 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAI Benchmark Democratization and Carpentry
Dec 12, 2025Benchmarks are a cornerstone of modern machine learning, enabling reproducibility, comparison, and scientific progress. However, AI benchmarks are increasingly complex, requiring dynamic, AI-focused workflows. Rapid evolution in model architectures, scale, datasets, and deployment contexts makes evaluation a moving target. Large language models often memorize static benchmarks, causing a gap between benchmark results and real-world performance. Beyond traditional static benchmarks, continuous adaptive benchmarking frameworks are needed to align scientific assessment with deployment risks. This calls for skills and education in AI Benchmark Carpentry. From our experience with MLCommons, educational initiatives, and programs like the DOE's Trillion Parameter Consortium, key barriers include high resource demands, limited access to specialized hardware, lack of benchmark design expertise, and uncertainty in relating results to application domains. Current benchmarks often emphasize peak performance on top-tier hardware, offering limited guidance for diverse, real-world scenarios. Benchmarking must become dynamic, incorporating evolving models, updated data, and heterogeneous platforms while maintaining transparency, reproducibility, and interpretability. Democratization requires both technical innovation and systematic education across levels, building sustained expertise in benchmark design and use. Benchmarks should support application-relevant comparisons, enabling informed, context-sensitive decisions. Dynamic, inclusive benchmarking will ensure evaluation keeps pace with AI evolution and supports responsible, reproducible, and accessible AI deployment. Community efforts can provide a foundation for AI Benchmark Carpentry.
Examining the Effect of Implementation Factors on Deep Learning Reproducibility
Dec 11, 2023Reproducing published deep learning papers to validate their conclusions can be difficult due to sources of irreproducibility. We investigate the impact that implementation factors have on the results and how they affect reproducibility of deep learning studies. Three deep learning experiments were ran five times each on 13 different hardware environments and four different software environments. The analysis of the 780 combined results showed that there was a greater than 6% accuracy range on the same deterministic examples introduced from hardware or software environment variations alone. To account for these implementation factors, researchers should run their experiments multiple times in different hardware and software environments to verify their conclusions are not affected.
DataPerf: Benchmarks for Data-Centric AI Development
Jul 20, 2022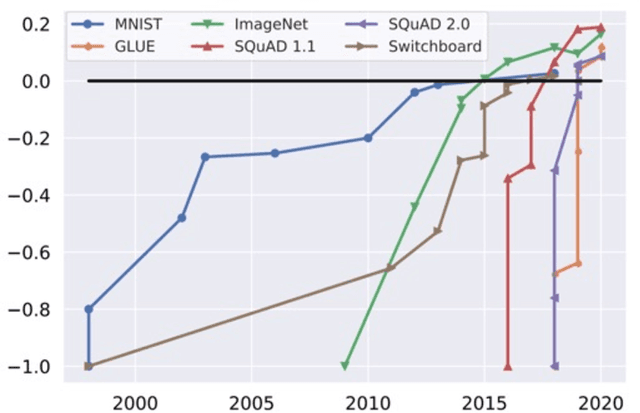
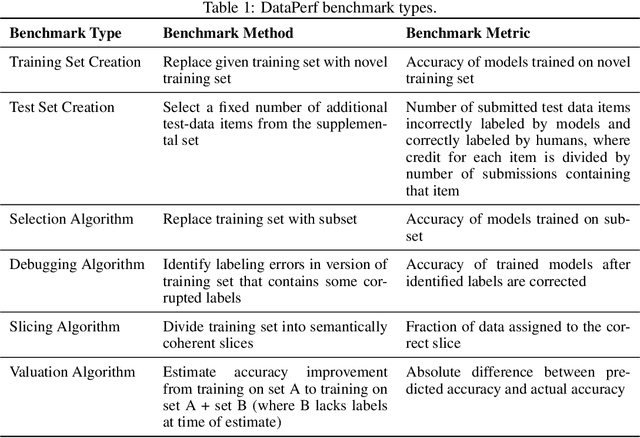
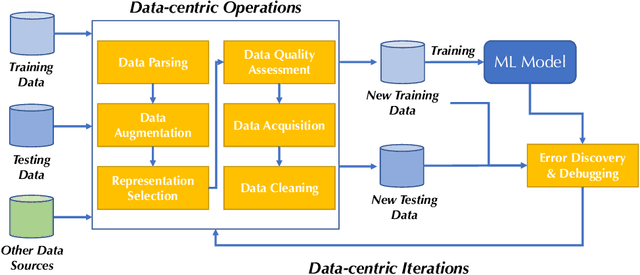
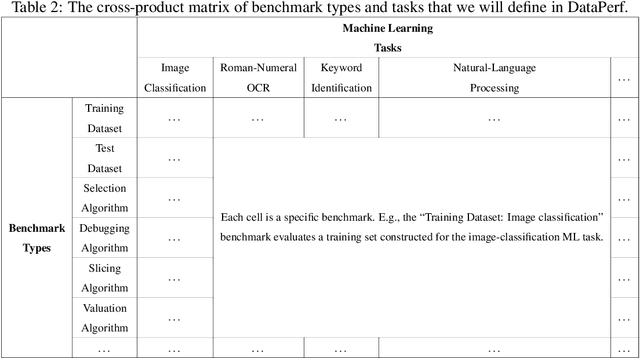
Machine learning (ML) research has generally focused on models, while the most prominent datasets have been employed for everyday ML tasks without regard for the breadth, difficulty, and faithfulness of these datasets to the underlying problem. Neglecting the fundamental importance of datasets has caused major problems involving data cascades in real-world applications and saturation of dataset-driven criteria for model quality, hindering research growth. To solve this problem, we present DataPerf, a benchmark package for evaluating ML datasets and dataset-working algorithms. We intend it to enable the "data ratchet," in which training sets will aid in evaluating test sets on the same problems, and vice versa. Such a feedback-driven strategy will generate a virtuous loop that will accelerate development of data-centric AI. The MLCommons Association will maintain DataPerf.