 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEL4NER: Ensemble Learning for Named Entity Recognition via Multiple Small-Parameter Large Language Models
May 29, 2025In-Context Learning (ICL) technique based on Large Language Models (LLMs) has gained prominence in Named Entity Recognition (NER) tasks for its lower computing resource consumption, less manual labeling overhead, and stronger generalizability. Nevertheless, most ICL-based NER methods depend on large-parameter LLMs: the open-source models demand substantial computational resources for deployment and inference, while the closed-source ones incur high API costs, raise data-privacy concerns, and hinder community collaboration. To address this question, we propose an Ensemble Learning Method for Named Entity Recognition (EL4NER), which aims at aggregating the ICL outputs of multiple open-source, small-parameter LLMs to enhance overall performance in NER tasks at less deployment and inference cost. Specifically, our method comprises three key components. First, we design a task decomposition-based pipeline that facilitates deep, multi-stage ensemble learning. Second, we introduce a novel span-level sentence similarity algorithm to establish an ICL demonstration retrieval mechanism better suited for NER tasks. Third, we incorporate a self-validation mechanism to mitigate the noise introduced during the ensemble process. We evaluated EL4NER on multiple widely adopted NER datasets from diverse domains. Our experimental results indicate that EL4NER surpasses most closed-source, large-parameter LLM-based methods at a lower parameter cost and even attains state-of-the-art (SOTA) performance among ICL-based methods on certain datasets. These results show the parameter efficiency of EL4NER and underscore the feasibility of employing open-source, small-parameter LLMs within the ICL paradigm for NER tasks.
GeoEdit: Geometric Knowledge Editing for Large Language Models
Feb 27, 2025Regular updates are essential for maintaining up-to-date knowledge in large language models (LLMs). Consequently, various model editing methods have been developed to update specific knowledge within LLMs. However, training-based approaches often struggle to effectively incorporate new knowledge while preserving unrelated general knowledge. To address this challenge, we propose a novel framework called Geometric Knowledge Editing (GeoEdit). GeoEdit utilizes the geometric relationships of parameter updates from fine-tuning to differentiate between neurons associated with new knowledge updates and those related to general knowledge perturbations. By employing a direction-aware knowledge identification method, we avoid updating neurons with directions approximately orthogonal to existing knowledge, thus preserving the model's generalization ability. For the remaining neurons, we integrate both old and new knowledge for aligned directions and apply a "forget-then-learn" editing strategy for opposite directions. Additionally, we introduce an importance-guided task vector fusion technique that filters out redundant information and provides adaptive neuron-level weighting, further enhancing model editing performance. Extensive experiments on two publicly available datasets demonstrate the superiority of GeoEdit over existing state-of-the-art methods.
Recurrent Knowledge Identification and Fusion for Language Model Continual Learning
Feb 22, 2025Continual learning (CL) is crucial for deploying large language models (LLMs) in dynamic real-world environments without costly retraining. While recent model ensemble and model merging methods guided by parameter importance have gained popularity, they often struggle to balance knowledge transfer and forgetting, mainly due to the reliance on static importance estimates during sequential training. In this paper, we present Recurrent-KIF, a novel CL framework for Recurrent Knowledge Identification and Fusion, which enables dynamic estimation of parameter importance distributions to enhance knowledge transfer. Inspired by human continual learning, Recurrent-KIF employs an inner loop that rapidly adapts to new tasks while identifying important parameters, coupled with an outer loop that globally manages the fusion of new and historical knowledge through redundant knowledge pruning and key knowledge merging. These inner-outer loops iteratively perform multiple rounds of fusion, allowing Recurrent-KIF to leverage intermediate training information and adaptively adjust fusion strategies based on evolving importance distributions. Extensive experiments on two CL benchmarks with various model sizes (from 770M to 13B) demonstrate that Recurrent-KIF effectively mitigates catastrophic forgetting and enhances knowledge transfer.
RAGraph: A General Retrieval-Augmented Graph Learning Framework
Oct 31, 2024



Graph Neural Networks (GNNs) have become essential in interpreting relational data across various domains, yet, they often struggle to generalize to unseen graph data that differs markedly from training instances. In this paper, we introduce a novel framework called General Retrieval-Augmented Graph Learning (RAGraph), which brings external graph data into the general graph foundation model to improve model generalization on unseen scenarios. On the top of our framework is a toy graph vector library that we established, which captures key attributes, such as features and task-specific label information. During inference, the RAGraph adeptly retrieves similar toy graphs based on key similarities in downstream tasks, integrating the retrieved data to enrich the learning context via the message-passing prompting mechanism. Our extensive experimental evaluations demonstrate that RAGraph significantly outperforms state-of-the-art graph learning methods in multiple tasks such as node classification, link prediction, and graph classification across both dynamic and static datasets. Furthermore, extensive testing confirms that RAGraph consistently maintains high performance without the need for task-specific fine-tuning, highlighting its adaptability, robustness, and broad applicability.
Parenting: Optimizing Knowledge Selection of Retrieval-Augmented Language Models with Parameter Decoupling and Tailored Tuning
Oct 14, 2024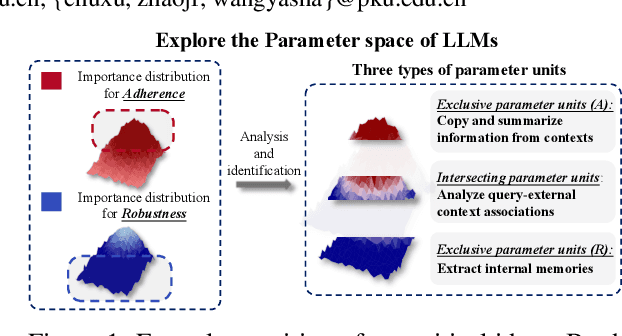
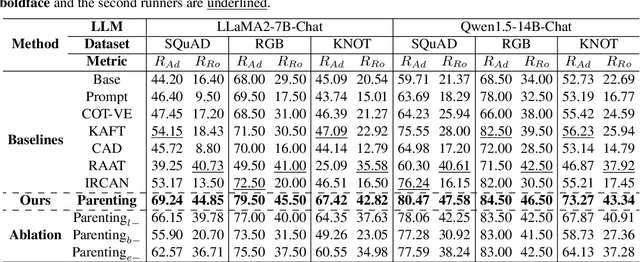
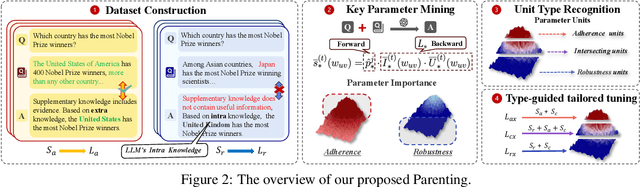
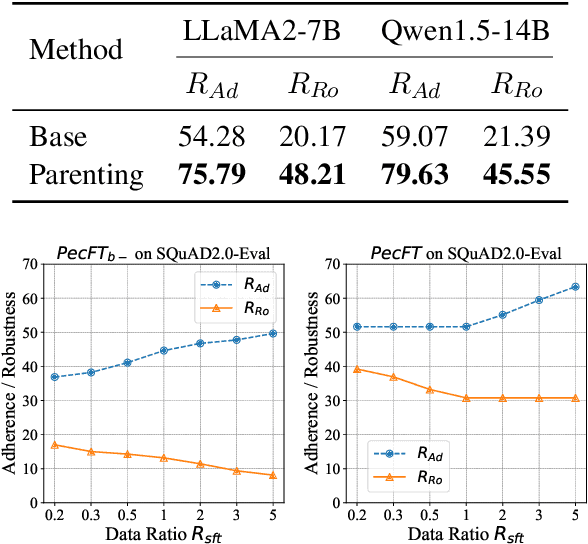
Retrieval-Augmented Generation (RAG) offers an effective solution to the issues faced by Large Language Models (LLMs) in hallucination generation and knowledge obsolescence by incorporating externally retrieved knowledge. However, due to potential conflicts between internal and external knowledge, as well as retrieval noise, LLMs often struggle to effectively integrate external evidence, leading to a decline in performance. Although existing methods attempt to tackle these challenges, they often struggle to strike a balance between model adherence and robustness, resulting in significant learning variance. Inspired by human cognitive processes, we propose Parenting, a novel framework that decouples adherence and robustness within the parameter space of LLMs. Specifically, Parenting utilizes a key parameter mining method based on forward activation gain to identify and isolate the crucial parameter units that are strongly linked to adherence and robustness. Then, Parenting employs a type-guided tailored tuning strategy, applying specific and appropriate fine-tuning methods to parameter units representing different capabilities, aiming to achieve a balanced enhancement of adherence and robustness. Extensive experiments on various datasets and models validate the effectiveness and generalizability of our methods.
3DS: Decomposed Difficulty Data Selection's Case Study on LLM Medical Domain Adaptation
Oct 13, 2024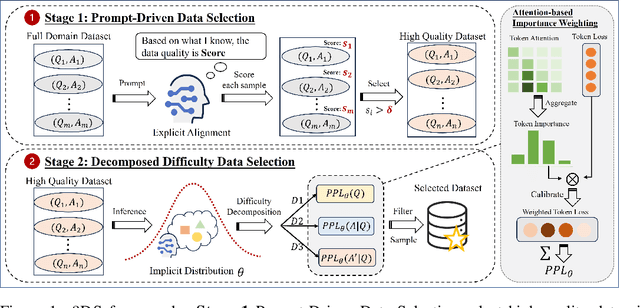
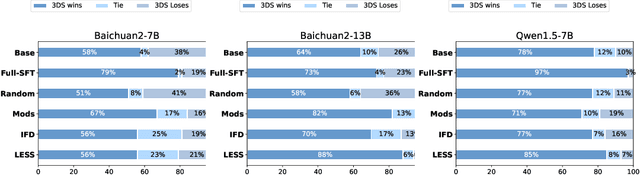
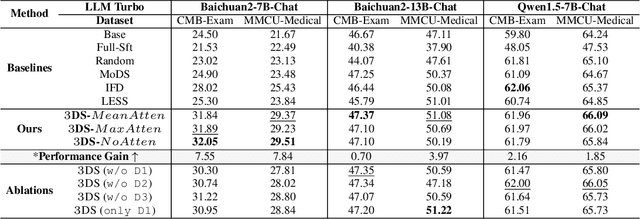
Large Language Models(LLMs) excel in general tasks but struggle in specialized domains like healthcare due to limited domain-specific knowledge.Supervised Fine-Tuning(SFT) data construction for domain adaptation often relies on heuristic methods, such as GPT-4 annotation or manual data selection, with a data-centric focus on presumed diverse, high-quality datasets. However, these methods overlook the model's inherent knowledge distribution, introducing noise, redundancy, and irrelevant data, leading to a mismatch between the selected data and the model's learning task, resulting in suboptimal performance. To address this, we propose a two-stage model-centric data selection framework, Decomposed Difficulty Data Selection (3DS), which aligns data with the model's knowledge distribution for optimized adaptation. In Stage1, we apply Prompt-Driven Data Selection via Explicit Alignment, where the the model filters irrelevant or redundant data based on its internal knowledge. In Stage2, we perform Decomposed Difficulty Data Selection, where data selection is guided by our defined difficulty decomposition, using three metrics: Instruction Understanding, Response Confidence, and Response Correctness. Additionally, an attention-based importance weighting mechanism captures token importance for more accurate difficulty calibration. This two-stage approach ensures the selected data is not only aligned with the model's knowledge and preferences but also appropriately challenging for the model to learn, leading to more effective and targeted domain adaptation. In the case study of the medical domain, our extensive experiments on real-world healthcare datasets demonstrate the superiority of 3DS over exisiting methods in accuracy by over 5.29%. Our dataset and code will be open-sourced at https://anonymous.4open.science/r/3DS-E67F.
IntelliCare: Improving Healthcare Analysis with Variance-Controlled Patient-Level Knowledge from Large Language Models
Aug 23, 2024While pioneering deep learning methods have made great strides in analyzing electronic health record (EHR) data, they often struggle to fully capture the semantics of diverse medical codes from limited data. The integration of external knowledge from Large Language Models (LLMs) presents a promising avenue for improving healthcare predictions. However, LLM analyses may exhibit significant variance due to ambiguity problems and inconsistency issues, hindering their effective utilization. To address these challenges, we propose IntelliCare, a novel framework that leverages LLMs to provide high-quality patient-level external knowledge and enhance existing EHR models. Concretely, IntelliCare identifies patient cohorts and employs task-relevant statistical information to augment LLM understanding and generation, effectively mitigating the ambiguity problem. Additionally, it refines LLM-derived knowledge through a hybrid approach, generating multiple analyses and calibrating them using both the EHR model and perplexity measures. Experimental evaluations on three clinical prediction tasks across two large-scale EHR datasets demonstrate that IntelliCare delivers significant performance improvements to existing methods, highlighting its potential in advancing personalized healthcare predictions and decision support systems.
KnowPO: Knowledge-aware Preference Optimization for Controllable Knowledge Selection in Retrieval-Augmented Language Models
Aug 19, 2024

By integrating external knowledge, Retrieval-Augmented Generation (RAG) has become an effective strategy for mitigating the hallucination problems that large language models (LLMs) encounter when dealing with knowledge-intensive tasks. However, in the process of integrating external non-parametric supporting evidence with internal parametric knowledge, inevitable knowledge conflicts may arise, leading to confusion in the model's responses. To enhance the knowledge selection of LLMs in various contexts, some research has focused on refining their behavior patterns through instruction-tuning. Nonetheless, due to the absence of explicit negative signals and comparative objectives, models fine-tuned in this manner may still exhibit undesirable behaviors such as contextual ignorance and contextual overinclusion. To this end, we propose a Knowledge-aware Preference Optimization strategy, dubbed KnowPO, aimed at achieving adaptive knowledge selection based on contextual relevance in real retrieval scenarios. Concretely, we proposed a general paradigm for constructing knowledge conflict datasets, which comprehensively cover various error types and learn how to avoid these negative signals through preference optimization methods. Simultaneously, we proposed a rewriting strategy and data ratio optimization strategy to address preference imbalances. Experimental results show that KnowPO outperforms previous methods for handling knowledge conflicts by over 37\%, while also exhibiting robust generalization across various out-of-distribution datasets.
TaSL: Continual Dialog State Tracking via Task Skill Localization and Consolidation
Aug 19, 2024A practical dialogue system requires the capacity for ongoing skill acquisition and adaptability to new tasks while preserving prior knowledge. However, current methods for Continual Dialogue State Tracking (DST), a crucial function of dialogue systems, struggle with the catastrophic forgetting issue and knowledge transfer between tasks. We present TaSL, a novel framework for task skill localization and consolidation that enables effective knowledge transfer without relying on memory replay. TaSL uses a novel group-wise technique to pinpoint task-specific and task-shared areas. Additionally, a fine-grained skill consolidation strategy protects task-specific knowledge from being forgotten while updating shared knowledge for bi-directional knowledge transfer. As a result, TaSL strikes a balance between preserving previous knowledge and excelling at new tasks. Comprehensive experiments on various backbones highlight the significant performance improvements of TaSL over existing state-of-the-art methods. The source code is provided for reproducibility.
TC-RAG:Turing-Complete RAG's Case study on Medical LLM Systems
Aug 17, 2024



In the pursuit of enhancing domain-specific Large Language Models (LLMs), Retrieval-Augmented Generation (RAG) emerges as a promising solution to mitigate issues such as hallucinations, outdated knowledge, and limited expertise in highly specialized queries. However, existing approaches to RAG fall short by neglecting system state variables, which are crucial for ensuring adaptive control, retrieval halting, and system convergence. In this paper, we introduce the TC-RAG through rigorous proof, a novel framework that addresses these challenges by incorporating a Turing Complete System to manage state variables, thereby enabling more efficient and accurate knowledge retrieval. By leveraging a memory stack system with adaptive retrieval, reasoning, and planning capabilities, TC-RAG not only ensures the controlled halting of retrieval processes but also mitigates the accumulation of erroneous knowledge via Push and Pop actions. In the case study of the medical domain, our extensive experiments on real-world healthcare datasets demonstrate the superiority of TC-RAG over existing methods in accuracy by over 7.20\%. Our dataset and code have been available at https://https://github.com/Artessay/SAMA.git.