 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Instance Segmentation with Polygon Detection Transformers
Mar 10, 2026One of the bottlenecks for instance segmentation today lies in the conflicting requirements of high-resolution inputs and lightweight, real-time inference. To address this bottleneck, we present a Polygon Detection Transformer (Poly-DETR) to reformulate instance segmentation as sparse vertex regression via Polar Representation, thereby eliminating the reliance on dense pixel-wise mask prediction. Considering the box-to-polygon reference shift in Detection Transformers, we propose Polar Deformable Attention and Position-Aware Training Scheme to dynamically update supervision and focus attention on boundary cues. Compared with state-of-the-art polar-based methods, Poly-DETR achieves a 4.7 mAP improvement on MS COCO test-dev. Moreover, we construct a parallel mask-based counterpart to support a systematic comparison between polar and mask representations. Experimental results show that Poly-DETR is more lightweight in high-resolution scenarios, reducing memory consumption by almost half on Cityscapes dataset. Notably, on PanNuke (cell segmentation) and SpaceNet (building footprints) datasets, Poly-DETR surpasses its mask-based counterpart on all metrics, which validates its advantage on regular-shaped instances in domain-specific settings.
FVG-PT: Adaptive Foreground View-Guided Prompt Tuning for Vision-Language Models
Mar 09, 2026CLIP-based prompt tuning enables pretrained Vision-Language Models (VLMs) to efficiently adapt to downstream tasks. Although existing studies have made significant progress, they pay limited attention to changes in the internal attention representations of VLMs during the tuning process. In this paper, we attribute the failure modes of prompt tuning predictions to shifts in foreground attention of the visual encoder, and propose Foreground View-Guided Prompt Tuning (FVG-PT), an adaptive plug-and-play foreground attention guidance module, to alleviate the shifts. Concretely, FVG-PT introduces a learnable Foreground Reliability Gate to automatically enhance the foreground view quality, applies a Foreground Distillation Compensation module to guide visual attention toward the foreground, and further introduces a Prior Calibration module to mitigate generalization degradation caused by excessive focus on the foreground. Experiments on multiple backbone models and datasets show the effectiveness and compatibility of FVG-PT. Codes are available at: https://github.com/JREion/FVG-PT
DPC: Dual-Prompt Collaboration for Tuning Vision-Language Models
Mar 17, 2025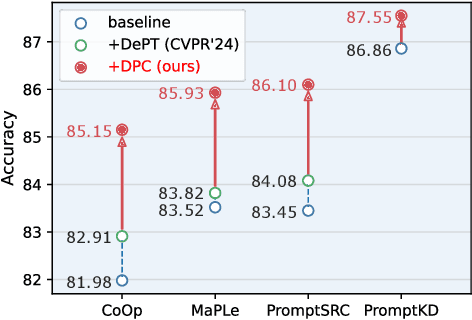
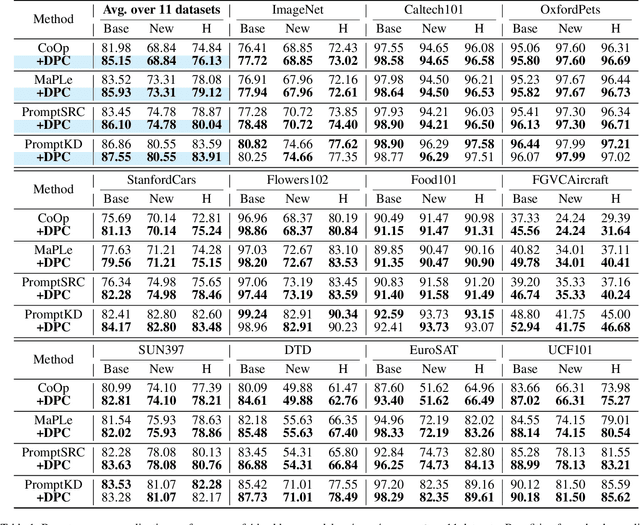
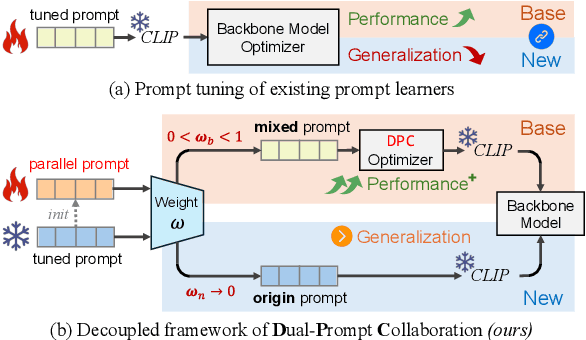

The Base-New Trade-off (BNT) problem universally exists during the optimization of CLIP-based prompt tuning, where continuous fine-tuning on base (target) classes leads to a simultaneous decrease of generalization ability on new (unseen) classes. Existing approaches attempt to regulate the prompt tuning process to balance BNT by appending constraints. However, imposed on the same target prompt, these constraints fail to fully avert the mutual exclusivity between the optimization directions for base and new. As a novel solution to this challenge, we propose the plug-and-play Dual-Prompt Collaboration (DPC) framework, the first that decoupling the optimization processes of base and new tasks at the prompt level. Specifically, we clone a learnable parallel prompt based on the backbone prompt, and introduce a variable Weighting-Decoupling framework to independently control the optimization directions of dual prompts specific to base or new tasks, thus avoiding the conflict in generalization. Meanwhile, we propose a Dynamic Hard Negative Optimizer, utilizing dual prompts to construct a more challenging optimization task on base classes for enhancement. For interpretability, we prove the feature channel invariance of the prompt vector during the optimization process, providing theoretical support for the Weighting-Decoupling of DPC. Extensive experiments on multiple backbones demonstrate that DPC can significantly improve base performance without introducing any external knowledge beyond the base classes, while maintaining generalization to new classes. Code is available at: https://github.com/JREion/DPC.
PointVLA: Injecting the 3D World into Vision-Language-Action Models
Mar 10, 2025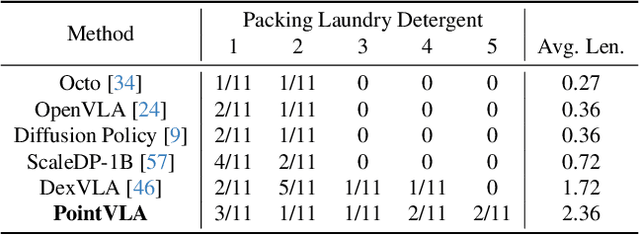
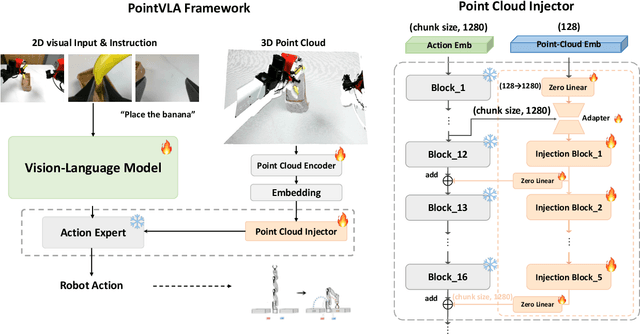
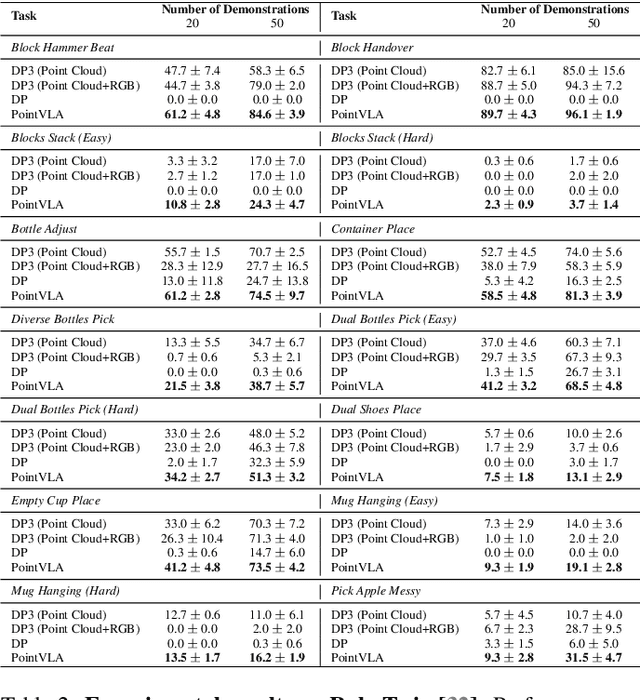
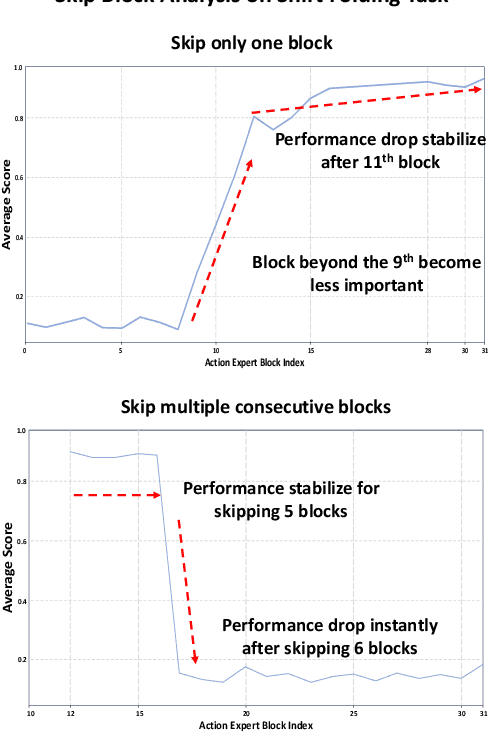
Vision-Language-Action (VLA) models excel at robotic tasks by leveraging large-scale 2D vision-language pretraining, but their reliance on RGB images limits spatial reasoning critical for real-world interaction. Retraining these models with 3D data is computationally prohibitive, while discarding existing 2D datasets wastes valuable resources. To bridge this gap, we propose PointVLA, a framework that enhances pre-trained VLAs with point cloud inputs without requiring retraining. Our method freezes the vanilla action expert and injects 3D features via a lightweight modular block. To identify the most effective way of integrating point cloud representations, we conduct a skip-block analysis to pinpoint less useful blocks in the vanilla action expert, ensuring that 3D features are injected only into these blocks--minimizing disruption to pre-trained representations. Extensive experiments demonstrate that PointVLA outperforms state-of-the-art 2D imitation learning methods, such as OpenVLA, Diffusion Policy and DexVLA, across both simulated and real-world robotic tasks. Specifically, we highlight several key advantages of PointVLA enabled by point cloud integration: (1) Few-shot multi-tasking, where PointVLA successfully performs four different tasks using only 20 demonstrations each; (2) Real-vs-photo discrimination, where PointVLA distinguishes real objects from their images, leveraging 3D world knowledge to improve safety and reliability; (3) Height adaptability, Unlike conventional 2D imitation learning methods, PointVLA enables robots to adapt to objects at varying table height that unseen in train data. Furthermore, PointVLA achieves strong performance in long-horizon tasks, such as picking and packing objects from a moving conveyor belt, showcasing its ability to generalize across complex, dynamic environments.
Unity RL Playground: A Versatile Reinforcement Learning Framework for Mobile Robots
Mar 07, 2025



This paper introduces Unity RL Playground, an open-source reinforcement learning framework built on top of Unity ML-Agents. Unity RL Playground automates the process of training mobile robots to perform various locomotion tasks such as walking, running, and jumping in simulation, with the potential for seamless transfer to real hardware. Key features include one-click training for imported robot models, universal compatibility with diverse robot configurations, multi-mode motion learning capabilities, and extreme performance testing to aid in robot design optimization and morphological evolution. The attached video can be found at https://linqi-ye.github.io/video/iros25.mp4 and the code is coming soon.
VIKSER: Visual Knowledge-Driven Self-Reinforcing Reasoning Framework
Feb 02, 2025



Visual reasoning refers to the task of solving questions about visual information. Current visual reasoning methods typically employ pre-trained vision-language model (VLM) strategies or deep neural network approaches. However, existing efforts are constrained by limited reasoning interpretability, while hindering by the phenomenon of underspecification in the question text. Additionally, the absence of fine-grained visual knowledge limits the precise understanding of subject behavior in visual reasoning tasks. To address these issues, we propose VIKSER (Visual Knowledge-Driven Self-Reinforcing Reasoning Framework). Specifically, VIKSER, trained using knowledge distilled from large language models, extracts fine-grained visual knowledge with the assistance of visual relationship detection techniques. Subsequently, VIKSER utilizes fine-grained visual knowledge to paraphrase the question with underspecification. Additionally, we design a novel prompting method called Chain-of-Evidence (CoE), which leverages the power of ``evidence for reasoning'' to endow VIKSER with interpretable reasoning capabilities. Meanwhile, the integration of self-reflection technology empowers VIKSER with the ability to learn and improve from its mistakes. Experiments conducted on widely used datasets demonstrate that VIKSER achieves new state-of-the-art (SOTA) results in relevant tasks.
PhiP-G: Physics-Guided Text-to-3D Compositional Scene Generation
Feb 02, 2025



Text-to-3D asset generation has achieved significant optimization under the supervision of 2D diffusion priors. However, when dealing with compositional scenes, existing methods encounter several challenges: 1). failure to ensure that composite scene layouts comply with physical laws; 2). difficulty in accurately capturing the assets and relationships described in complex scene descriptions; 3). limited autonomous asset generation capabilities among layout approaches leveraging large language models (LLMs). To avoid these compromises, we propose a novel framework for compositional scene generation, PhiP-G, which seamlessly integrates generation techniques with layout guidance based on a world model. Leveraging LLM-based agents, PhiP-G analyzes the complex scene description to generate a scene graph, and integrating a multimodal 2D generation agent and a 3D Gaussian generation method for targeted assets creation. For the stage of layout, PhiP-G employs a physical pool with adhesion capabilities and a visual supervision agent, forming a world model for layout prediction and planning. Extensive experiments demonstrate that PhiP-G significantly enhances the generation quality and physical rationality of the compositional scenes. Notably, PhiP-G attains state-of-the-art (SOTA) performance in CLIP scores, achieves parity with the leading methods in generation quality as measured by the T$^3$Bench, and improves efficiency by 24x.
Hybrid Physics-ML Modeling for Marine Vehicle Maneuvering Motions in the Presence of Environmental Disturbances
Nov 21, 2024



A hybrid physics-machine learning modeling framework is proposed for the surface vehicles' maneuvering motions to address the modeling capability and stability in the presence of environmental disturbances. From a deep learning perspective, the framework is based on a variant version of residual networks with additional feature extraction. Initially, an imperfect physical model is derived and identified to capture the fundamental hydrodynamic characteristics of marine vehicles. This model is then integrated with a feedforward network through a residual block. Additionally, feature extraction from trigonometric transformations is employed in the machine learning component to account for the periodic influence of currents and waves. The proposed method is evaluated using real navigational data from the 'JH7500' unmanned surface vehicle. The results demonstrate the robust generalizability and accurate long-term prediction capabilities of the nonlinear dynamic model in specific environmental conditions. This approach has the potential to be extended and applied to develop a comprehensive high-fidelity simulator.
Reducing Hallucinations: Enhancing VQA for Flood Disaster Damage Assessment with Visual Contexts
Dec 21, 2023The zero-shot performance of visual question answering (VQA) models relies heavily on prompts. For example, a zero-shot VQA for disaster scenarios could leverage well-designed Chain of Thought (CoT) prompts to stimulate the model's potential. However, using CoT prompts has some problems, such as causing an incorrect answer in the end due to the hallucination in the thought process. In this paper, we propose a zero-shot VQA named Flood Disaster VQA with Two-Stage Prompt (VQA-TSP). The model generates the thought process in the first stage and then uses the thought process to generate the final answer in the second stage. In particular, visual context is added in the second stage to relieve the hallucination problem that exists in the thought process. Experimental results show that our method exceeds the performance of state-of-the-art zero-shot VQA models for flood disaster scenarios in total. Our study provides a research basis for improving the performance of CoT-based zero-shot VQA.
Unleashing the Potential of Large Language Model: Zero-shot VQA for Flood Disaster Scenario
Dec 04, 2023Visual question answering (VQA) is a fundamental and essential AI task, and VQA-based disaster scenario understanding is a hot research topic. For instance, we can ask questions about a disaster image by the VQA model and the answer can help identify whether anyone or anything is affected by the disaster. However, previous VQA models for disaster damage assessment have some shortcomings, such as limited candidate answer space, monotonous question types, and limited answering capability of existing models. In this paper, we propose a zero-shot VQA model named Zero-shot VQA for Flood Disaster Damage Assessment (ZFDDA). It is a VQA model for damage assessment without pre-training. Also, with flood disaster as the main research object, we build a Freestyle Flood Disaster Image Question Answering dataset (FFD-IQA) to evaluate our VQA model. This new dataset expands the question types to include free-form, multiple-choice, and yes-no questions. At the same time, we expand the size of the previous dataset to contain a total of 2,058 images and 22,422 question-meta ground truth pairs. Most importantly, our model uses well-designed chain of thought (CoT) demonstrations to unlock the potential of the large language model, allowing zero-shot VQA to show better performance in disaster scenarios. The experimental results show that the accuracy in answering complex questions is greatly improved with CoT prompts. Our study provides a research basis for subsequent research of VQA for other disaster scenarios.