 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe embrace of open science: An analysis of a decade of AI research and 56 800 conference papers
Jun 15, 2026The reproducibility crisis has directed the AI research community toward improving documentation practices. Several studies have identified methodological issues, and in response, the most impactful venues in the field have introduced reproducibility checklists. We seek to understand whether documentation practices have changed over time by assessing all published papers at five leading AI conferences over the past decade. Seven reproducibility variables were identified, quality-assured and used to analyse 56 800 publications. Our analysis reveals that in the period 2014 to 2024, documentation practices have improved; papers sharing both code and data increased nearly sixfold, from 11% to 64% Building on empirical reproducibility rates from a prior study, we estimate - inferred from documentation practices, not direct testing - that reproducibility increased from 28% in 2014 to 64% in 2024. Improvements in documentation practices predate the introduction of reproducibility checklists, suggesting these changes reflect a broader movement toward open science rather than a direct response to formal requirements.
Learning to be Reproducible: Custom Loss Design for Robust Neural Networks
Jan 02, 2026To enhance the reproducibility and reliability of deep learning models, we address a critical gap in current training methodologies: the lack of mechanisms that ensure consistent and robust performance across runs. Our empirical analysis reveals that even under controlled initialization and training conditions, the accuracy of the model can exhibit significant variability. To address this issue, we propose a Custom Loss Function (CLF) that reduces the sensitivity of training outcomes to stochastic factors such as weight initialization and data shuffling. By fine-tuning its parameters, CLF explicitly balances predictive accuracy with training stability, leading to more consistent and reliable model performance. Extensive experiments across diverse architectures for both image classification and time series forecasting demonstrate that our approach significantly improves training robustness without sacrificing predictive performance. These results establish CLF as an effective and efficient strategy for developing more stable, reliable and trustworthy neural networks.
Automated Reproducibility Has a Problem Statement Problem
Dec 30, 2025Background. Reproducibility is essential to the scientific method, but reproduction is often a laborious task. Recent works have attempted to automate this process and relieve researchers of this workload. However, due to varying definitions of reproducibility, a clear problem statement is missing. Objectives. Create a generalisable problem statement, applicable to any empirical study. We hypothesise that we can represent any empirical study using a structure based on the scientific method and that this representation can be automatically extracted from any publication, and captures the essence of the study. Methods. We apply our definition of reproducibility as a problem statement for the automatisation of reproducibility by automatically extracting the hypotheses, experiments and interpretations of 20 studies and assess the quality based on assessments by the original authors of each study. Results. We create a dataset representing the reproducibility problem, consisting of the representation of 20 studies. The majority of author feedback is positive, for all parts of the representation. In a few cases, our method failed to capture all elements of the study. We also find room for improvement at capturing specific details, such as results of experiments. Conclusions. We conclude that our formulation of the problem is able to capture the concept of reproducibility in empirical AI studies across a wide range of subfields. Authors of original publications generally agree that the produced structure is representative of their work; we believe improvements can be achieved by applying our findings to create a more structured and fine-grained output in future work.
The Unreasonable Effectiveness of Open Science in AI: A Replication Study
Dec 20, 2024



A reproducibility crisis has been reported in science, but the extent to which it affects AI research is not yet fully understood. Therefore, we performed a systematic replication study including 30 highly cited AI studies relying on original materials when available. In the end, eight articles were rejected because they required access to data or hardware that was practically impossible to acquire as part of the project. Six articles were successfully reproduced, while five were partially reproduced. In total, 50% of the articles included was reproduced to some extent. The availability of code and data correlate strongly with reproducibility, as 86% of articles that shared code and data were fully or partly reproduced, while this was true for 33% of articles that shared only data. The quality of the data documentation correlates with successful replication. Poorly documented or miss-specified data will probably result in unsuccessful replication. Surprisingly, the quality of the code documentation does not correlate with successful replication. Whether the code is poorly documented, partially missing, or not versioned is not important for successful replication, as long as the code is shared. This study emphasizes the effectiveness of open science and the importance of properly documenting data work.
Probing the Robustness of Time-series Forecasting Models with CounterfacTS
Mar 06, 2024



A common issue for machine learning models applied to time-series forecasting is the temporal evolution of the data distributions (i.e., concept drift). Because most of the training data does not reflect such changes, the models present poor performance on the new out-of-distribution scenarios and, therefore, the impact of such events cannot be reliably anticipated ahead of time. We present and publicly release CounterfacTS, a tool to probe the robustness of deep learning models in time-series forecasting tasks via counterfactuals. CounterfacTS has a user-friendly interface that allows the user to visualize, compare and quantify time series data and their forecasts, for a number of datasets and deep learning models. Furthermore, the user can apply various transformations to the time series and explore the resulting changes in the forecasts in an interpretable manner. Through example cases, we illustrate how CounterfacTS can be used to i) identify the main features characterizing and differentiating sets of time series, ii) assess how the model performance depends on these characateristics, and iii) guide transformations of the original time series to create counterfactuals with desired properties for training and increasing the forecasting performance in new regions of the data distribution. We discuss the importance of visualizing and considering the location of the data in a projected feature space to transform time-series and create effective counterfactuals for training the models. Overall, CounterfacTS aids at creating counterfactuals to efficiently explore the impact of hypothetical scenarios not covered by the original data in time-series forecasting tasks.
Examining the Effect of Implementation Factors on Deep Learning Reproducibility
Dec 11, 2023Reproducing published deep learning papers to validate their conclusions can be difficult due to sources of irreproducibility. We investigate the impact that implementation factors have on the results and how they affect reproducibility of deep learning studies. Three deep learning experiments were ran five times each on 13 different hardware environments and four different software environments. The analysis of the 780 combined results showed that there was a greater than 6% accuracy range on the same deterministic examples introduced from hardware or software environment variations alone. To account for these implementation factors, researchers should run their experiments multiple times in different hardware and software environments to verify their conclusions are not affected.
REFORMS: Reporting Standards for Machine Learning Based Science
Aug 15, 2023
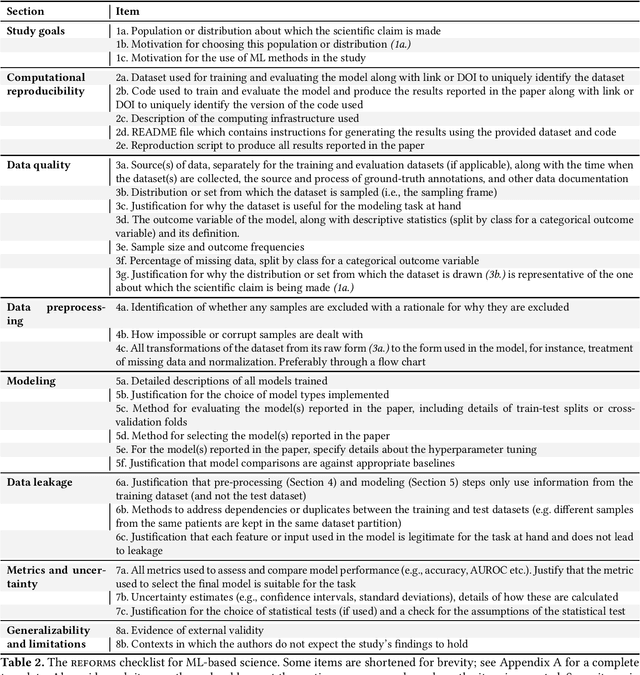
Machine learning (ML) methods are proliferating in scientific research. However, the adoption of these methods has been accompanied by failures of validity, reproducibility, and generalizability. These failures can hinder scientific progress, lead to false consensus around invalid claims, and undermine the credibility of ML-based science. ML methods are often applied and fail in similar ways across disciplines. Motivated by this observation, our goal is to provide clear reporting standards for ML-based science. Drawing from an extensive review of past literature, we present the REFORMS checklist ($\textbf{Re}$porting Standards $\textbf{For}$ $\textbf{M}$achine Learning Based $\textbf{S}$cience). It consists of 32 questions and a paired set of guidelines. REFORMS was developed based on a consensus of 19 researchers across computer science, data science, mathematics, social sciences, and biomedical sciences. REFORMS can serve as a resource for researchers when designing and implementing a study, for referees when reviewing papers, and for journals when enforcing standards for transparency and reproducibility.
Sources of Irreproducibility in Machine Learning: A Review
Apr 15, 2022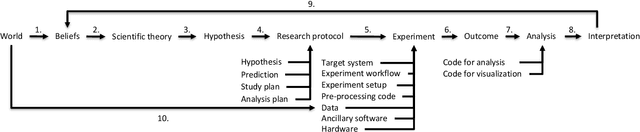
Lately, several benchmark studies have shown that the state of the art in some of the sub-fields of machine learning actually has not progressed despite progress being reported in the literature. The lack of progress is partly caused by the irreproducibility of many model comparison studies. Model comparison studies are conducted that do not control for many known sources of irreproducibility. This leads to results that cannot be verified by third parties. Our objective is to provide an overview of the sources of irreproducibility that are reported in the literature. We review the literature to provide an overview and a taxonomy in addition to a discussion on the identified sources of irreproducibility. Finally, we identify three lines of further inquiry.
The Fundamental Principles of Reproducibility
Nov 19, 2020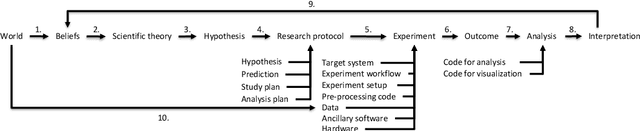
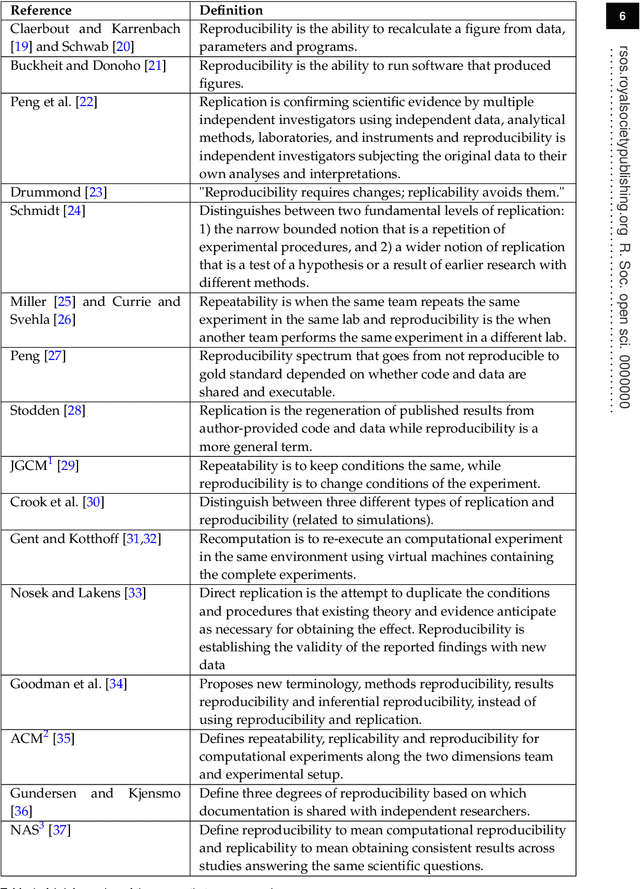
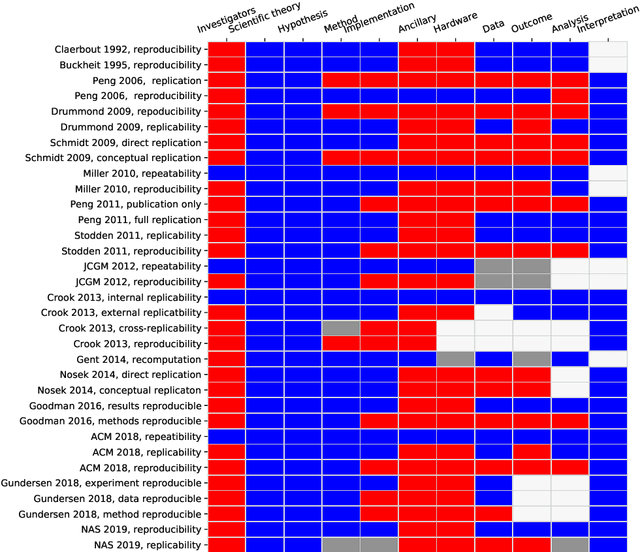
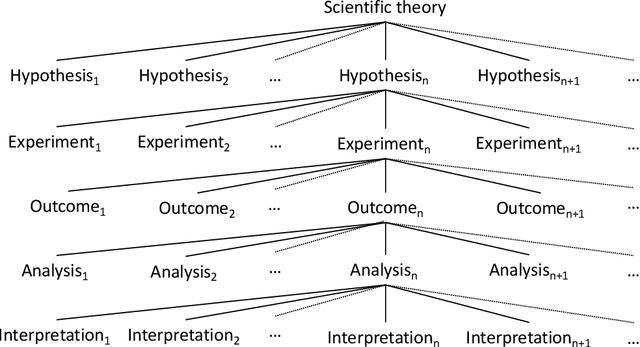
Reproducibility is a confused terminology. In this paper, I take a fundamental view on reproducibility rooted in the scientific method. The scientific method is analysed and characterised in order to develop the terminology required to define reproducibility. Further, the literature on reproducibility and replication is surveyed, and experiments are modeled as tasks and problem solving methods. Machine learning is used to exemplify the described approach. Based on the analysis, reproducibility is defined and three different types of reproducibility as well as four degrees of reproducibility are specified.