 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Unsupervised Domain Adaptation for 3D Point Cloud Segmentation Under Source Adversarial Attacks
Apr 03, 2025Unsupervised domain adaptation (UDA) frameworks have shown good generalization capabilities for 3D point cloud semantic segmentation models on clean data. However, existing works overlook adversarial robustness when the source domain itself is compromised. To comprehensively explore the robustness of the UDA frameworks, we first design a stealthy adversarial point cloud generation attack that can significantly contaminate datasets with only minor perturbations to the point cloud surface. Based on that, we propose a novel dataset, AdvSynLiDAR, comprising synthesized contaminated LiDAR point clouds. With the generated corrupted data, we further develop the Adversarial Adaptation Framework (AAF) as the countermeasure. Specifically, by extending the key point sensitive (KPS) loss towards the Robust Long-Tail loss (RLT loss) and utilizing a decoder branch, our approach enables the model to focus on long-tail classes during the pre-training phase and leverages high-confidence decoded point cloud information to restore point cloud structures during the adaptation phase. We evaluated our AAF method on the AdvSynLiDAR dataset, where the results demonstrate that our AAF method can mitigate performance degradation under source adversarial perturbations for UDA in the 3D point cloud segmentation application.
Overlap-Aware Feature Learning for Robust Unsupervised Domain Adaptation for 3D Semantic Segmentation
Apr 02, 2025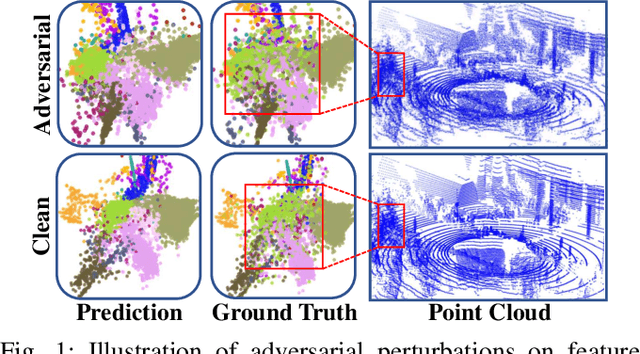
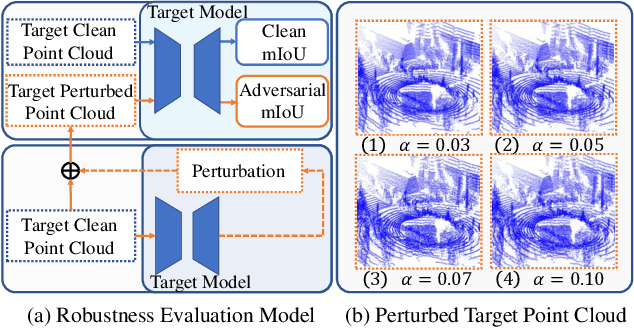


3D point cloud semantic segmentation (PCSS) is a cornerstone for environmental perception in robotic systems and autonomous driving, enabling precise scene understanding through point-wise classification. While unsupervised domain adaptation (UDA) mitigates label scarcity in PCSS, existing methods critically overlook the inherent vulnerability to real-world perturbations (e.g., snow, fog, rain) and adversarial distortions. This work first identifies two intrinsic limitations that undermine current PCSS-UDA robustness: (a) unsupervised features overlap from unaligned boundaries in shared-class regions and (b) feature structure erosion caused by domain-invariant learning that suppresses target-specific patterns. To address the proposed problems, we propose a tripartite framework consisting of: 1) a robustness evaluation model quantifying resilience against adversarial attack/corruption types through robustness metrics; 2) an invertible attention alignment module (IAAM) enabling bidirectional domain mapping while preserving discriminative structure via attention-guided overlap suppression; and 3) a contrastive memory bank with quality-aware contrastive learning that progressively refines pseudo-labels with feature quality for more discriminative representations. Extensive experiments on SynLiDAR-to-SemanticPOSS adaptation demonstrate a maximum mIoU improvement of 14.3\% under adversarial attack.
ProtoGuard-guided PROPEL: Class-Aware Prototype Enhancement and Progressive Labeling for Incremental 3D Point Cloud Segmentation
Apr 02, 2025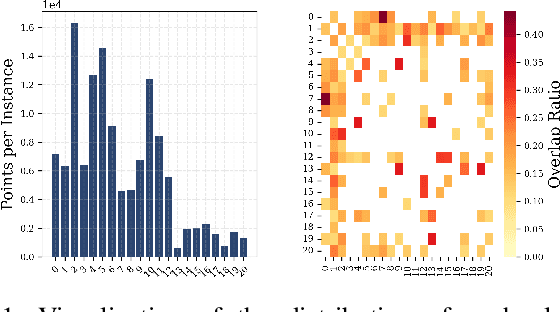



3D point cloud semantic segmentation technology has been widely used. However, in real-world scenarios, the environment is evolving. Thus, offline-trained segmentation models may lead to catastrophic forgetting of previously seen classes. Class-incremental learning (CIL) is designed to address the problem of catastrophic forgetting. While point clouds are common, we observe high similarity and unclear boundaries between different classes. Meanwhile, they are known to be imbalanced in class distribution. These lead to issues including misclassification between similar classes and the long-tail problem, which have not been adequately addressed in previous CIL methods. We thus propose ProtoGuard and PROPEL (Progressive Refinement Of PsEudo-Labels). In the base-class training phase, ProtoGuard maintains geometric and semantic prototypes for each class, which are combined into prototype features using an attention mechanism. In the novel-class training phase, PROPEL inherits the base feature extractor and classifier, guiding pseudo-label propagation and updates based on density distribution and semantic similarity. Extensive experiments show that our approach achieves remarkable results on both the S3DIS and ScanNet datasets, improving the mIoU of 3D point cloud segmentation by a maximum of 20.39% under the 5-step CIL scenario on S3DIS.
Multi-GraspLLM: A Multimodal LLM for Multi-Hand Semantic Guided Grasp Generation
Dec 11, 2024


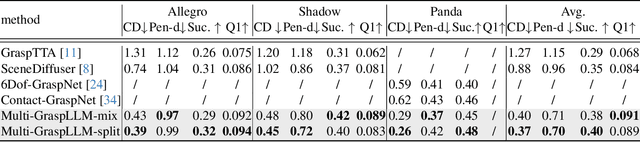
Multi-hand semantic grasp generation aims to generate feasible and semantically appropriate grasp poses for different robotic hands based on natural language instructions. Although the task is highly valuable, due to the lack of multi-hand grasp datasets with fine-grained contact description between robotic hands and objects, it is still a long-standing difficult task. In this paper, we present Multi-GraspSet, the first large-scale multi-hand grasp dataset with automatically contact annotations. Based on Multi-GraspSet, we propose Multi-GraspLLM, a unified language-guided grasp generation framework. It leverages large language models (LLM) to handle variable-length sequences, generating grasp poses for diverse robotic hands in a single unified architecture. Multi-GraspLLM first aligns the encoded point cloud features and text features into a unified semantic space. It then generates grasp bin tokens which are subsequently converted into grasp pose for each robotic hand via hand-aware linear mapping. The experimental results demonstrate that our approach significantly outperforms existing methods on Multi-GraspSet. More information can be found on our project page https://multi-graspllm.github.io.
SegGrasp: Zero-Shot Task-Oriented Grasping via Semantic and Geometric Guided Segmentation
Oct 11, 2024



Task-oriented grasping, which involves grasping specific parts of objects based on their functions, is crucial for developing advanced robotic systems capable of performing complex tasks in dynamic environments. In this paper, we propose a training-free framework that incorporates both semantic and geometric priors for zero-shot task-oriented grasp generation. The proposed framework, SegGrasp, first leverages the vision-language models like GLIP for coarse segmentation. It then uses detailed geometric information from convex decomposition to improve segmentation quality through a fusion policy named GeoFusion. An effective grasp pose can be generated by a grasping network with improved segmentation. We conducted the experiments on both segmentation benchmark and real-world robot grasping. The experimental results show that SegGrasp surpasses the baseline by more than 15\% in grasp and segmentation performance.