 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDrive-KD: Multi-Teacher Distillation for VLMs in Autonomous Driving
Jan 29, 2026Autonomous driving is an important and safety-critical task, and recent advances in LLMs/VLMs have opened new possibilities for reasoning and planning in this domain. However, large models demand substantial GPU memory and exhibit high inference latency, while conventional supervised fine-tuning (SFT) often struggles to bridge the capability gaps of small models. To address these limitations, we propose Drive-KD, a framework that decomposes autonomous driving into a "perception-reasoning-planning" triad and transfers these capabilities via knowledge distillation. We identify layer-specific attention as the distillation signal to construct capability-specific single-teacher models that outperform baselines. Moreover, we unify these single-teacher settings into a multi-teacher distillation framework and introduce asymmetric gradient projection to mitigate cross-capability gradient conflicts. Extensive evaluations validate the generalization of our method across diverse model families and scales. Experiments show that our distilled InternVL3-1B model, with ~42 times less GPU memory and ~11.4 times higher throughput, achieves better overall performance than the pretrained 78B model from the same family on DriveBench, and surpasses GPT-5.1 on the planning dimension, providing insights toward efficient autonomous driving VLMs.
AutoDriDM: An Explainable Benchmark for Decision-Making of Vision-Language Models in Autonomous Driving
Jan 21, 2026Autonomous driving is a highly challenging domain that requires reliable perception and safe decision-making in complex scenarios. Recent vision-language models (VLMs) demonstrate reasoning and generalization abilities, opening new possibilities for autonomous driving; however, existing benchmarks and metrics overemphasize perceptual competence and fail to adequately assess decision-making processes. In this work, we present AutoDriDM, a decision-centric, progressive benchmark with 6,650 questions across three dimensions - Object, Scene, and Decision. We evaluate mainstream VLMs to delineate the perception-to-decision capability boundary in autonomous driving, and our correlation analysis reveals weak alignment between perception and decision-making performance. We further conduct explainability analyses of models' reasoning processes, identifying key failure modes such as logical reasoning errors, and introduce an analyzer model to automate large-scale annotation. AutoDriDM bridges the gap between perception-centered and decision-centered evaluation, providing guidance toward safer and more reliable VLMs for real-world autonomous driving.
Let Me Show You: Learning by Retrieving from Egocentric Video for Robotic Manipulation
Nov 07, 2025Robots operating in complex and uncertain environments face considerable challenges. Advanced robotic systems often rely on extensive datasets to learn manipulation tasks. In contrast, when humans are faced with unfamiliar tasks, such as assembling a chair, a common approach is to learn by watching video demonstrations. In this paper, we propose a novel method for learning robot policies by Retrieving-from-Video (RfV), using analogies from human demonstrations to address manipulation tasks. Our system constructs a video bank comprising recordings of humans performing diverse daily tasks. To enrich the knowledge from these videos, we extract mid-level information, such as object affordance masks and hand motion trajectories, which serve as additional inputs to enhance the robot model's learning and generalization capabilities. We further feature a dual-component system: a video retriever that taps into an external video bank to fetch task-relevant video based on task specification, and a policy generator that integrates this retrieved knowledge into the learning cycle. This approach enables robots to craft adaptive responses to various scenarios and generalize to tasks beyond those in the training data. Through rigorous testing in multiple simulated and real-world settings, our system demonstrates a marked improvement in performance over conventional robotic systems, showcasing a significant breakthrough in the field of robotics.
ActiveUMI: Robotic Manipulation with Active Perception from Robot-Free Human Demonstrations
Oct 02, 2025


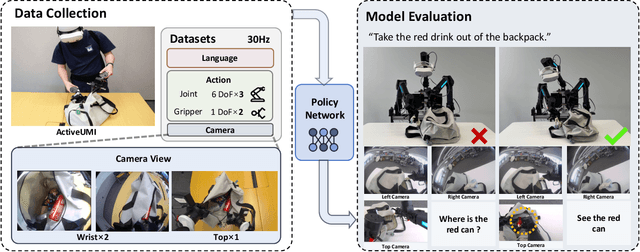
We present ActiveUMI, a framework for a data collection system that transfers in-the-wild human demonstrations to robots capable of complex bimanual manipulation. ActiveUMI couples a portable VR teleoperation kit with sensorized controllers that mirror the robot's end-effectors, bridging human-robot kinematics via precise pose alignment. To ensure mobility and data quality, we introduce several key techniques, including immersive 3D model rendering, a self-contained wearable computer, and efficient calibration methods. ActiveUMI's defining feature is its capture of active, egocentric perception. By recording an operator's deliberate head movements via a head-mounted display, our system learns the crucial link between visual attention and manipulation. We evaluate ActiveUMI on six challenging bimanual tasks. Policies trained exclusively on ActiveUMI data achieve an average success rate of 70\% on in-distribution tasks and demonstrate strong generalization, retaining a 56\% success rate when tested on novel objects and in new environments. Our results demonstrate that portable data collection systems, when coupled with learned active perception, provide an effective and scalable pathway toward creating generalizable and highly capable real-world robot policies.
"Pull or Not to Pull?'': Investigating Moral Biases in Leading Large Language Models Across Ethical Dilemmas
Aug 10, 2025As large language models (LLMs) increasingly mediate ethically sensitive decisions, understanding their moral reasoning processes becomes imperative. This study presents a comprehensive empirical evaluation of 14 leading LLMs, both reasoning enabled and general purpose, across 27 diverse trolley problem scenarios, framed by ten moral philosophies, including utilitarianism, deontology, and altruism. Using a factorial prompting protocol, we elicited 3,780 binary decisions and natural language justifications, enabling analysis along axes of decisional assertiveness, explanation answer consistency, public moral alignment, and sensitivity to ethically irrelevant cues. Our findings reveal significant variability across ethical frames and model types: reasoning enhanced models demonstrate greater decisiveness and structured justifications, yet do not always align better with human consensus. Notably, "sweet zones" emerge in altruistic, fairness, and virtue ethics framings, where models achieve a balance of high intervention rates, low explanation conflict, and minimal divergence from aggregated human judgments. However, models diverge under frames emphasizing kinship, legality, or self interest, often producing ethically controversial outcomes. These patterns suggest that moral prompting is not only a behavioral modifier but also a diagnostic tool for uncovering latent alignment philosophies across providers. We advocate for moral reasoning to become a primary axis in LLM alignment, calling for standardized benchmarks that evaluate not just what LLMs decide, but how and why.
Active Multimodal Distillation for Few-shot Action Recognition
Jun 16, 2025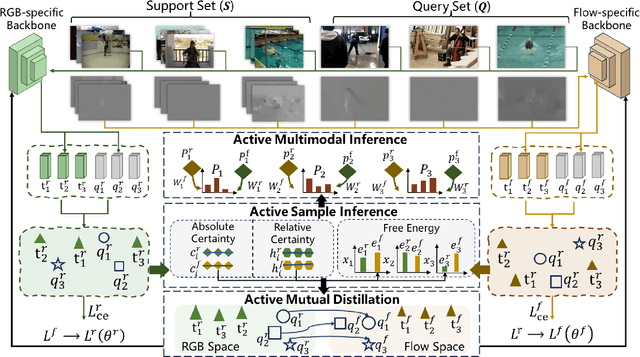
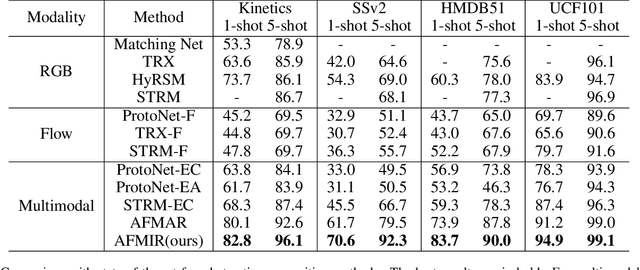
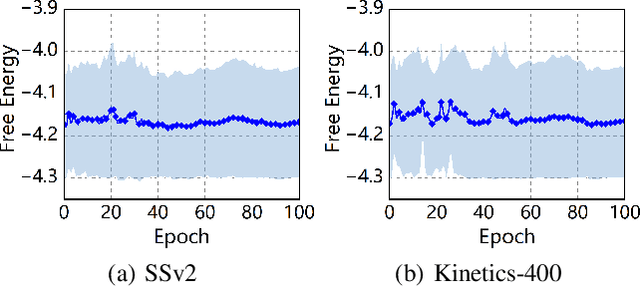
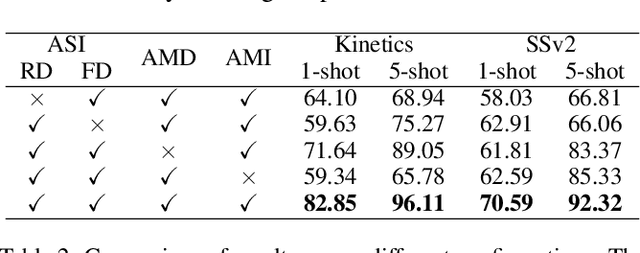
Owing to its rapid progress and broad application prospects, few-shot action recognition has attracted considerable interest. However, current methods are predominantly based on limited single-modal data, which does not fully exploit the potential of multimodal information. This paper presents a novel framework that actively identifies reliable modalities for each sample using task-specific contextual cues, thus significantly improving recognition performance. Our framework integrates an Active Sample Inference (ASI) module, which utilizes active inference to predict reliable modalities based on posterior distributions and subsequently organizes them accordingly. Unlike reinforcement learning, active inference replaces rewards with evidence-based preferences, making more stable predictions. Additionally, we introduce an active mutual distillation module that enhances the representation learning of less reliable modalities by transferring knowledge from more reliable ones. Adaptive multimodal inference is employed during the meta-test to assign higher weights to reliable modalities. Extensive experiments across multiple benchmarks demonstrate that our method significantly outperforms existing approaches.
ChatVLA-2: Vision-Language-Action Model with Open-World Embodied Reasoning from Pretrained Knowledge
May 29, 2025Vision-language-action (VLA) models have emerged as the next generation of models in robotics. However, despite leveraging powerful pre-trained Vision-Language Models (VLMs), existing end-to-end VLA systems often lose key capabilities during fine-tuning as the model adapts to specific robotic tasks. We argue that a generalizable VLA model should retain and expand upon the VLM's core competencies: 1) Open-world embodied reasoning - the VLA should inherit the knowledge from VLM, i.e., recognize anything that the VLM can recognize, be capable of solving math problems, and possess visual-spatial intelligence, 2) Reasoning following - effectively translating the open-world reasoning into actionable steps for the robot. In this work, we introduce ChatVLA-2, a novel mixture-of-expert VLA model coupled with a specialized two-stage training pipeline designed to preserve the VLM's original strengths while enabling actionable reasoning. To validate our approach, we design a math-matching task wherein a robot interprets math problems written on a whiteboard and picks corresponding number cards from a table to solve equations. Remarkably, our method exhibits exceptional mathematical reasoning and OCR capabilities, despite these abilities not being explicitly trained within the VLA. Furthermore, we demonstrate that the VLA possesses strong spatial reasoning skills, enabling it to interpret novel directional instructions involving previously unseen objects. Overall, our method showcases reasoning and comprehension abilities that significantly surpass state-of-the-art imitation learning methods such as OpenVLA, DexVLA, and pi-zero. This work represents a substantial advancement toward developing truly generalizable robotic foundation models endowed with robust reasoning capacities.
Vision-Language-Action Model with Open-World Embodied Reasoning from Pretrained Knowledge
May 28, 2025Vision-language-action (VLA) models have emerged as the next generation of models in robotics. However, despite leveraging powerful pre-trained Vision-Language Models (VLMs), existing end-to-end VLA systems often lose key capabilities during fine-tuning as the model adapts to specific robotic tasks. We argue that a generalizable VLA model should retain and expand upon the VLM's core competencies: 1) Open-world embodied reasoning - the VLA should inherit the knowledge from VLM, i.e., recognize anything that the VLM can recognize, capable of solving math problems, possessing visual-spatial intelligence, 2) Reasoning following - effectively translating the open-world reasoning into actionable steps for the robot. In this work, we introduce ChatVLA-2, a novel mixture-of-expert VLA model coupled with a specialized three-stage training pipeline designed to preserve the VLM's original strengths while enabling actionable reasoning. To validate our approach, we design a math-matching task wherein a robot interprets math problems written on a whiteboard and picks corresponding number cards from a table to solve equations. Remarkably, our method exhibits exceptional mathematical reasoning and OCR capabilities, despite these abilities not being explicitly trained within the VLA. Furthermore, we demonstrate that the VLA possesses strong spatial reasoning skills, enabling it to interpret novel directional instructions involving previously unseen objects. Overall, our method showcases reasoning and comprehension abilities that significantly surpass state-of-the-art imitation learning methods such as OpenVLA, DexVLA, and pi-zero. This work represents a substantial advancement toward developing truly generalizable robotic foundation models endowed with robust reasoning capacities.
WorldEval: World Model as Real-World Robot Policies Evaluator
May 25, 2025The field of robotics has made significant strides toward developing generalist robot manipulation policies. However, evaluating these policies in real-world scenarios remains time-consuming and challenging, particularly as the number of tasks scales and environmental conditions change. In this work, we demonstrate that world models can serve as a scalable, reproducible, and reliable proxy for real-world robot policy evaluation. A key challenge is generating accurate policy videos from world models that faithfully reflect the robot actions. We observe that directly inputting robot actions or using high-dimensional encoding methods often fails to generate action-following videos. To address this, we propose Policy2Vec, a simple yet effective approach to turn a video generation model into a world simulator that follows latent action to generate the robot video. We then introduce WorldEval, an automated pipeline designed to evaluate real-world robot policies entirely online. WorldEval effectively ranks various robot policies and individual checkpoints within a single policy, and functions as a safety detector to prevent dangerous actions by newly developed robot models. Through comprehensive paired evaluations of manipulation policies in real-world environments, we demonstrate a strong correlation between policy performance in WorldEval and real-world scenarios. Furthermore, our method significantly outperforms popular methods such as real-to-sim approach.
PointVLA: Injecting the 3D World into Vision-Language-Action Models
Mar 10, 2025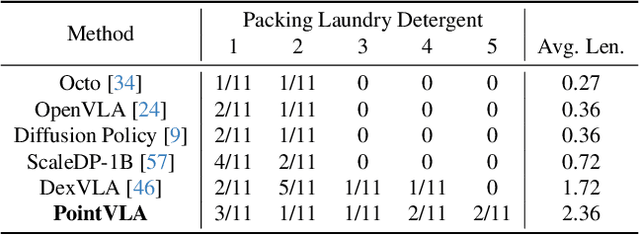
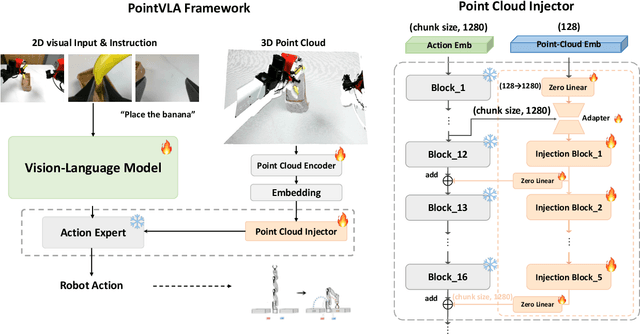
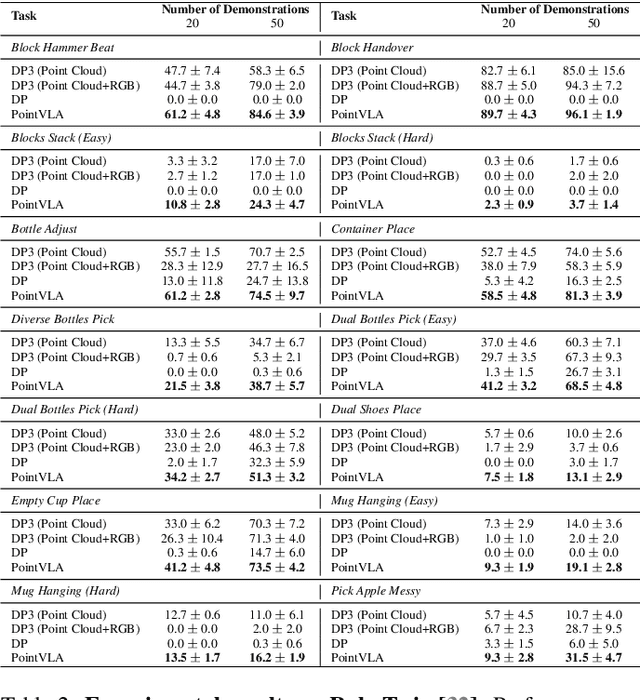
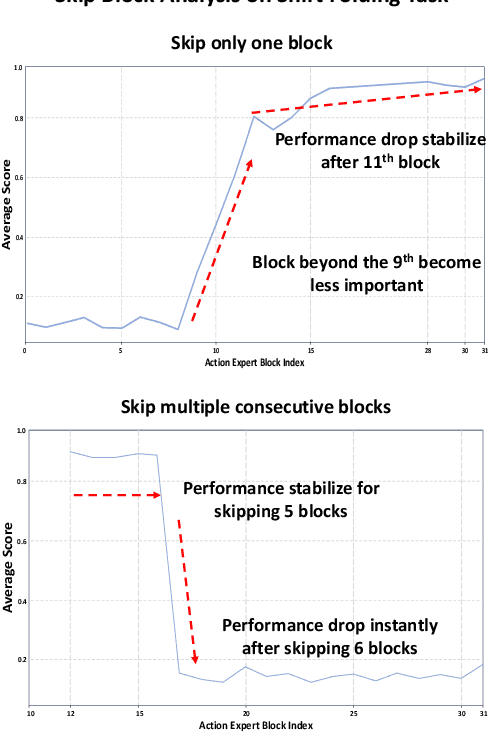
Vision-Language-Action (VLA) models excel at robotic tasks by leveraging large-scale 2D vision-language pretraining, but their reliance on RGB images limits spatial reasoning critical for real-world interaction. Retraining these models with 3D data is computationally prohibitive, while discarding existing 2D datasets wastes valuable resources. To bridge this gap, we propose PointVLA, a framework that enhances pre-trained VLAs with point cloud inputs without requiring retraining. Our method freezes the vanilla action expert and injects 3D features via a lightweight modular block. To identify the most effective way of integrating point cloud representations, we conduct a skip-block analysis to pinpoint less useful blocks in the vanilla action expert, ensuring that 3D features are injected only into these blocks--minimizing disruption to pre-trained representations. Extensive experiments demonstrate that PointVLA outperforms state-of-the-art 2D imitation learning methods, such as OpenVLA, Diffusion Policy and DexVLA, across both simulated and real-world robotic tasks. Specifically, we highlight several key advantages of PointVLA enabled by point cloud integration: (1) Few-shot multi-tasking, where PointVLA successfully performs four different tasks using only 20 demonstrations each; (2) Real-vs-photo discrimination, where PointVLA distinguishes real objects from their images, leveraging 3D world knowledge to improve safety and reliability; (3) Height adaptability, Unlike conventional 2D imitation learning methods, PointVLA enables robots to adapt to objects at varying table height that unseen in train data. Furthermore, PointVLA achieves strong performance in long-horizon tasks, such as picking and packing objects from a moving conveyor belt, showcasing its ability to generalize across complex, dynamic environments.