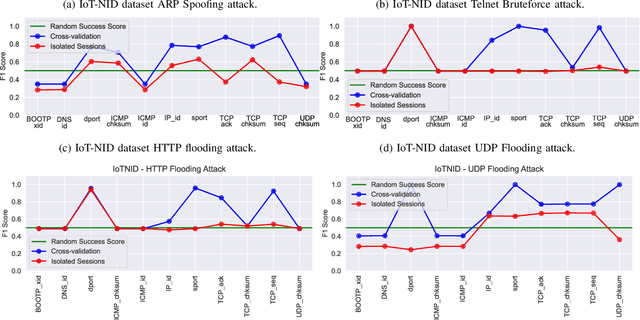
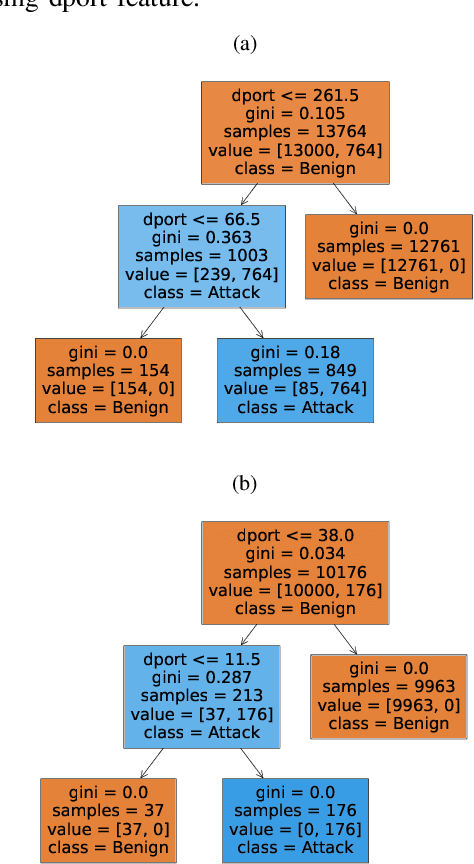
Machine learning is increasingly used for intrusion detection in IoT networks. This paper explores the effectiveness of using individual packet features (IPF), which are attributes extracted from a single network packet, such as timing, size, and source-destination information. Through literature review and experiments, we identify the limitations of IPF, showing they can produce misleadingly high detection rates. Our findings emphasize the need for approaches that consider packet interactions for robust intrusion detection. Additionally, we demonstrate that models based on IPF often fail to generalize across datasets, compromising their reliability in diverse IoT environments.
REFORMS: Reporting Standards for Machine Learning Based Science
Aug 15, 2023
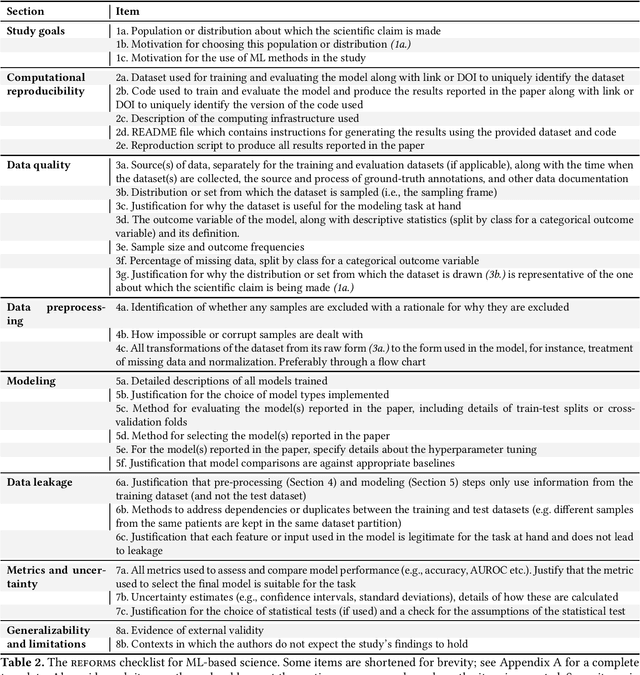
Machine learning (ML) methods are proliferating in scientific research. However, the adoption of these methods has been accompanied by failures of validity, reproducibility, and generalizability. These failures can hinder scientific progress, lead to false consensus around invalid claims, and undermine the credibility of ML-based science. ML methods are often applied and fail in similar ways across disciplines. Motivated by this observation, our goal is to provide clear reporting standards for ML-based science. Drawing from an extensive review of past literature, we present the REFORMS checklist ($\textbf{Re}$porting Standards $\textbf{For}$ $\textbf{M}$achine Learning Based $\textbf{S}$cience). It consists of 32 questions and a paired set of guidelines. REFORMS was developed based on a consensus of 19 researchers across computer science, data science, mathematics, social sciences, and biomedical sciences. REFORMS can serve as a resource for researchers when designing and implementing a study, for referees when reviewing papers, and for journals when enforcing standards for transparency and reproducibility.
How to avoid machine learning pitfalls: a guide for academic researchers
Aug 05, 2021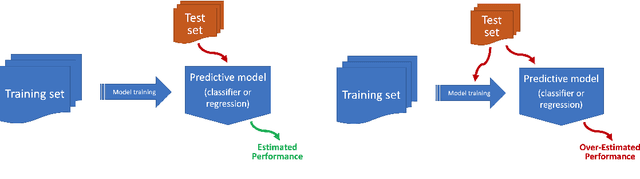
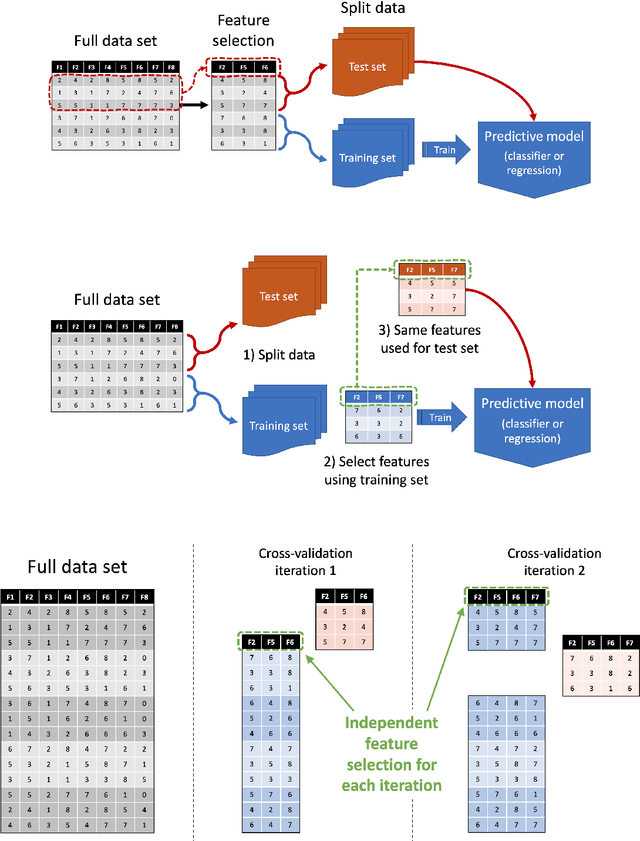

This document gives a concise outline of some of the common mistakes that occur when using machine learning techniques, and what can be done to avoid them. It is intended primarily as a guide for research students, and focuses on issues that are of particular concern within academic research, such as the need to do rigorous comparisons and reach valid conclusions. It covers five stages of the machine learning process: what to do before model building, how to reliably build models, how to robustly evaluate models, how to compare models fairly, and how to report results.
A Data-Driven Biophysical Computational Model of Parkinson's Disease based on Marmoset Monkeys
Jul 27, 2021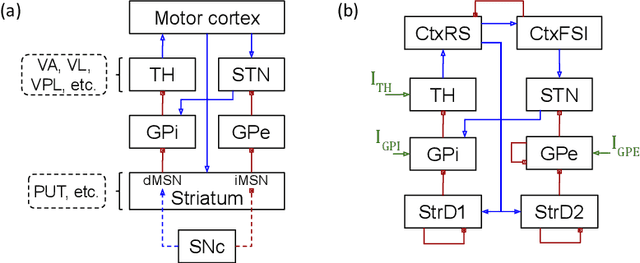
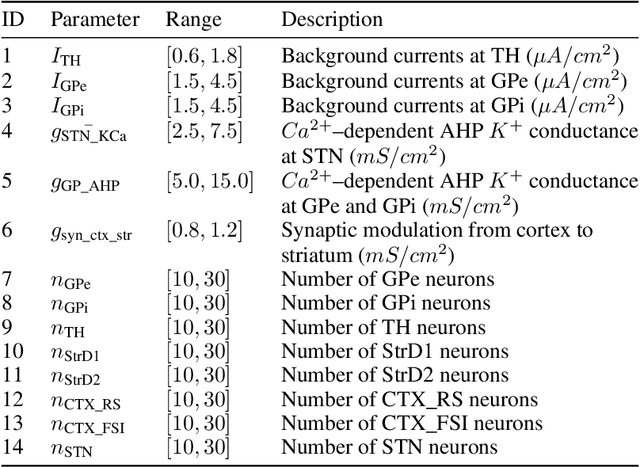
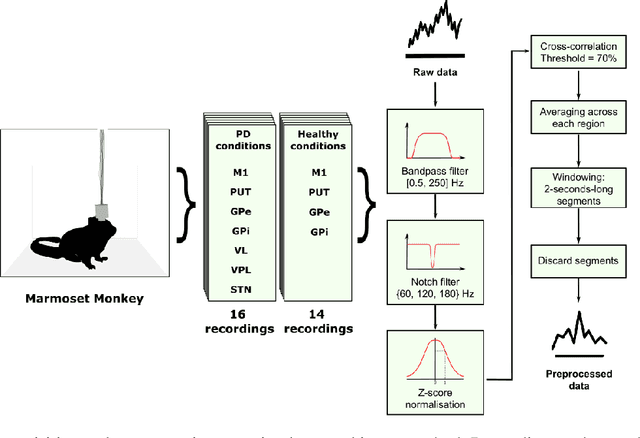

In this work we propose a new biophysical computational model of brain regions relevant to Parkinson's Disease based on local field potential data collected from the brain of marmoset monkeys. Parkinson's disease is a neurodegenerative disorder, linked to the death of dopaminergic neurons at the substantia nigra pars compacta, which affects the normal dynamics of the basal ganglia-thalamus-cortex neuronal circuit of the brain. Although there are multiple mechanisms underlying the disease, a complete description of those mechanisms and molecular pathogenesis are still missing, and there is still no cure. To address this gap, computational models that resemble neurobiological aspects found in animal models have been proposed. In our model, we performed a data-driven approach in which a set of biologically constrained parameters is optimised using differential evolution. Evolved models successfully resembled single-neuron mean firing rates and spectral signatures of local field potentials from healthy and parkinsonian marmoset brain data. As far as we are concerned, this is the first computational model of Parkinson's Disease based on simultaneous electrophysiological recordings from seven brain regions of Marmoset monkeys. Results show that the proposed model could facilitate the investigation of the mechanisms of PD and support the development of techniques that can indicate new therapies. It could also be applied to other computational neuroscience problems in which biological data could be used to fit multi-scale models of brain circuits.
Evolving Continuous Optimisers from Scratch
Mar 22, 2021


This work uses genetic programming to explore the space of continuous optimisers, with the goal of discovering novel ways of doing optimisation. In order to keep the search space broad, the optimisers are evolved from scratch using Push, a Turing-complete, general-purpose, language. The resulting optimisers are found to be diverse, and explore their optimisation landscapes using a variety of interesting, and sometimes unusual, strategies. Significantly, when applied to problems that were not seen during training, many of the evolved optimisers generalise well, and often outperform existing optimisers. This supports the idea that novel and effective forms of optimisation can be discovered in an automated manner. This paper also shows that pools of evolved optimisers can be hybridised to further increase their generality, leading to optimisers that perform robustly over a broad variety of problem types and sizes.
IoTDevID: A Behaviour-Based Fingerprinting Method for Device Identification in the IoT
Feb 17, 2021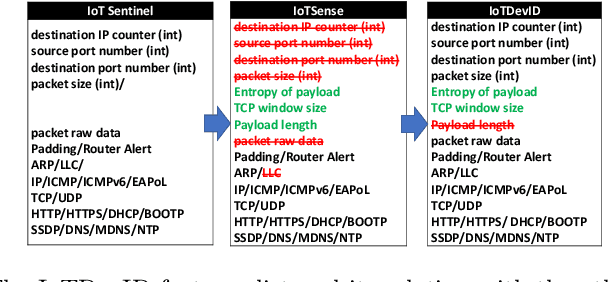
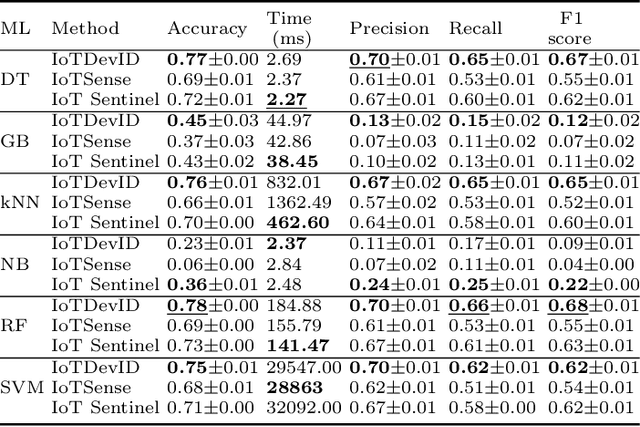
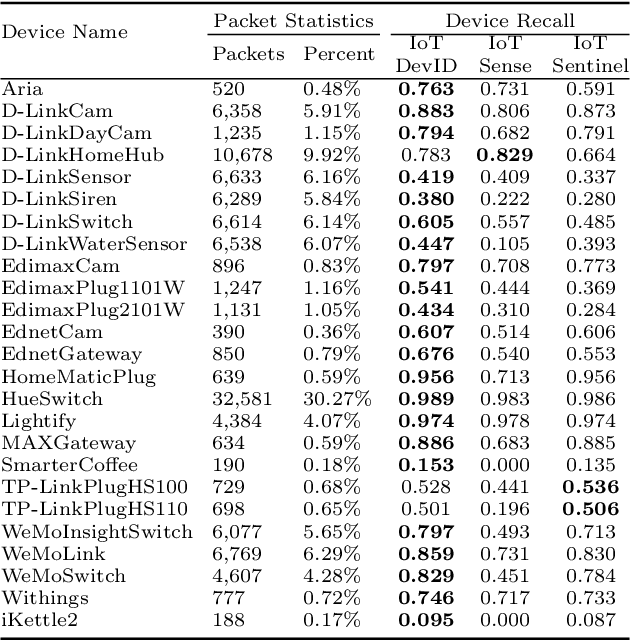
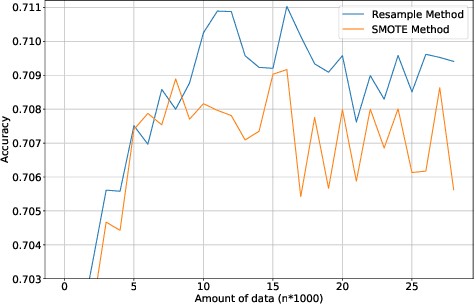
Device identification is one way to secure a network of IoT devices, whereby devices identified as suspicious can subsequently be isolated from a network. We introduce a novel fingerprinting method, IoTDevID, for device identification that uses machine learning to model the behaviour of IoT devices based on network packets. Our method uses an enhanced combination of features from previous work and includes an approach for dealing with unbalanced device data via data augmentation. We further demonstrate how to enhance device identification via a group-wise data aggregation. We provide a comparative evaluation of our method against two recent identification methods using three public IoT datasets which together contain data from over 100 devices. Through our evaluation we demonstrate improved performance over previous results with F1-scores above 99%, with considerable improvement gained from data aggregation.
Evolutionary Algorithms
May 28, 2018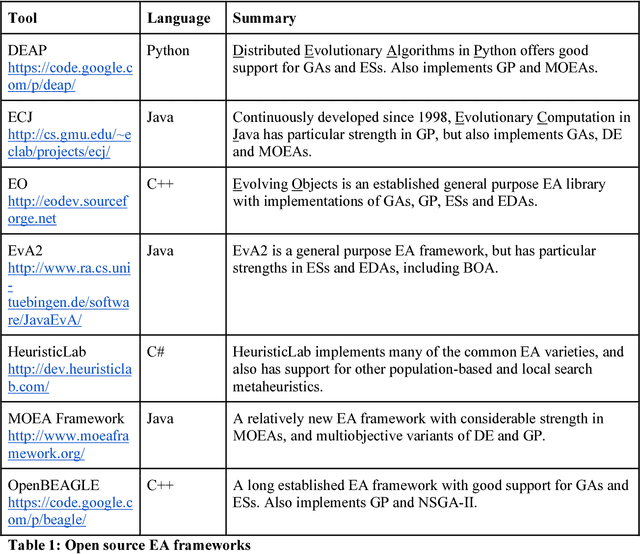
Evolutionary algorithms (EAs) are population-based metaheuristics, originally inspired by aspects of natural evolution. Modern varieties incorporate a broad mixture of search mechanisms, and tend to blend inspiration from nature with pragmatic engineering concerns; however, all EAs essentially operate by maintaining a population of potential solutions and in some way artificially 'evolving' that population over time. Particularly well-known categories of EAs include genetic algorithms (GAs), Genetic Programming (GP), and Evolution Strategies (ES). EAs have proven very successful in practical applications, particularly those requiring solutions to combinatorial problems. EAs are highly flexible and can be configured to address any optimization task, without the requirements for reformulation and/or simplification that would be needed for other techniques. However, this flexibility goes hand in hand with a cost: the tailoring of an EA's configuration and parameters, so as to provide robust performance for a given class of tasks, is often a complex and time-consuming process. This tailoring process is one of the many ongoing research areas associated with EAs.