 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDMLR: Data-centric Machine Learning Research -- Past, Present and Future
Nov 21, 2023


Drawing from discussions at the inaugural DMLR workshop at ICML 2023 and meetings prior, in this report we outline the relevance of community engagement and infrastructure development for the creation of next-generation public datasets that will advance machine learning science. We chart a path forward as a collective effort to sustain the creation and maintenance of these datasets and methods towards positive scientific, societal and business impact.
DataPerf: Benchmarks for Data-Centric AI Development
Jul 20, 2022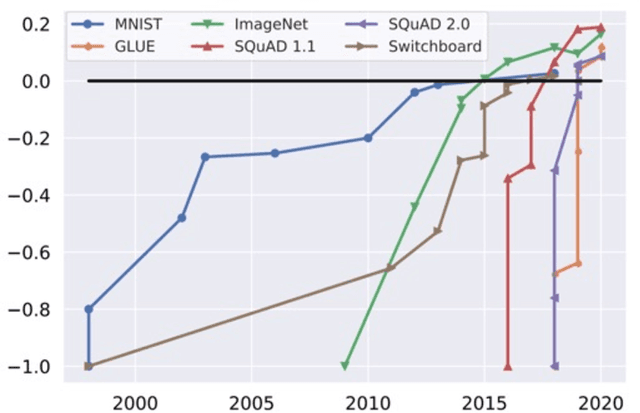
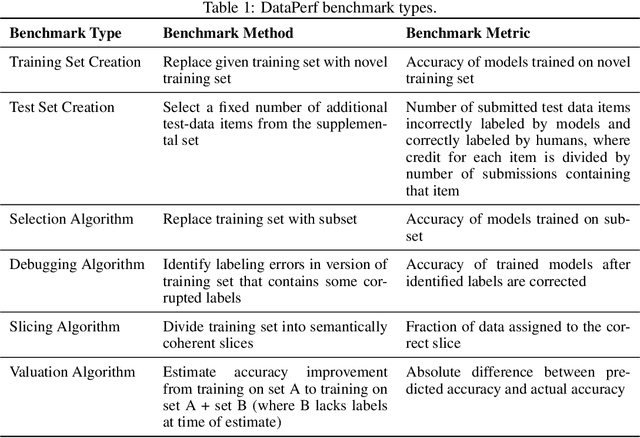
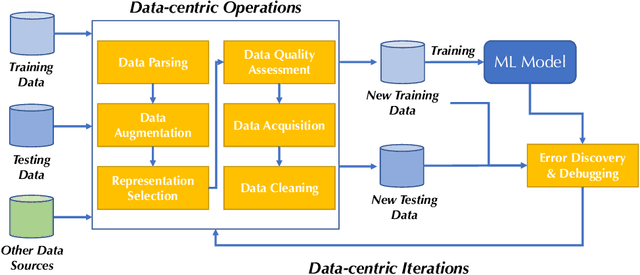
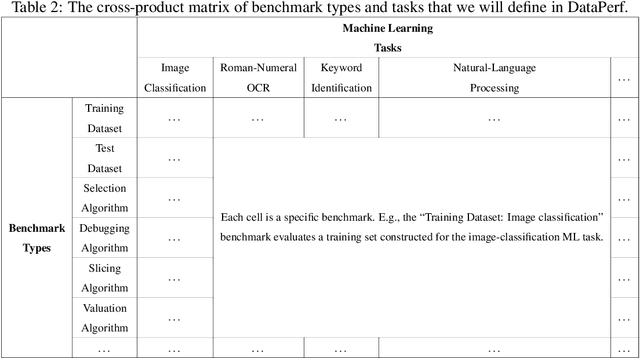
Machine learning (ML) research has generally focused on models, while the most prominent datasets have been employed for everyday ML tasks without regard for the breadth, difficulty, and faithfulness of these datasets to the underlying problem. Neglecting the fundamental importance of datasets has caused major problems involving data cascades in real-world applications and saturation of dataset-driven criteria for model quality, hindering research growth. To solve this problem, we present DataPerf, a benchmark package for evaluating ML datasets and dataset-working algorithms. We intend it to enable the "data ratchet," in which training sets will aid in evaluating test sets on the same problems, and vice versa. Such a feedback-driven strategy will generate a virtuous loop that will accelerate development of data-centric AI. The MLCommons Association will maintain DataPerf.
Data Debugging with Shapley Importance over End-to-End Machine Learning Pipelines
Apr 26, 2022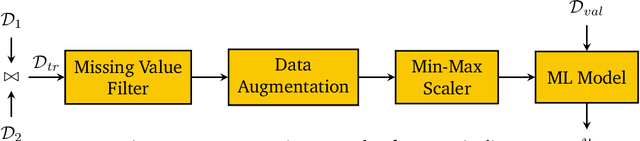
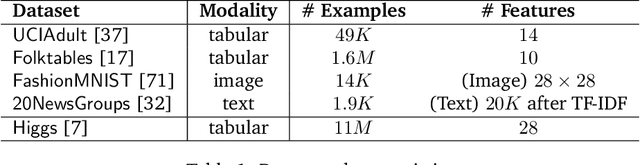
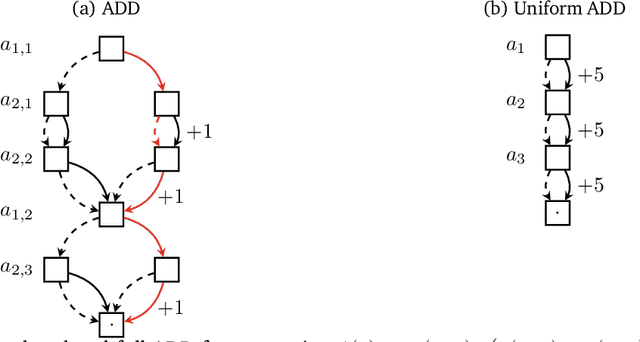
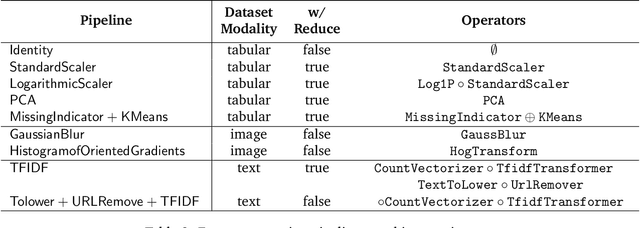
Developing modern machine learning (ML) applications is data-centric, of which one fundamental challenge is to understand the influence of data quality to ML training -- "Which training examples are 'guilty' in making the trained ML model predictions inaccurate or unfair?" Modeling data influence for ML training has attracted intensive interest over the last decade, and one popular framework is to compute the Shapley value of each training example with respect to utilities such as validation accuracy and fairness of the trained ML model. Unfortunately, despite recent intensive interest and research, existing methods only consider a single ML model "in isolation" and do not consider an end-to-end ML pipeline that consists of data transformations, feature extractors, and ML training. We present DataScope (ease.ml/datascope), the first system that efficiently computes Shapley values of training examples over an end-to-end ML pipeline, and illustrate its applications in data debugging for ML training. To this end, we first develop a novel algorithmic framework that computes Shapley value over a specific family of ML pipelines that we call canonical pipelines: a positive relational algebra query followed by a K-nearest-neighbor (KNN) classifier. We show that, for many subfamilies of canonical pipelines, computing Shapley value is in PTIME, contrasting the exponential complexity of computing Shapley value in general. We then put this to practice -- given an sklearn pipeline, we approximate it with a canonical pipeline to use as a proxy. We conduct extensive experiments illustrating different use cases and utilities. Our results show that DataScope is up to four orders of magnitude faster over state-of-the-art Monte Carlo-based methods, while being comparably, and often even more, effective in data debugging.
A Data Quality-Driven View of MLOps
Feb 15, 2021

Developing machine learning models can be seen as a process similar to the one established for traditional software development. A key difference between the two lies in the strong dependency between the quality of a machine learning model and the quality of the data used to train or perform evaluations. In this work, we demonstrate how different aspects of data quality propagate through various stages of machine learning development. By performing a joint analysis of the impact of well-known data quality dimensions and the downstream machine learning process, we show that different components of a typical MLOps pipeline can be efficiently designed, providing both a technical and theoretical perspective.
Online Active Model Selection for Pre-trained Classifiers
Oct 21, 2020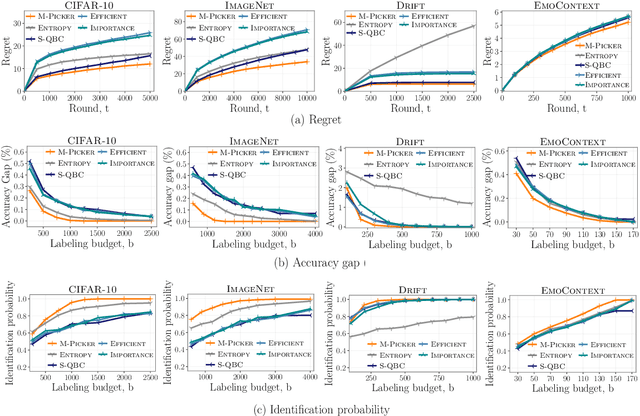

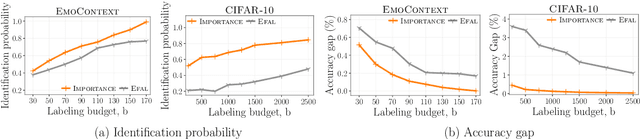
Given $k$ pre-trained classifiers and a stream of unlabeled data examples, how can we actively decide when to query a label so that we can distinguish the best model from the rest while making a small number of queries? Answering this question has a profound impact on a range of practical scenarios. In this work, we design an online selective sampling approach that actively selects informative examples to label and outputs the best model with high probability at any round. Our algorithm can be used for online prediction tasks for both adversarial and stochastic streams. We establish several theoretical guarantees for our algorithm and extensively demonstrate its effectiveness in our experimental studies.
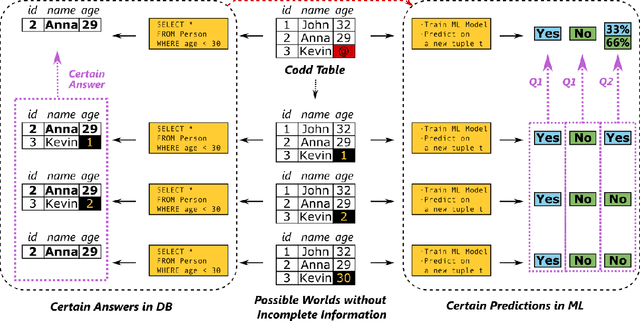
Nearest Neighbor Classifiers over Incomplete Information: From Certain Answers to Certain Predictions
May 12, 2020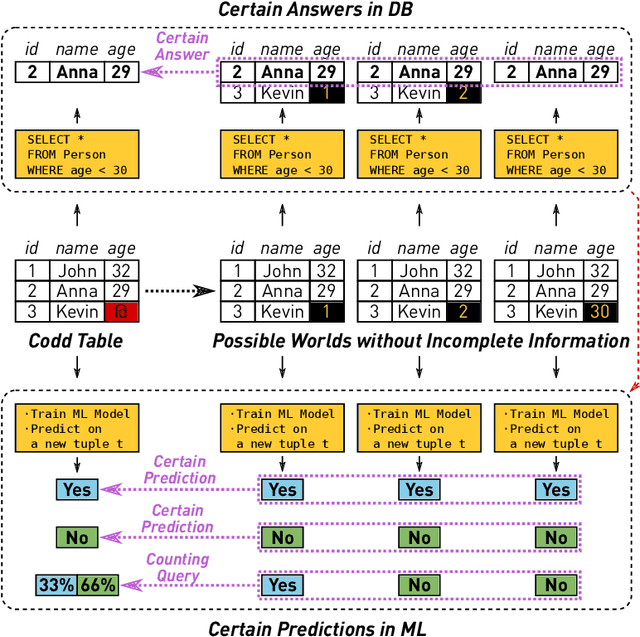
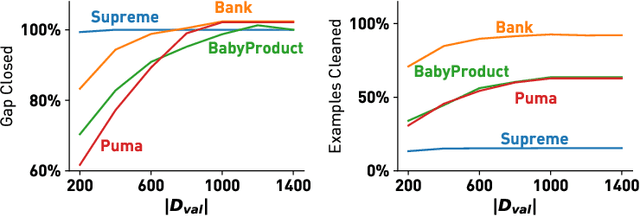
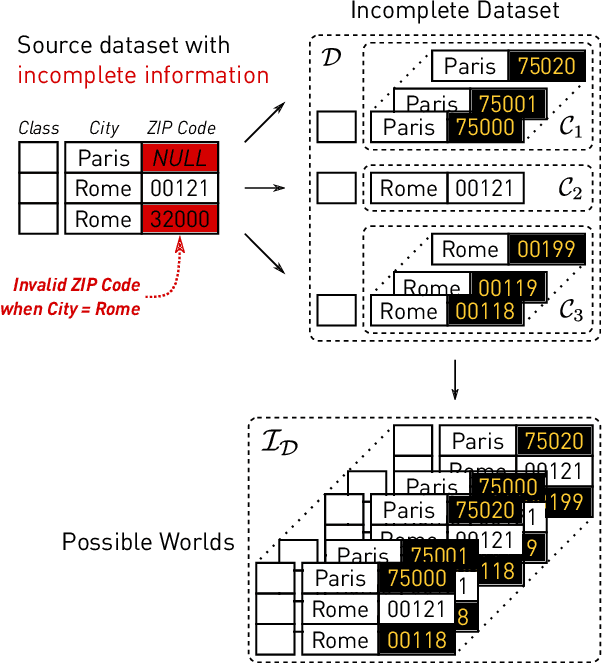
Machine learning (ML) applications have been thriving recently, largely attributed to the increasing availability of data. However, inconsistency and incomplete information are ubiquitous in real-world datasets, and their impact on ML applications remains elusive. In this paper, we present a formal study of this impact by extending the notion of Certain Answers for Codd tables, which has been explored by the database research community for decades, into the field of machine learning. Specifically, we focus on classification problems and propose the notion of "Certain Predictions" (CP) -- a test data example can be certainly predicted (CP'ed) if all possible classifiers trained on top of all possible worlds induced by the incompleteness of data would yield the same prediction. We study two fundamental CP queries: (Q1) checking query that determines whether a data example can be CP'ed; and (Q2) counting query that computes the number of classifiers that support a particular prediction (i.e., label). Given that general solutions to CP queries are, not surprisingly, hard without assumption over the type of classifier, we further present a case study in the context of nearest neighbor (NN) classifiers, where efficient solutions to CP queries can be developed -- we show that it is possible to answer both queries in linear or polynomial time over exponentially many possible worlds. We demonstrate one example use case of CP in the important application of "data cleaning for machine learning (DC for ML)." We show that our proposed CPClean approach built based on CP can often significantly outperform existing techniques in terms of classification accuracy with mild manual cleaning effort.
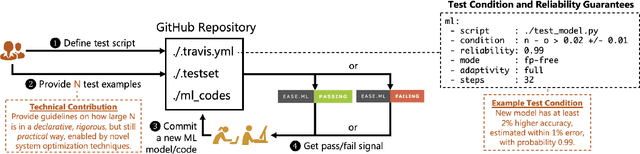
Continuous Integration of Machine Learning Models with ease.ml/ci: Towards a Rigorous Yet Practical Treatment
Mar 01, 2019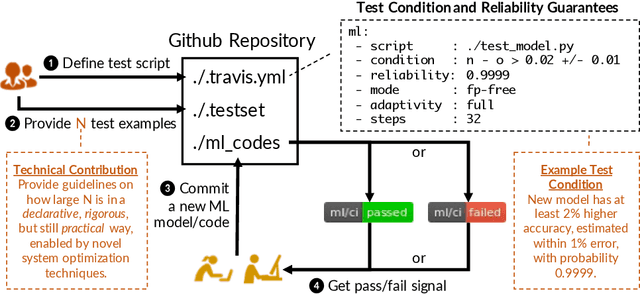
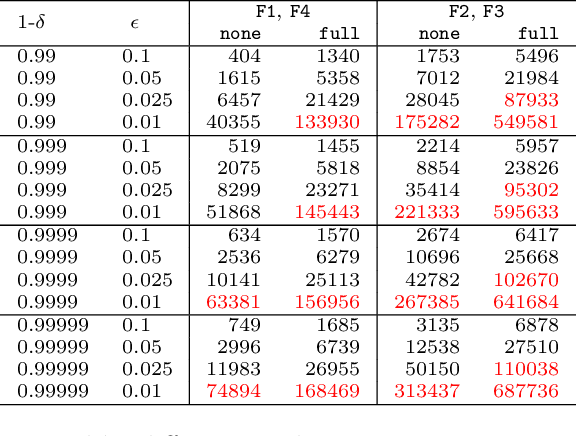
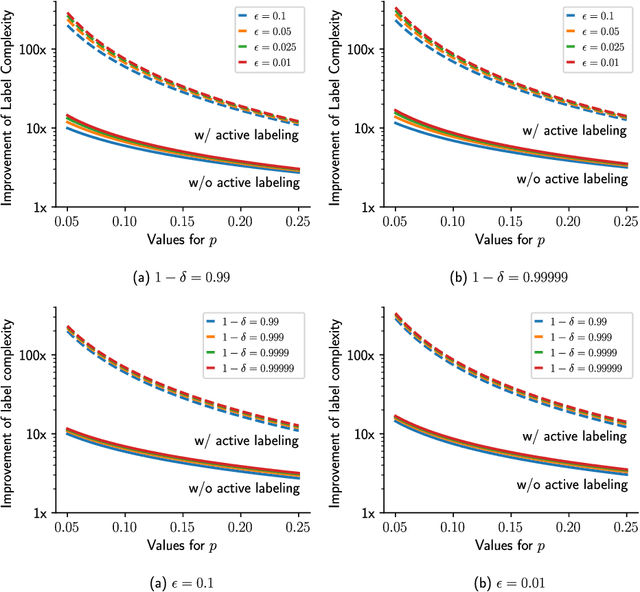
Continuous integration is an indispensable step of modern software engineering practices to systematically manage the life cycles of system development. Developing a machine learning model is no difference - it is an engineering process with a life cycle, including design, implementation, tuning, testing, and deployment. However, most, if not all, existing continuous integration engines do not support machine learning as first-class citizens. In this paper, we present ease.ml/ci, to our best knowledge, the first continuous integration system for machine learning. The challenge of building ease.ml/ci is to provide rigorous guarantees, e.g., single accuracy point error tolerance with 0.999 reliability, with a practical amount of labeling effort, e.g., 2K labels per test. We design a domain specific language that allows users to specify integration conditions with reliability constraints, and develop simple novel optimizations that can lower the number of labels required by up to two orders of magnitude for test conditions popularly used in real production systems.