 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeREFORMS: Reporting Standards for Machine Learning Based Science
Aug 15, 2023
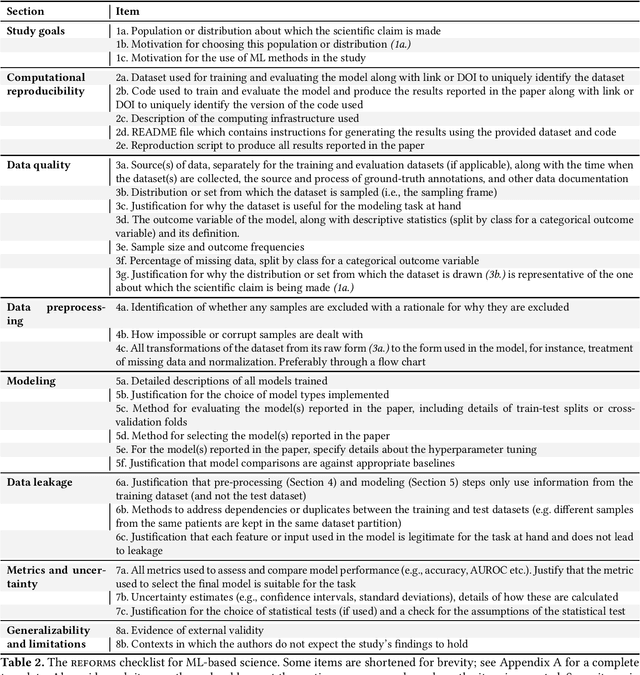
Machine learning (ML) methods are proliferating in scientific research. However, the adoption of these methods has been accompanied by failures of validity, reproducibility, and generalizability. These failures can hinder scientific progress, lead to false consensus around invalid claims, and undermine the credibility of ML-based science. ML methods are often applied and fail in similar ways across disciplines. Motivated by this observation, our goal is to provide clear reporting standards for ML-based science. Drawing from an extensive review of past literature, we present the REFORMS checklist ($\textbf{Re}$porting Standards $\textbf{For}$ $\textbf{M}$achine Learning Based $\textbf{S}$cience). It consists of 32 questions and a paired set of guidelines. REFORMS was developed based on a consensus of 19 researchers across computer science, data science, mathematics, social sciences, and biomedical sciences. REFORMS can serve as a resource for researchers when designing and implementing a study, for referees when reviewing papers, and for journals when enforcing standards for transparency and reproducibility.
Can Smartphone Co-locations Detect Friendship? It Depends How You Model It
Aug 31, 2020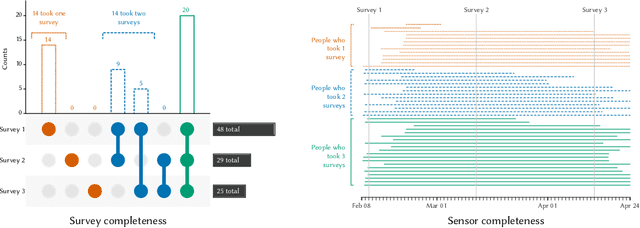
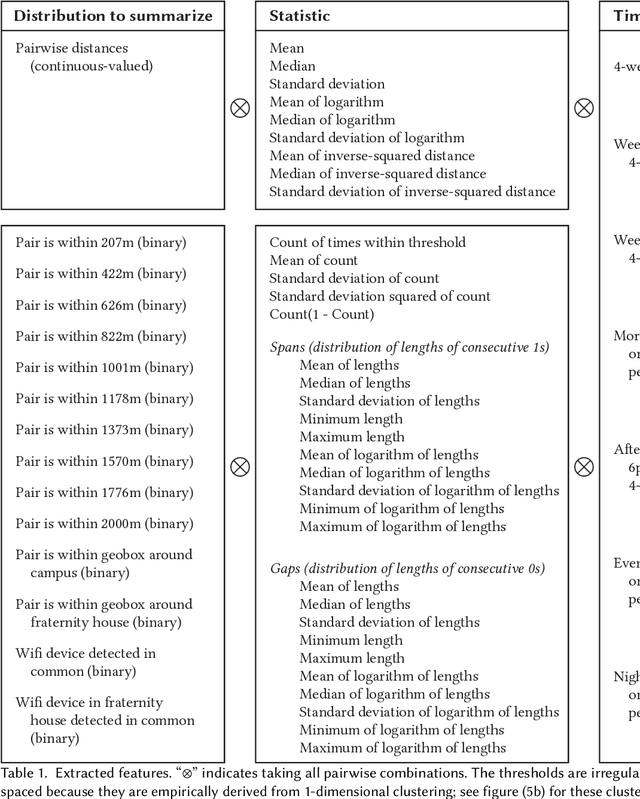
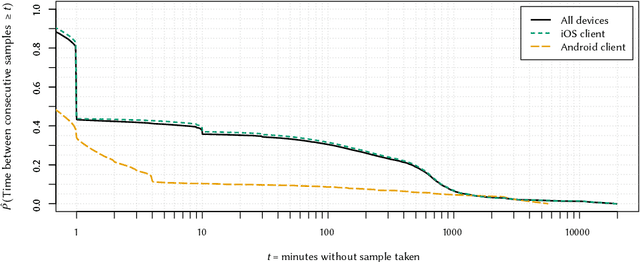
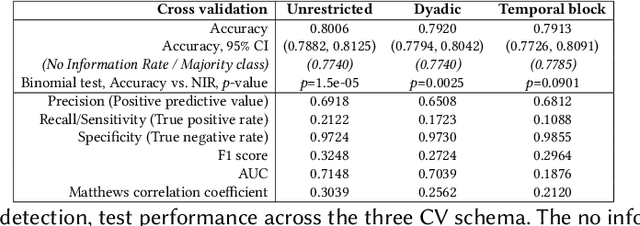
We present a study to detect friendship, its strength, and its change from smartphone location data collectedamong members of a fraternity. We extract a rich set of co-location features and build classifiers that detectfriendships and close friendship at 30% above a random baseline. We design cross-validation schema to testour model performance in specific application settings, finding it robust to seeing new dyads and to temporalvariance.
A Hierarchy of Limitations in Machine Learning
Feb 29, 2020



"All models are wrong, but some are useful", wrote George E. P. Box (1979). Machine learning has focused on the usefulness of probability models for prediction in social systems, but is only now coming to grips with the ways in which these models are wrong---and the consequences of those shortcomings. This paper attempts a comprehensive, structured overview of the specific conceptual, procedural, and statistical limitations of models in machine learning when applied to society. Machine learning modelers themselves can use the described hierarchy to identify possible failure points and think through how to address them, and consumers of machine learning models can know what to question when confronted with the decision about if, where, and how to apply machine learning. The limitations go from commitments inherent in quantification itself, through to showing how unmodeled dependencies can lead to cross-validation being overly optimistic as a way of assessing model performance.