 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSplit4D: Decomposed 4D Scene Reconstruction Without Video Segmentation
Dec 28, 2025This paper addresses the problem of decomposed 4D scene reconstruction from multi-view videos. Recent methods achieve this by lifting video segmentation results to a 4D representation through differentiable rendering techniques. Therefore, they heavily rely on the quality of video segmentation maps, which are often unstable, leading to unreliable reconstruction results. To overcome this challenge, our key idea is to represent the decomposed 4D scene with the Freetime FeatureGS and design a streaming feature learning strategy to accurately recover it from per-image segmentation maps, eliminating the need for video segmentation. Freetime FeatureGS models the dynamic scene as a set of Gaussian primitives with learnable features and linear motion ability, allowing them to move to neighboring regions over time. We apply a contrastive loss to Freetime FeatureGS, forcing primitive features to be close or far apart based on whether their projections belong to the same instance in the 2D segmentation map. As our Gaussian primitives can move across time, it naturally extends the feature learning to the temporal dimension, achieving 4D segmentation. Furthermore, we sample observations for training in a temporally ordered manner, enabling the streaming propagation of features over time and effectively avoiding local minima during the optimization process. Experimental results on several datasets show that the reconstruction quality of our method outperforms recent methods by a large margin.
StreamingTalker: Audio-driven 3D Facial Animation with Autoregressive Diffusion Model
Nov 19, 2025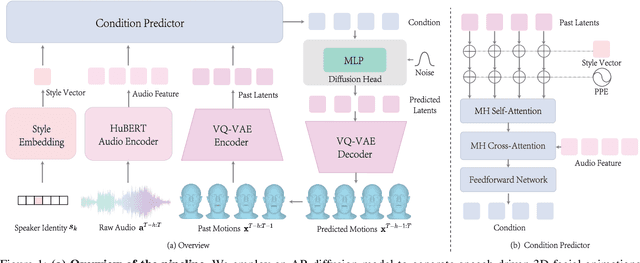
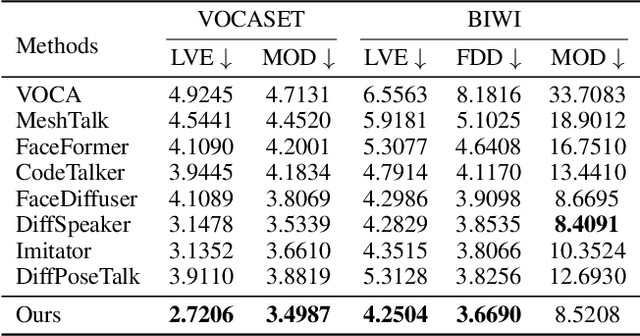
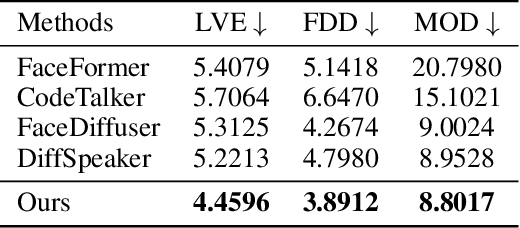
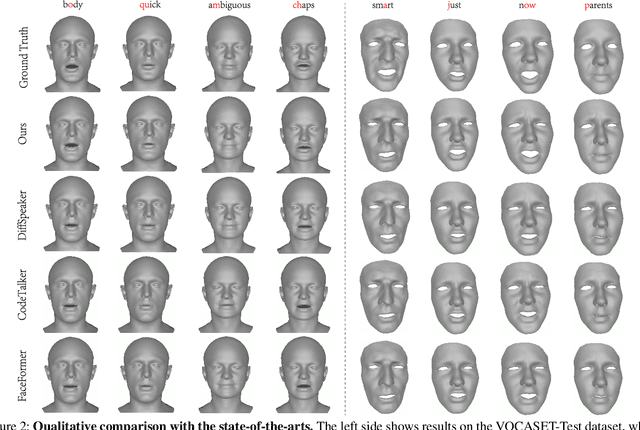
This paper focuses on the task of speech-driven 3D facial animation, which aims to generate realistic and synchronized facial motions driven by speech inputs. Recent methods have employed audio-conditioned diffusion models for 3D facial animation, achieving impressive results in generating expressive and natural animations. However, these methods process the whole audio sequences in a single pass, which poses two major challenges: they tend to perform poorly when handling audio sequences that exceed the training horizon and will suffer from significant latency when processing long audio inputs. To address these limitations, we propose a novel autoregressive diffusion model that processes input audio in a streaming manner. This design ensures flexibility with varying audio lengths and achieves low latency independent of audio duration. Specifically, we select a limited number of past frames as historical motion context and combine them with the audio input to create a dynamic condition. This condition guides the diffusion process to iteratively generate facial motion frames, enabling real-time synthesis with high-quality results. Additionally, we implemented a real-time interactive demo, highlighting the effectiveness and efficiency of our approach. We will release the code at https://zju3dv.github.io/StreamingTalker/.
RAGNet: Large-scale Reasoning-based Affordance Segmentation Benchmark towards General Grasping
Jul 31, 2025



General robotic grasping systems require accurate object affordance perception in diverse open-world scenarios following human instructions. However, current studies suffer from the problem of lacking reasoning-based large-scale affordance prediction data, leading to considerable concern about open-world effectiveness. To address this limitation, we build a large-scale grasping-oriented affordance segmentation benchmark with human-like instructions, named RAGNet. It contains 273k images, 180 categories, and 26k reasoning instructions. The images cover diverse embodied data domains, such as wild, robot, ego-centric, and even simulation data. They are carefully annotated with an affordance map, while the difficulty of language instructions is largely increased by removing their category name and only providing functional descriptions. Furthermore, we propose a comprehensive affordance-based grasping framework, named AffordanceNet, which consists of a VLM pre-trained on our massive affordance data and a grasping network that conditions an affordance map to grasp the target. Extensive experiments on affordance segmentation benchmarks and real-robot manipulation tasks show that our model has a powerful open-world generalization ability. Our data and code is available at https://github.com/wudongming97/AffordanceNet.
PADriver: Towards Personalized Autonomous Driving
May 08, 2025In this paper, we propose PADriver, a novel closed-loop framework for personalized autonomous driving (PAD). Built upon Multi-modal Large Language Model (MLLM), PADriver takes streaming frames and personalized textual prompts as inputs. It autoaggressively performs scene understanding, danger level estimation and action decision. The predicted danger level reflects the risk of the potential action and provides an explicit reference for the final action, which corresponds to the preset personalized prompt. Moreover, we construct a closed-loop benchmark named PAD-Highway based on Highway-Env simulator to comprehensively evaluate the decision performance under traffic rules. The dataset contains 250 hours videos with high-quality annotation to facilitate the development of PAD behavior analysis. Experimental results on the constructed benchmark show that PADriver outperforms state-of-the-art approaches on different evaluation metrics, and enables various driving modes.
LMS-Net: A Learned Mumford-Shah Network For Few-Shot Medical Image Segmentation
Feb 08, 2025



Few-shot semantic segmentation (FSS) methods have shown great promise in handling data-scarce scenarios, particularly in medical image segmentation tasks. However, most existing FSS architectures lack sufficient interpretability and fail to fully incorporate the underlying physical structures of semantic regions. To address these issues, in this paper, we propose a novel deep unfolding network, called the Learned Mumford-Shah Network (LMS-Net), for the FSS task. Specifically, motivated by the effectiveness of pixel-to-prototype comparison in prototypical FSS methods and the capability of deep priors to model complex spatial structures, we leverage our learned Mumford-Shah model (LMS model) as a mathematical foundation to integrate these insights into a unified framework. By reformulating the LMS model into prototype update and mask update tasks, we propose an alternating optimization algorithm to solve it efficiently. Further, the iterative steps of this algorithm are unfolded into corresponding network modules, resulting in LMS-Net with clear interpretability. Comprehensive experiments on three publicly available medical segmentation datasets verify the effectiveness of our method, demonstrating superior accuracy and robustness in handling complex structures and adapting to challenging segmentation scenarios. These results highlight the potential of LMS-Net to advance FSS in medical imaging applications. Our code will be available at: https://github.com/SDZhang01/LMSNet
RoboMatrix: A Skill-centric Hierarchical Framework for Scalable Robot Task Planning and Execution in Open-World
Nov 29, 2024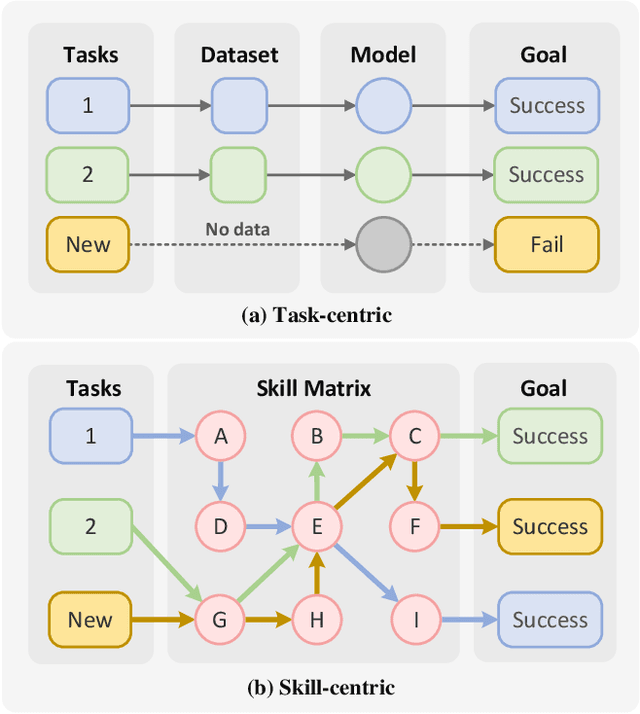

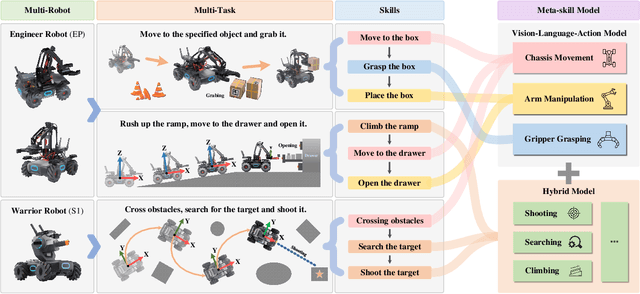

Existing policy learning methods predominantly adopt the task-centric paradigm, necessitating the collection of task data in an end-to-end manner. Consequently, the learned policy tends to fail to tackle novel tasks. Moreover, it is hard to localize the errors for a complex task with multiple stages due to end-to-end learning. To address these challenges, we propose RoboMatrix, a skill-centric and hierarchical framework for scalable task planning and execution. We first introduce a novel skill-centric paradigm that extracts the common meta-skills from different complex tasks. This allows for the capture of embodied demonstrations through a kill-centric approach, enabling the completion of open-world tasks by combining learned meta-skills. To fully leverage meta-skills, we further develop a hierarchical framework that decouples complex robot tasks into three interconnected layers: (1) a high-level modular scheduling layer; (2) a middle-level skill layer; and (3) a low-level hardware layer. Experimental results illustrate that our skill-centric and hierarchical framework achieves remarkable generalization performance across novel objects, scenes, tasks, and embodiments. This framework offers a novel solution for robot task planning and execution in open-world scenarios. Our software and hardware are available at https://github.com/WayneMao/RoboMatrix.
RoboGSim: A Real2Sim2Real Robotic Gaussian Splatting Simulator
Nov 18, 2024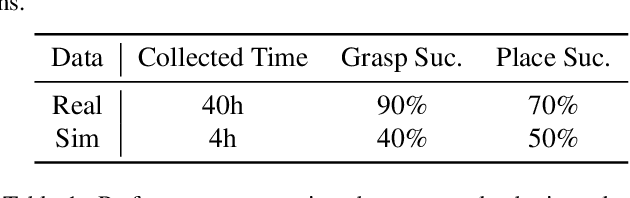
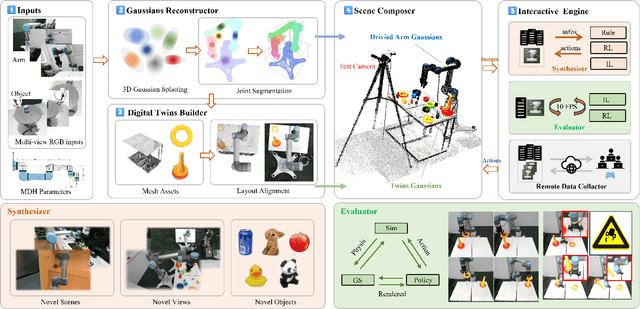


Efficient acquisition of real-world embodied data has been increasingly critical. However, large-scale demonstrations captured by remote operation tend to take extremely high costs and fail to scale up the data size in an efficient manner. Sampling the episodes under a simulated environment is a promising way for large-scale collection while existing simulators fail to high-fidelity modeling on texture and physics. To address these limitations, we introduce the RoboGSim, a real2sim2real robotic simulator, powered by 3D Gaussian Splatting and the physics engine. RoboGSim mainly includes four parts: Gaussian Reconstructor, Digital Twins Builder, Scene Composer, and Interactive Engine. It can synthesize the simulated data with novel views, objects, trajectories, and scenes. RoboGSim also provides an online, reproducible, and safe evaluation for different manipulation policies. The real2sim and sim2real transfer experiments show a high consistency in the texture and physics. Moreover, the effectiveness of synthetic data is validated under the real-world manipulated tasks. We hope RoboGSim serves as a closed-loop simulator for fair comparison on policy learning. More information can be found on our project page https://robogsim.github.io/ .
Super-resolving Real-world Image Illumination Enhancement: A New Dataset and A Conditional Diffusion Model
Oct 16, 2024



Most existing super-resolution methods and datasets have been developed to improve the image quality in well-lighted conditions. However, these methods do not work well in real-world low-light conditions as the images captured in such conditions lose most important information and contain significant unknown noises. To solve this problem, we propose a SRRIIE dataset with an efficient conditional diffusion probabilistic models-based method. The proposed dataset contains 4800 paired low-high quality images. To ensure that the dataset are able to model the real-world image degradation in low-illumination environments, we capture images using an ILDC camera and an optical zoom lens with exposure levels ranging from -6 EV to 0 EV and ISO levels ranging from 50 to 12800. We comprehensively evaluate with various reconstruction and perceptual metrics and demonstrate the practicabilities of the SRRIIE dataset for deep learning-based methods. We show that most existing methods are less effective in preserving the structures and sharpness of restored images from complicated noises. To overcome this problem, we revise the condition for Raw sensor data and propose a novel time-melding condition for diffusion probabilistic model. Comprehensive quantitative and qualitative experimental results on the real-world benchmark datasets demonstrate the feasibility and effectivenesses of the proposed conditional diffusion probabilistic model on Raw sensor data. Code and dataset will be available at https://github.com/Yaofang-Liu/Super-Resolving
SegGrasp: Zero-Shot Task-Oriented Grasping via Semantic and Geometric Guided Segmentation
Oct 11, 2024



Task-oriented grasping, which involves grasping specific parts of objects based on their functions, is crucial for developing advanced robotic systems capable of performing complex tasks in dynamic environments. In this paper, we propose a training-free framework that incorporates both semantic and geometric priors for zero-shot task-oriented grasp generation. The proposed framework, SegGrasp, first leverages the vision-language models like GLIP for coarse segmentation. It then uses detailed geometric information from convex decomposition to improve segmentation quality through a fusion policy named GeoFusion. An effective grasp pose can be generated by a grasping network with improved segmentation. We conducted the experiments on both segmentation benchmark and real-world robot grasping. The experimental results show that SegGrasp surpasses the baseline by more than 15\% in grasp and segmentation performance.
Toward Robust Early Detection of Alzheimer's Disease via an Integrated Multimodal Learning Approach
Aug 29, 2024


Alzheimer's Disease (AD) is a complex neurodegenerative disorder marked by memory loss, executive dysfunction, and personality changes. Early diagnosis is challenging due to subtle symptoms and varied presentations, often leading to misdiagnosis with traditional unimodal diagnostic methods due to their limited scope. This study introduces an advanced multimodal classification model that integrates clinical, cognitive, neuroimaging, and EEG data to enhance diagnostic accuracy. The model incorporates a feature tagger with a tabular data coding architecture and utilizes the TimesBlock module to capture intricate temporal patterns in Electroencephalograms (EEG) data. By employing Cross-modal Attention Aggregation module, the model effectively fuses Magnetic Resonance Imaging (MRI) spatial information with EEG temporal data, significantly improving the distinction between AD, Mild Cognitive Impairment, and Normal Cognition. Simultaneously, we have constructed the first AD classification dataset that includes three modalities: EEG, MRI, and tabular data. Our innovative approach aims to facilitate early diagnosis and intervention, potentially slowing the progression of AD. The source code and our private ADMC dataset are available at https://github.com/JustlfC03/MSTNet.