 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeResidual Decoding: Mitigating Hallucinations in Large Vision-Language Models via History-Aware Residual Guidance
Feb 01, 2026Large Vision-Language Models (LVLMs) can reason effectively from image-text inputs and perform well in various multimodal tasks. Despite this success, they are affected by language priors and often produce hallucinations. Hallucinations denote generated content that is grammatically and syntactically coherent, yet bears no match or direct relevance to actual visual input. To address this problem, we propose Residual Decoding (ResDec). It is a novel training-free method that uses historical information to aid decoding. The method relies on the internal implicit reasoning mechanism and token logits evolution mechanism of LVLMs to correct biases. Extensive experiments demonstrate that ResDec effectively suppresses hallucinations induced by language priors, significantly improves visual grounding, and reduces object hallucinations. In addition to mitigating hallucinations, ResDec also performs exceptionally well on comprehensive LVLM benchmarks, highlighting its broad applicability.
BrainFuse: a unified infrastructure integrating realistic biological modeling and core AI methodology
Jan 29, 2026Neuroscience and artificial intelligence represent distinct yet complementary pathways to general intelligence. However, amid the ongoing boom in AI research and applications, the translational synergy between these two fields has grown increasingly elusive-hampered by a widening infrastructural incompatibility: modern AI frameworks lack native support for biophysical realism, while neural simulation tools are poorly suited for gradient-based optimization and neuromorphic hardware deployment. To bridge this gap, we introduce BrainFuse, a unified infrastructure that provides comprehensive support for biophysical neural simulation and gradient-based learning. By addressing algorithmic, computational, and deployment challenges, BrainFuse exhibits three core capabilities: (1) algorithmic integration of detailed neuronal dynamics into a differentiable learning framework; (2) system-level optimization that accelerates customizable ion-channel dynamics by up to 3,000x on GPUs; and (3) scalable computation with highly compatible pipelines for neuromorphic hardware deployment. We demonstrate this full-stack design through both AI and neuroscience tasks, from foundational neuron simulation and functional cylinder modeling to real-world deployment and application scenarios. For neuroscience, BrainFuse supports multiscale biological modeling, enabling the deployment of approximately 38,000 Hodgkin-Huxley neurons with 100 million synapses on a single neuromorphic chip while consuming as low as 1.98 W. For AI, BrainFuse facilitates the synergistic application of realistic biological neuron models, demonstrating enhanced robustness to input noise and improved temporal processing endowed by complex HH dynamics. BrainFuse therefore serves as a foundational engine to facilitate cross-disciplinary research and accelerate the development of next-generation bio-inspired intelligent systems.
LLMs as Orchestrators: Constraint-Compliant Multi-Agent Optimization for Recommendation Systems
Jan 27, 2026Recommendation systems must optimize multiple objectives while satisfying hard business constraints such as fairness and coverage. For example, an e-commerce platform may require every recommendation list to include items from multiple sellers and at least one newly listed product; violating such constraints--even once--is unacceptable in production. Prior work on multi-objective recommendation and recent LLM-based recommender agents largely treat constraints as soft penalties or focus on item scoring and interaction, leading to frequent violations in real-world deployments. How to leverage LLMs for coordinating constrained optimization in recommendation systems remains underexplored. We propose DualAgent-Rec, an LLM-coordinated dual-agent framework for constrained multi-objective e-commerce recommendation. The framework separates optimization into an Exploitation Agent that prioritizes accuracy under hard constraints and an Exploration Agent that promotes diversity through unconstrained Pareto search. An LLM-based coordinator adaptively allocates resources between agents based on optimization progress and constraint satisfaction, while an adaptive epsilon-relaxation mechanism guarantees feasibility of final solutions. Experiments on the Amazon Reviews 2023 dataset demonstrate that DualAgent-Rec achieves 100% constraint satisfaction and improves Pareto hypervolume by 4-6% over strong baselines, while maintaining competitive accuracy-diversity trade-offs. These results indicate that LLMs can act as effective orchestration agents for deployable and constraint-compliant recommendation systems.
RobustExplain: Evaluating Robustness of LLM-Based Explanation Agents for Recommendation
Jan 27, 2026Large Language Models (LLMs) are increasingly used to generate natural-language explanations in recommender systems, acting as explanation agents that reason over user behavior histories. While prior work has focused on explanation fluency and relevance under fixed inputs, the robustness of LLM-generated explanations to realistic user behavior noise remains largely unexplored. In real-world web platforms, interaction histories are inherently noisy due to accidental clicks, temporal inconsistencies, missing values, and evolving preferences, raising concerns about explanation stability and user trust. We present RobustExplain, the first systematic evaluation framework for measuring the robustness of LLM-generated recommendation explanations. RobustExplain introduces five realistic user behavior perturbations evaluated across multiple severity levels and a multi-dimensional robustness metric capturing semantic, keyword, structural, and length consistency. Our goal is to establish a principled, task-level evaluation framework and initial robustness baselines, rather than to provide a comprehensive leaderboard across all available LLMs. Experiments on four representative LLMs (7B--70B) show that current models exhibit only moderate robustness, with larger models achieving up to 8% higher stability. Our results establish the first robustness benchmarks for explanation agents and highlight robustness as a critical dimension for trustworthy, agent-driven recommender systems at web scale.
StackPlanner: A Centralized Hierarchical Multi-Agent System with Task-Experience Memory Management
Jan 09, 2026Multi-agent systems based on large language models, particularly centralized architectures, have recently shown strong potential for complex and knowledge-intensive tasks. However, central agents often suffer from unstable long-horizon collaboration due to the lack of memory management, leading to context bloat, error accumulation, and poor cross-task generalization. To address both task-level memory inefficiency and the inability to reuse coordination experience, we propose StackPlanner, a hierarchical multi-agent framework with explicit memory control. StackPlanner addresses these challenges by decoupling high-level coordination from subtask execution with active task-level memory control, and by learning to retrieve and exploit reusable coordination experience via structured experience memory and reinforcement learning. Experiments on multiple deep-search and agent system benchmarks demonstrate the effectiveness of our approach in enabling reliable long-horizon multi-agent collaboration.
FOREVER: Forgetting Curve-Inspired Memory Replay for Language Model Continual Learning
Jan 07, 2026Continual learning (CL) for large language models (LLMs) aims to enable sequential knowledge acquisition without catastrophic forgetting. Memory replay methods are widely used for their practicality and effectiveness, but most rely on fixed, step-based heuristics that often misalign with the model's actual learning progress, since identical training steps can result in varying degrees of parameter change. Motivated by recent findings that LLM forgetting mirrors the Ebbinghaus human forgetting curve, we propose FOREVER (FORgEtting curVe-inspired mEmory Replay), a novel CL framework that aligns replay schedules with a model-centric notion of time. FOREVER defines model time using the magnitude of optimizer updates, allowing forgetting curve-inspired replay intervals to align with the model's internal evolution rather than raw training steps. Building on this approach, FOREVER incorporates a forgetting curve-based replay scheduler to determine when to replay and an intensity-aware regularization mechanism to adaptively control how to replay. Extensive experiments on three CL benchmarks and models ranging from 0.6B to 13B parameters demonstrate that FOREVER consistently mitigates catastrophic forgetting.
Bridging Global Intent with Local Details: A Hierarchical Representation Approach for Semantic Validation in Text-to-SQL
Dec 28, 2025Text-to-SQL translates natural language questions into SQL statements grounded in a target database schema. Ensuring the reliability and executability of such systems requires validating generated SQL, but most existing approaches focus only on syntactic correctness, with few addressing semantic validation (detecting misalignments between questions and SQL). As a consequence, effective semantic validation still faces two key challenges: capturing both global user intent and SQL structural details, and constructing high-quality fine-grained sub-SQL annotations. To tackle these, we introduce HEROSQL, a hierarchical SQL representation approach that integrates global intent (via Logical Plans, LPs) and local details (via Abstract Syntax Trees, ASTs). To enable better information propagation, we employ a Nested Message Passing Neural Network (NMPNN) to capture inherent relational information in SQL and aggregate schema-guided semantics across LPs and ASTs. Additionally, to generate high-quality negative samples, we propose an AST-driven sub-SQL augmentation strategy, supporting robust optimization of fine-grained semantic inconsistencies. Extensive experiments conducted on Text-to-SQL validation benchmarks (both in-domain and out-of-domain settings) demonstrate that our approach outperforms existing state-of-the-art methods, achieving an average 9.40% improvement of AUPRC and 12.35% of AUROC in identifying semantic inconsistencies. It excels at detecting fine-grained semantic errors, provides large language models with more granular feedback, and ultimately enhances the reliability and interpretability of data querying platforms.
Qwen Look Again: Guiding Vision-Language Reasoning Models to Re-attention Visual Information
May 29, 2025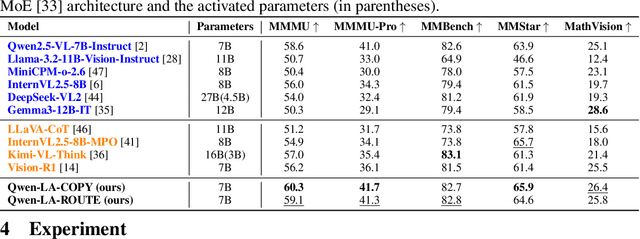
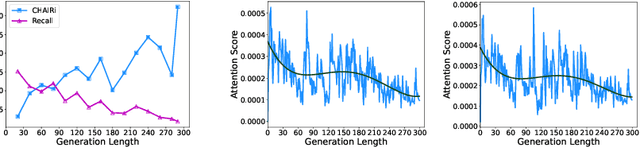
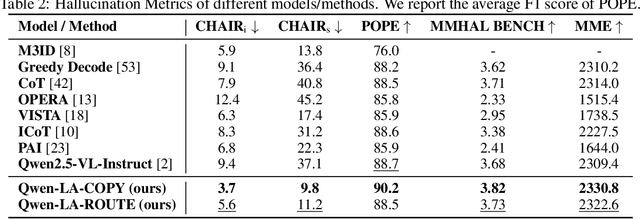
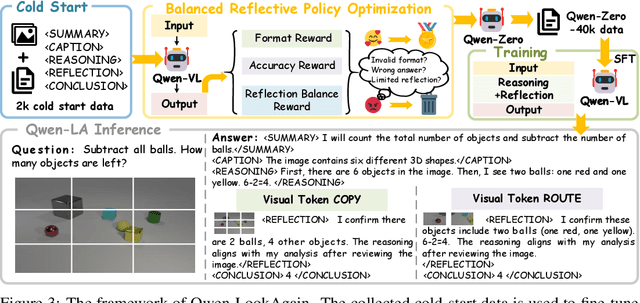
Inference time scaling drives extended reasoning to enhance the performance of Vision-Language Models (VLMs), thus forming powerful Vision-Language Reasoning Models (VLRMs). However, long reasoning dilutes visual tokens, causing visual information to receive less attention and may trigger hallucinations. Although introducing text-only reflection processes shows promise in language models, we demonstrate that it is insufficient to suppress hallucinations in VLMs. To address this issue, we introduce Qwen-LookAgain (Qwen-LA), a novel VLRM designed to mitigate hallucinations by incorporating a vision-text reflection process that guides the model to re-attention visual information during reasoning. We first propose a reinforcement learning method Balanced Reflective Policy Optimization (BRPO), which guides the model to decide when to generate vision-text reflection on its own and balance the number and length of reflections. Then, we formally prove that VLRMs lose attention to visual tokens as reasoning progresses, and demonstrate that supplementing visual information during reflection enhances visual attention. Therefore, during training and inference, Visual Token COPY and Visual Token ROUTE are introduced to force the model to re-attention visual information at the visual level, addressing the limitations of text-only reflection. Experiments on multiple visual QA datasets and hallucination metrics indicate that Qwen-LA achieves leading accuracy performance while reducing hallucinations. Our code is available at: https://github.com/Liar406/Look_Again.
LearNAT: Learning NL2SQL with AST-guided Task Decomposition for Large Language Models
Apr 03, 2025Natural Language to SQL (NL2SQL) has emerged as a critical task for enabling seamless interaction with databases. Recent advancements in Large Language Models (LLMs) have demonstrated remarkable performance in this domain. However, existing NL2SQL methods predominantly rely on closed-source LLMs leveraging prompt engineering, while open-source models typically require fine-tuning to acquire domain-specific knowledge. Despite these efforts, open-source LLMs struggle with complex NL2SQL tasks due to the indirect expression of user query objectives and the semantic gap between user queries and database schemas. Inspired by the application of reinforcement learning in mathematical problem-solving to encourage step-by-step reasoning in LLMs, we propose LearNAT (Learning NL2SQL with AST-guided Task Decomposition), a novel framework that improves the performance of open-source LLMs on complex NL2SQL tasks through task decomposition and reinforcement learning. LearNAT introduces three key components: (1) a Decomposition Synthesis Procedure that leverages Abstract Syntax Trees (ASTs) to guide efficient search and pruning strategies for task decomposition, (2) Margin-aware Reinforcement Learning, which employs fine-grained step-level optimization via DPO with AST margins, and (3) Adaptive Demonstration Reasoning, a mechanism for dynamically selecting relevant examples to enhance decomposition capabilities. Extensive experiments on two benchmark datasets, Spider and BIRD, demonstrate that LearNAT enables a 7B-parameter open-source LLM to achieve performance comparable to GPT-4, while offering improved efficiency and accessibility.
GeoEdit: Geometric Knowledge Editing for Large Language Models
Feb 27, 2025Regular updates are essential for maintaining up-to-date knowledge in large language models (LLMs). Consequently, various model editing methods have been developed to update specific knowledge within LLMs. However, training-based approaches often struggle to effectively incorporate new knowledge while preserving unrelated general knowledge. To address this challenge, we propose a novel framework called Geometric Knowledge Editing (GeoEdit). GeoEdit utilizes the geometric relationships of parameter updates from fine-tuning to differentiate between neurons associated with new knowledge updates and those related to general knowledge perturbations. By employing a direction-aware knowledge identification method, we avoid updating neurons with directions approximately orthogonal to existing knowledge, thus preserving the model's generalization ability. For the remaining neurons, we integrate both old and new knowledge for aligned directions and apply a "forget-then-learn" editing strategy for opposite directions. Additionally, we introduce an importance-guided task vector fusion technique that filters out redundant information and provides adaptive neuron-level weighting, further enhancing model editing performance. Extensive experiments on two publicly available datasets demonstrate the superiority of GeoEdit over existing state-of-the-art methods.