 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLMS-Net: A Learned Mumford-Shah Network For Few-Shot Medical Image Segmentation
Feb 08, 2025



Few-shot semantic segmentation (FSS) methods have shown great promise in handling data-scarce scenarios, particularly in medical image segmentation tasks. However, most existing FSS architectures lack sufficient interpretability and fail to fully incorporate the underlying physical structures of semantic regions. To address these issues, in this paper, we propose a novel deep unfolding network, called the Learned Mumford-Shah Network (LMS-Net), for the FSS task. Specifically, motivated by the effectiveness of pixel-to-prototype comparison in prototypical FSS methods and the capability of deep priors to model complex spatial structures, we leverage our learned Mumford-Shah model (LMS model) as a mathematical foundation to integrate these insights into a unified framework. By reformulating the LMS model into prototype update and mask update tasks, we propose an alternating optimization algorithm to solve it efficiently. Further, the iterative steps of this algorithm are unfolded into corresponding network modules, resulting in LMS-Net with clear interpretability. Comprehensive experiments on three publicly available medical segmentation datasets verify the effectiveness of our method, demonstrating superior accuracy and robustness in handling complex structures and adapting to challenging segmentation scenarios. These results highlight the potential of LMS-Net to advance FSS in medical imaging applications. Our code will be available at: https://github.com/SDZhang01/LMSNet
Open set label noise learning with robust sample selection and margin-guided module
Jan 08, 2025
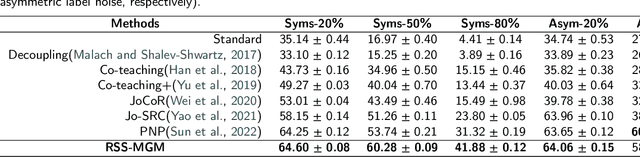
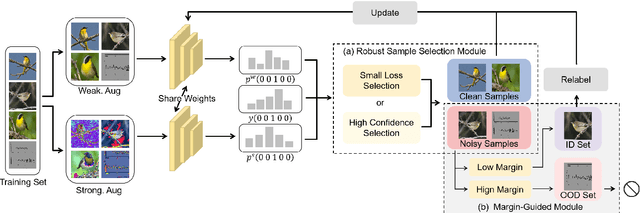
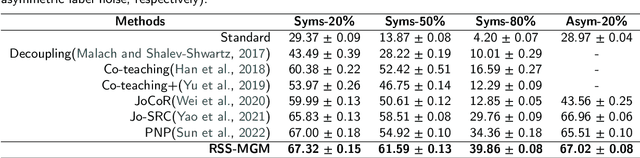
In recent years, the remarkable success of deep neural networks (DNNs) in computer vision is largely due to large-scale, high-quality labeled datasets. Training directly on real-world datasets with label noise may result in overfitting. The traditional method is limited to deal with closed set label noise, where noisy training data has true class labels within the known label space. However, there are some real-world datasets containing open set label noise, which means that some samples belong to an unknown class outside the known label space. To address the open set label noise problem, we introduce a method based on Robust Sample Selection and Margin-Guided Module (RSS-MGM). Firstly, unlike the prior clean sample selection approach, which only select a limited number of clean samples, a robust sample selection module combines small loss selection or high-confidence sample selection to obtain more clean samples. Secondly, to efficiently distinguish open set label noise and closed set ones, margin functions are designed to filter open-set data and closed set data. Thirdly, different processing methods are selected for different types of samples in order to fully utilize the data's prior information and optimize the whole model. Furthermore, extensive experimental results with noisy labeled data from benchmark datasets and real-world datasets, such as CIFAR-100N-C, CIFAR80N-O, WebFG-469, and Food101N, indicate that our approach outperforms many state-of-the-art label noise learning methods. Especially, it can more accurately divide open set label noise samples and closed set ones.
Memory-based Cross-modal Semantic Alignment Network for Radiology Report Generation
Mar 31, 2024



Generating radiology reports automatically reduces the workload of radiologists and helps the diagnoses of specific diseases. Many existing methods take this task as modality transfer process. However, since the key information related to disease accounts for a small proportion in both image and report, it is hard for the model to learn the latent relation between the radiology image and its report, thus failing to generate fluent and accurate radiology reports. To tackle this problem, we propose a memory-based cross-modal semantic alignment model (MCSAM) following an encoder-decoder paradigm. MCSAM includes a well initialized long-term clinical memory bank to learn disease-related representations as well as prior knowledge for different modalities to retrieve and use the retrieved memory to perform feature consolidation. To ensure the semantic consistency of the retrieved cross modal prior knowledge, a cross-modal semantic alignment module (SAM) is proposed. SAM is also able to generate semantic visual feature embeddings which can be added to the decoder and benefits report generation. More importantly, to memorize the state and additional information while generating reports with the decoder, we use learnable memory tokens which can be seen as prompts. Extensive experiments demonstrate the promising performance of our proposed method which generates state-of-the-art performance on the MIMIC-CXR dataset.
BSDP: Brain-inspired Streaming Dual-level Perturbations for Online Open World Object Detection
Mar 05, 2024



Humans can easily distinguish the known and unknown categories and can recognize the unknown object by learning it once instead of repeating it many times without forgetting the learned object. Hence, we aim to make deep learning models simulate the way people learn. We refer to such a learning manner as OnLine Open World Object Detection(OLOWOD). Existing OWOD approaches pay more attention to the identification of unknown categories, while the incremental learning part is also very important. Besides, some neuroscience research shows that specific noises allow the brain to form new connections and neural pathways which may improve learning speed and efficiency. In this paper, we take the dual-level information of old samples as perturbations on new samples to make the model good at learning new knowledge without forgetting the old knowledge. Therefore, we propose a simple plug-and-play method, called Brain-inspired Streaming Dual-level Perturbations(BSDP), to solve the OLOWOD problem. Specifically, (1) we first calculate the prototypes of previous categories and use the distance between samples and the prototypes as the sample selecting strategy to choose old samples for replay; (2) then take the prototypes as the streaming feature-level perturbations of new samples, so as to improve the plasticity of the model through revisiting the old knowledge; (3) and also use the distribution of the features of the old category samples to generate adversarial data in the form of streams as the data-level perturbations to enhance the robustness of the model to new categories. We empirically evaluate BSDP on PASCAL VOC and MS-COCO, and the excellent results demonstrate the promising performance of our proposed method and learning manner.
SwG-former: Sliding-window Graph Convolutional Network Integrated with Conformer for Sound Event Localization and Detection
Oct 21, 2023Sound event localization and detection (SELD) is a joint task of sound event detection (SED) and direction of arrival (DoA) estimation. SED mainly relies on temporal dependencies to distinguish different sound classes, while DoA estimation depends on spatial correlations to estimate source directions. To jointly optimize two subtasks, the SELD system should extract spatial correlations and model temporal dependencies simultaneously. However, numerous models mainly extract spatial correlations and model temporal dependencies separately. In this paper, the interdependence of spatial-temporal information in audio signals is exploited for simultaneous extraction to enhance the model performance. In response, a novel graph representation leveraging graph convolutional network (GCN) in non-Euclidean space is developed to extract spatial-temporal information concurrently. A sliding-window graph (SwG) module is designed based on the graph representation. It exploits sliding-windows with different sizes to learn temporal context information and dynamically constructs graph vertices in the frequency-channel (F-C) domain to capture spatial correlations. Furthermore, as the cornerstone of message passing, a robust Conv2dAgg function is proposed and embedded into the SwG module to aggregate the features of neighbor vertices. To improve the performance of SELD in a natural spatial acoustic environment, a general and efficient SwG-former model is proposed by integrating the SwG module with the Conformer. It exhibits superior performance in comparison to recent advanced SELD models. To further validate the generality and efficiency of the SwG-former, it is seamlessly integrated into the event-independent network version 2 (EINV2) called SwG-EINV2. The SwG-EINV2 surpasses the state-of-the-art (SOTA) methods under the same acoustic environment.
TriGait: Aligning and Fusing Skeleton and Silhouette Gait Data via a Tri-Branch Network
Aug 25, 2023



Gait recognition is a promising biometric technology for identification due to its non-invasiveness and long-distance. However, external variations such as clothing changes and viewpoint differences pose significant challenges to gait recognition. Silhouette-based methods preserve body shape but neglect internal structure information, while skeleton-based methods preserve structure information but omit appearance. To fully exploit the complementary nature of the two modalities, a novel triple branch gait recognition framework, TriGait, is proposed in this paper. It effectively integrates features from the skeleton and silhouette data in a hybrid fusion manner, including a two-stream network to extract static and motion features from appearance, a simple yet effective module named JSA-TC to capture dependencies between all joints, and a third branch for cross-modal learning by aligning and fusing low-level features of two modalities. Experimental results demonstrate the superiority and effectiveness of TriGait for gait recognition. The proposed method achieves a mean rank-1 accuracy of 96.0% over all conditions on CASIA-B dataset and 94.3% accuracy for CL, significantly outperforming all the state-of-the-art methods. The source code will be available at https://github.com/feng-xueling/TriGait/.
Open-World Object Detection via Discriminative Class Prototype Learning
Feb 23, 2023



Open-world object detection (OWOD) is a challenging problem that combines object detection with incremental learning and open-set learning. Compared to standard object detection, the OWOD setting is task to: 1) detect objects seen during training while identifying unseen classes, and 2) incrementally learn the knowledge of the identified unknown objects when the corresponding annotations is available. We propose a novel and efficient OWOD solution from a prototype perspective, which we call OCPL: Open-world object detection via discriminative Class Prototype Learning, which consists of a Proposal Embedding Aggregator (PEA), an Embedding Space Compressor (ESC) and a Cosine Similarity-based Classifier (CSC). All our proposed modules aim to learn the discriminative embeddings of known classes in the feature space to minimize the overlapping distributions of known and unknown classes, which is beneficial to differentiate known and unknown classes. Extensive experiments performed on PASCAL VOC and MS-COCO benchmark demonstrate the effectiveness of our proposed method.
* 4 pages, 3 figures, ICIP2022
Learning Discriminative Representations for Fine-Grained Diabetic Retinopathy Grading
Nov 04, 2020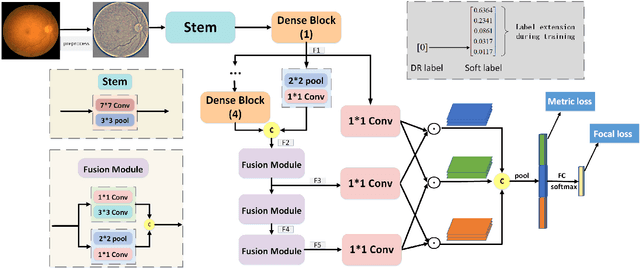
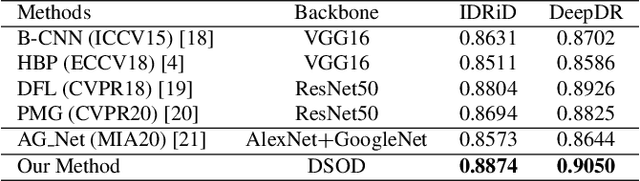
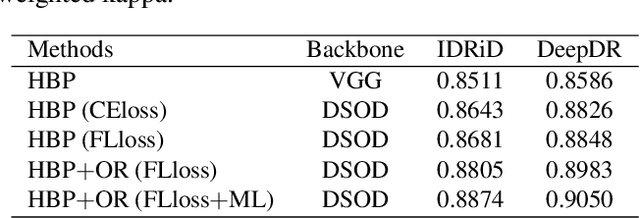
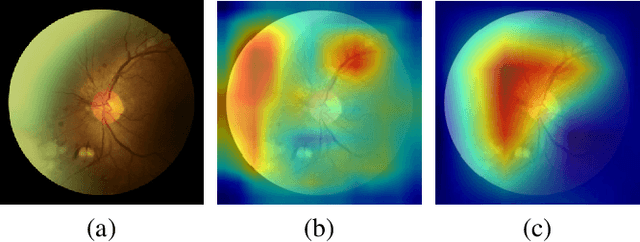
Diabetic retinopathy (DR) is one of the leading causes of blindness. However, no specific symptoms of early DR lead to a delayed diagnosis, which results in disease progression in patients. To determine the disease severity levels, ophthalmologists need to focus on the discriminative parts of the fundus images. In recent years, deep learning has achieved great success in medical image analysis. However, most works directly employ algorithms based on convolutional neural networks (CNNs), which ignore the fact that the difference among classes is subtle and gradual. Hence, we consider automatic image grading of DR as a fine-grained classification task, and construct a bilinear model to identify the pathologically discriminative areas. In order to leverage the ordinal information among classes, we use an ordinal regression method to obtain the soft labels. In addition, other than only using a categorical loss to train our network, we also introduce the metric loss to learn a more discriminative feature space. Experimental results demonstrate the superior performance of the proposed method on two public IDRiD and DeepDR datasets.
Multi-vision Attention Networks for On-line Red Jujube Grading
Mar 31, 2019
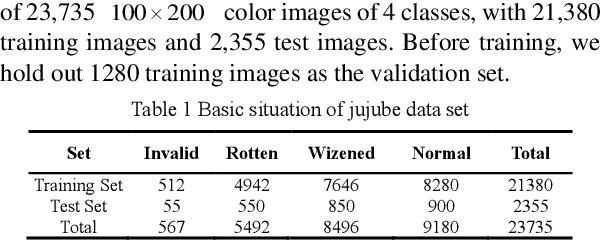
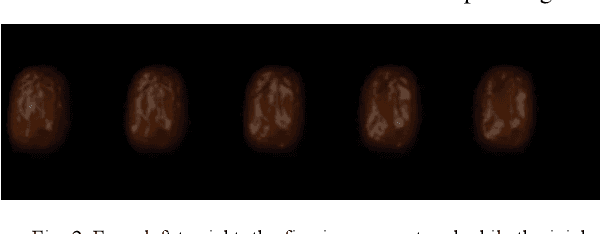
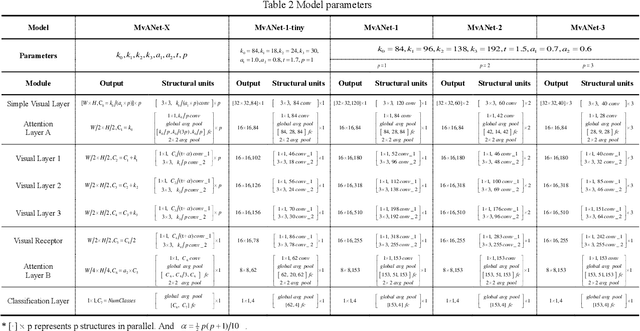
To solve the red jujube classification problem, this paper designs a convolutional neural network model with low computational cost and high classification accuracy. The architecture of the model is inspired by the multi-visual mechanism of the organism and DenseNet. To further improve our model, we add the attention mechanism of SE-Net. We also construct a dataset which contains 23,735 red jujube images captured by a jujube grading system. According to the appearance of the jujube and the characteristics of the grading system, the dataset is divided into four classes: invalid, rotten, wizened and normal. The numerical experiments show that the classification accuracy of our model reaches to 91.89%, which is comparable to DenseNet-121, InceptionV3, InceptionV4, and Inception-ResNet v2. However, our model has real-time performance.