 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeoEdit: Geometric Knowledge Editing for Large Language Models
Feb 27, 2025Regular updates are essential for maintaining up-to-date knowledge in large language models (LLMs). Consequently, various model editing methods have been developed to update specific knowledge within LLMs. However, training-based approaches often struggle to effectively incorporate new knowledge while preserving unrelated general knowledge. To address this challenge, we propose a novel framework called Geometric Knowledge Editing (GeoEdit). GeoEdit utilizes the geometric relationships of parameter updates from fine-tuning to differentiate between neurons associated with new knowledge updates and those related to general knowledge perturbations. By employing a direction-aware knowledge identification method, we avoid updating neurons with directions approximately orthogonal to existing knowledge, thus preserving the model's generalization ability. For the remaining neurons, we integrate both old and new knowledge for aligned directions and apply a "forget-then-learn" editing strategy for opposite directions. Additionally, we introduce an importance-guided task vector fusion technique that filters out redundant information and provides adaptive neuron-level weighting, further enhancing model editing performance. Extensive experiments on two publicly available datasets demonstrate the superiority of GeoEdit over existing state-of-the-art methods.
GEMeX: A Large-Scale, Groundable, and Explainable Medical VQA Benchmark for Chest X-ray Diagnosis
Nov 25, 2024



Medical Visual Question Answering (VQA) is an essential technology that integrates computer vision and natural language processing to automatically respond to clinical inquiries about medical images. However, current medical VQA datasets exhibit two significant limitations: (1) they often lack visual and textual explanations for answers, which impedes their ability to satisfy the comprehension needs of patients and junior doctors; (2) they typically offer a narrow range of question formats, inadequately reflecting the diverse requirements encountered in clinical scenarios. These limitations pose significant challenges to the development of a reliable and user-friendly Med-VQA system. To address these challenges, we introduce a large-scale, Groundable, and Explainable Medical VQA benchmark for chest X-ray diagnosis (GEMeX), featuring several innovative components: (1) A multi-modal explainability mechanism that offers detailed visual and textual explanations for each question-answer pair, thereby enhancing answer comprehensibility; (2) Four distinct question types, open-ended, closed-ended, single-choice, and multiple-choice, that better reflect diverse clinical needs. We evaluated 10 representative large vision language models on GEMeX and found that they underperformed, highlighting the dataset's complexity. However, after fine-tuning a baseline model using the training set, we observed a significant performance improvement, demonstrating the dataset's effectiveness. The project is available at www.med-vqa.com/GEMeX.
Diversity-grounded Channel Prototypical Learning for Out-of-Distribution Intent Detection
Sep 17, 2024In the realm of task-oriented dialogue systems, a robust intent detection mechanism must effectively handle malformed utterances encountered in real-world scenarios. This study presents a novel fine-tuning framework for large language models (LLMs) aimed at enhancing in-distribution (ID) intent classification and out-of-distribution (OOD) intent detection, which utilizes semantic matching with prototypes derived from ID class names. By harnessing the highly distinguishable representations of LLMs, we construct semantic prototypes for each ID class using a diversity-grounded prompt tuning approach. We rigorously test our framework in a challenging OOD context, where ID and OOD classes are semantically close yet distinct, referred to as \emph{near} OOD detection. For a thorough assessment, we benchmark our method against the prevalent fine-tuning approaches. The experimental findings reveal that our method demonstrates superior performance in both few-shot ID intent classification and near-OOD intent detection tasks.
Towards LLM-driven Dialogue State Tracking
Oct 23, 2023



Dialogue State Tracking (DST) is of paramount importance in ensuring accurate tracking of user goals and system actions within task-oriented dialogue systems. The emergence of large language models (LLMs) such as GPT3 and ChatGPT has sparked considerable interest in assessing their efficacy across diverse applications. In this study, we conduct an initial examination of ChatGPT's capabilities in DST. Our evaluation uncovers the exceptional performance of ChatGPT in this task, offering valuable insights to researchers regarding its capabilities and providing useful directions for designing and enhancing dialogue systems. Despite its impressive performance, ChatGPT has significant limitations including its closed-source nature, request restrictions, raising data privacy concerns, and lacking local deployment capabilities. To address these concerns, we present LDST, an LLM-driven DST framework based on smaller, open-source foundation models. By utilizing a novel domain-slot instruction tuning method, LDST achieves performance on par with ChatGPT. Comprehensive evaluations across three distinct experimental settings, we find that LDST exhibits remarkable performance improvements in both zero-shot and few-shot setting compared to previous SOTA methods. The source code is provided for reproducibility.
How Good Are Large Language Models at Out-of-Distribution Detection?
Aug 23, 2023
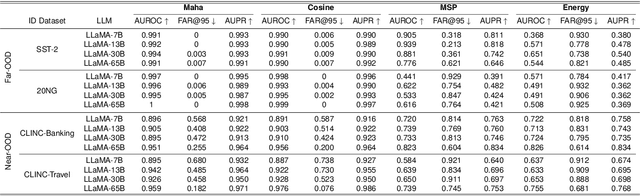
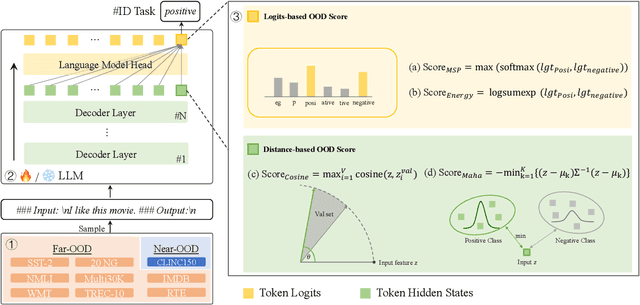
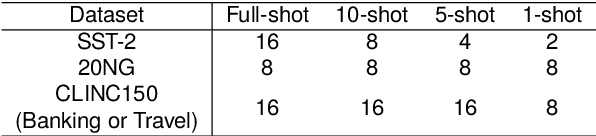
Out-of-distribution (OOD) detection plays a vital role in enhancing the reliability of machine learning (ML) models. The emergence of large language models (LLMs) has catalyzed a paradigm shift within the ML community, showcasing their exceptional capabilities across diverse natural language processing tasks. While existing research has probed OOD detection with relative small-scale Transformers like BERT, RoBERTa and GPT-2, the stark differences in scales, pre-training objectives, and inference paradigms call into question the applicability of these findings to LLMs. This paper embarks on a pioneering empirical investigation of OOD detection in the domain of LLMs, focusing on LLaMA series ranging from 7B to 65B in size. We thoroughly evaluate commonly-used OOD detectors, scrutinizing their performance in both zero-grad and fine-tuning scenarios. Notably, we alter previous discriminative in-distribution fine-tuning into generative fine-tuning, aligning the pre-training objective of LLMs with downstream tasks. Our findings unveil that a simple cosine distance OOD detector demonstrates superior efficacy, outperforming other OOD detectors. We provide an intriguing explanation for this phenomenon by highlighting the isotropic nature of the embedding spaces of LLMs, which distinctly contrasts with the anisotropic property observed in smaller BERT family models. The new insight enhances our understanding of how LLMs detect OOD data, thereby enhancing their adaptability and reliability in dynamic environments.
Revisit Few-shot Intent Classification with PLMs: Direct Fine-tuning vs. Continual Pre-training
Jun 08, 2023We consider the task of few-shot intent detection, which involves training a deep learning model to classify utterances based on their underlying intents using only a small amount of labeled data. The current approach to address this problem is through continual pre-training, i.e., fine-tuning pre-trained language models (PLMs) on external resources (e.g., conversational corpora, public intent detection datasets, or natural language understanding datasets) before using them as utterance encoders for training an intent classifier. In this paper, we show that continual pre-training may not be essential, since the overfitting problem of PLMs on this task may not be as serious as expected. Specifically, we find that directly fine-tuning PLMs on only a handful of labeled examples already yields decent results compared to methods that employ continual pre-training, and the performance gap diminishes rapidly as the number of labeled data increases. To maximize the utilization of the limited available data, we propose a context augmentation method and leverage sequential self-distillation to boost performance. Comprehensive experiments on real-world benchmarks show that given only two or more labeled samples per class, direct fine-tuning outperforms many strong baselines that utilize external data sources for continual pre-training. The code can be found at https://github.com/hdzhang-code/DFTPlus.
Fine-tuning Pre-trained Language Models for Few-shot Intent Detection: Supervised Pre-training and Isotropization
May 15, 2022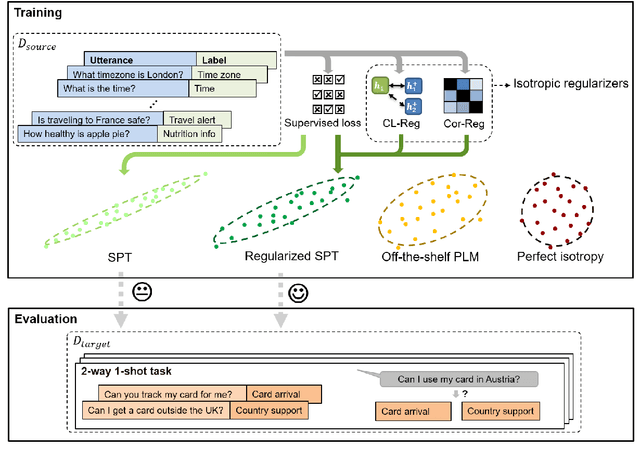
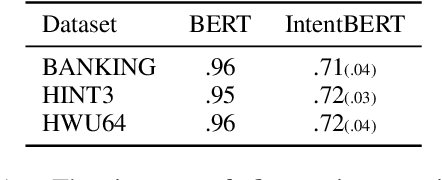
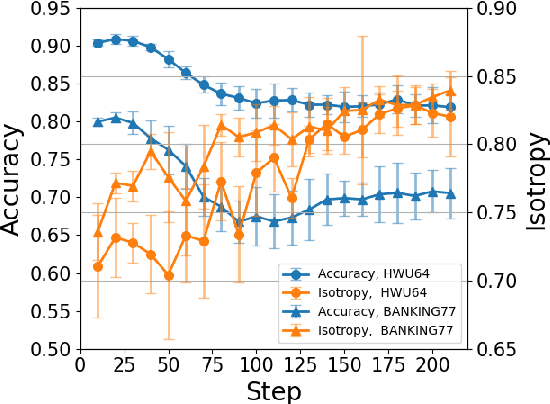

It is challenging to train a good intent classifier for a task-oriented dialogue system with only a few annotations. Recent studies have shown that fine-tuning pre-trained language models with a small amount of labeled utterances from public benchmarks in a supervised manner is extremely helpful. However, we find that supervised pre-training yields an anisotropic feature space, which may suppress the expressive power of the semantic representations. Inspired by recent research in isotropization, we propose to improve supervised pre-training by regularizing the feature space towards isotropy. We propose two regularizers based on contrastive learning and correlation matrix respectively, and demonstrate their effectiveness through extensive experiments. Our main finding is that it is promising to regularize supervised pre-training with isotropization to further improve the performance of few-shot intent detection. The source code can be found at https://github.com/fanolabs/isoIntentBert-main.