 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpatialActor: Exploring Disentangled Spatial Representations for Robust Robotic Manipulation
Nov 12, 2025Robotic manipulation requires precise spatial understanding to interact with objects in the real world. Point-based methods suffer from sparse sampling, leading to the loss of fine-grained semantics. Image-based methods typically feed RGB and depth into 2D backbones pre-trained on 3D auxiliary tasks, but their entangled semantics and geometry are sensitive to inherent depth noise in real-world that disrupts semantic understanding. Moreover, these methods focus on high-level geometry while overlooking low-level spatial cues essential for precise interaction. We propose SpatialActor, a disentangled framework for robust robotic manipulation that explicitly decouples semantics and geometry. The Semantic-guided Geometric Module adaptively fuses two complementary geometry from noisy depth and semantic-guided expert priors. Also, a Spatial Transformer leverages low-level spatial cues for accurate 2D-3D mapping and enables interaction among spatial features. We evaluate SpatialActor on multiple simulation and real-world scenarios across 50+ tasks. It achieves state-of-the-art performance with 87.4% on RLBench and improves by 13.9% to 19.4% under varying noisy conditions, showing strong robustness. Moreover, it significantly enhances few-shot generalization to new tasks and maintains robustness under various spatial perturbations. Project Page: https://shihao1895.github.io/SpatialActor
Running VLAs at Real-time Speed
Oct 30, 2025In this paper, we show how to run pi0-level multi-view VLA at 30Hz frame rate and at most 480Hz trajectory frequency using a single consumer GPU. This enables dynamic and real-time tasks that were previously believed to be unattainable by large VLA models. To achieve it, we introduce a bag of strategies to eliminate the overheads in model inference. The real-world experiment shows that the pi0 policy with our strategy achieves a 100% success rate in grasping a falling pen task. Based on the results, we further propose a full streaming inference framework for real-time robot control of VLA. Code is available at https://github.com/Dexmal/realtime-vla.
MemoryVLA: Perceptual-Cognitive Memory in Vision-Language-Action Models for Robotic Manipulation
Aug 26, 2025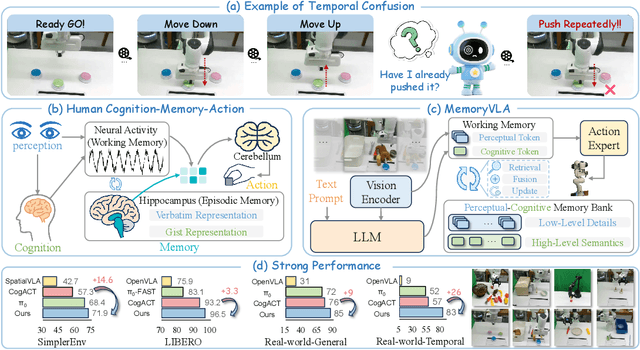
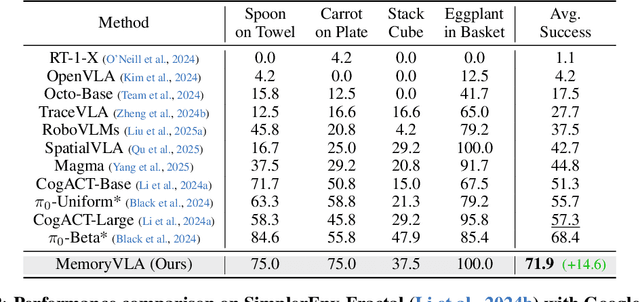
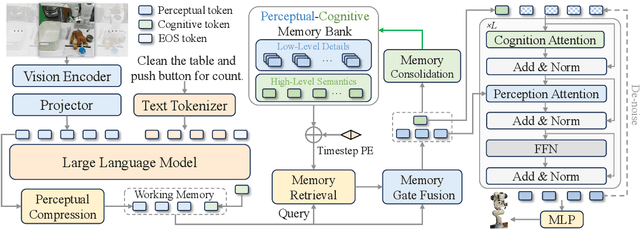
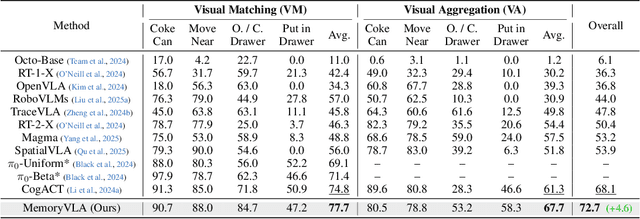
Temporal context is essential for robotic manipulation because such tasks are inherently non-Markovian, yet mainstream VLA models typically overlook it and struggle with long-horizon, temporally dependent tasks. Cognitive science suggests that humans rely on working memory to buffer short-lived representations for immediate control, while the hippocampal system preserves verbatim episodic details and semantic gist of past experience for long-term memory. Inspired by these mechanisms, we propose MemoryVLA, a Cognition-Memory-Action framework for long-horizon robotic manipulation. A pretrained VLM encodes the observation into perceptual and cognitive tokens that form working memory, while a Perceptual-Cognitive Memory Bank stores low-level details and high-level semantics consolidated from it. Working memory retrieves decision-relevant entries from the bank, adaptively fuses them with current tokens, and updates the bank by merging redundancies. Using these tokens, a memory-conditioned diffusion action expert yields temporally aware action sequences. We evaluate MemoryVLA on 150+ simulation and real-world tasks across three robots. On SimplerEnv-Bridge, Fractal, and LIBERO-5 suites, it achieves 71.9%, 72.7%, and 96.5% success rates, respectively, all outperforming state-of-the-art baselines CogACT and pi-0, with a notable +14.6 gain on Bridge. On 12 real-world tasks spanning general skills and long-horizon temporal dependencies, MemoryVLA achieves 84.0% success rate, with long-horizon tasks showing a +26 improvement over state-of-the-art baseline. Project Page: https://shihao1895.github.io/MemoryVLA
ROSA: Harnessing Robot States for Vision-Language and Action Alignment
Jun 16, 2025Vision-Language-Action (VLA) models have recently made significant advance in multi-task, end-to-end robotic control, due to the strong generalization capabilities of Vision-Language Models (VLMs). A fundamental challenge in developing such models is effectively aligning the vision-language space with the robotic action space. Existing approaches typically rely on directly fine-tuning VLMs using expert demonstrations. However, this strategy suffers from a spatio-temporal gap, resulting in considerable data inefficiency and heavy reliance on human labor. Spatially, VLMs operate within a high-level semantic space, whereas robotic actions are grounded in low-level 3D physical space; temporally, VLMs primarily interpret the present, while VLA models anticipate future actions. To overcome these challenges, we propose a novel training paradigm, ROSA, which leverages robot state estimation to improve alignment between vision-language and action spaces. By integrating robot state estimation data obtained via an automated process, ROSA enables the VLA model to gain enhanced spatial understanding and self-awareness, thereby boosting performance and generalization. Extensive experiments in both simulated and real-world environments demonstrate the effectiveness of ROSA, particularly in low-data regimes.
Grounding Beyond Detection: Enhancing Contextual Understanding in Embodied 3D Grounding
Jun 05, 2025
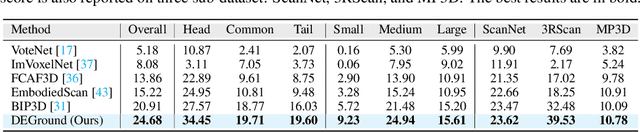
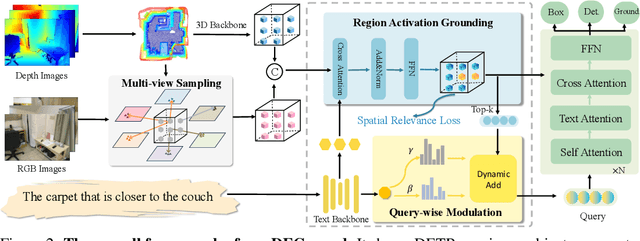
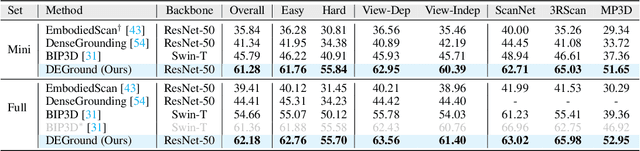
Embodied 3D grounding aims to localize target objects described in human instructions from ego-centric viewpoint. Most methods typically follow a two-stage paradigm where a trained 3D detector's optimized backbone parameters are used to initialize a grounding model. In this study, we explore a fundamental question: Does embodied 3D grounding benefit enough from detection? To answer this question, we assess the grounding performance of detection models using predicted boxes filtered by the target category. Surprisingly, these detection models without any instruction-specific training outperform the grounding models explicitly trained with language instructions. This indicates that even category-level embodied 3D grounding may not be well resolved, let alone more fine-grained context-aware grounding. Motivated by this finding, we propose DEGround, which shares DETR queries as object representation for both DEtection and Grounding and enables the grounding to benefit from basic category classification and box detection. Based on this framework, we further introduce a regional activation grounding module that highlights instruction-related regions and a query-wise modulation module that incorporates sentence-level semantic into the query representation, strengthening the context-aware understanding of language instructions. Remarkably, DEGround outperforms state-of-the-art model BIP3D by 7.52\% at overall accuracy on the EmbodiedScan validation set. The source code will be publicly available at https://github.com/zyn213/DEGround.
Ross3D: Reconstructive Visual Instruction Tuning with 3D-Awareness
Apr 02, 2025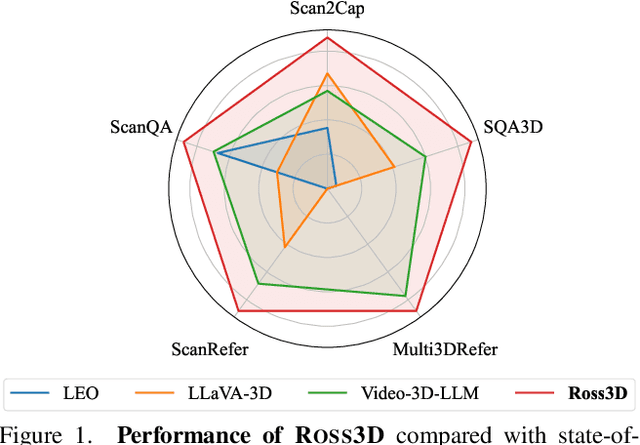
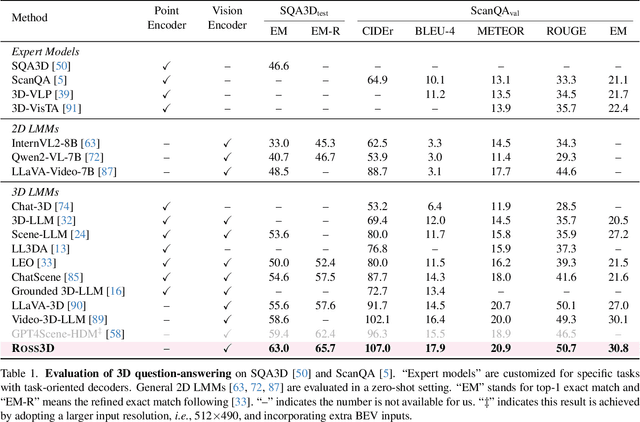
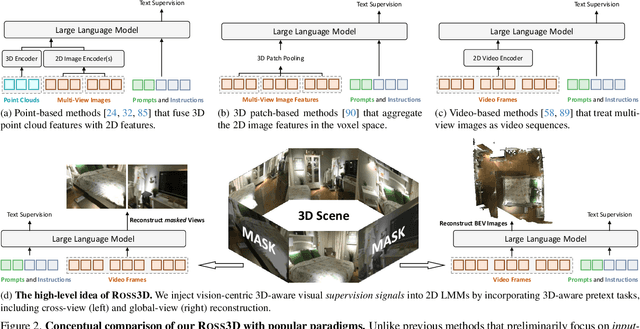
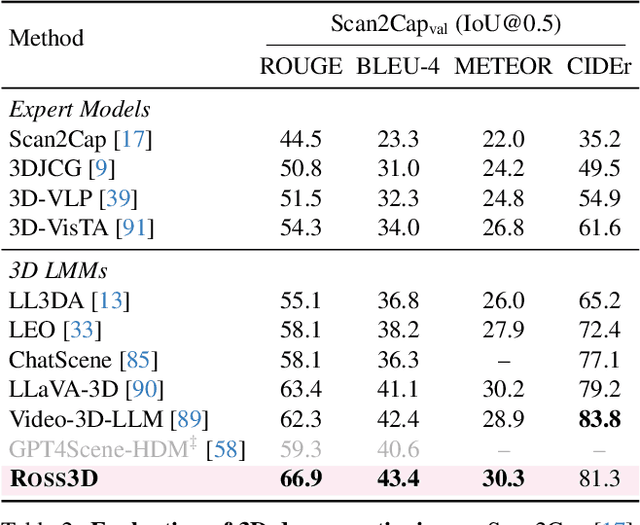
The rapid development of Large Multimodal Models (LMMs) for 2D images and videos has spurred efforts to adapt these models for interpreting 3D scenes. However, the absence of large-scale 3D vision-language datasets has posed a significant obstacle. To address this issue, typical approaches focus on injecting 3D awareness into 2D LMMs by designing 3D input-level scene representations. This work provides a new perspective. We introduce reconstructive visual instruction tuning with 3D-awareness (Ross3D), which integrates 3D-aware visual supervision into the training procedure. Specifically, it incorporates cross-view and global-view reconstruction. The former requires reconstructing masked views by aggregating overlapping information from other views. The latter aims to aggregate information from all available views to recover Bird's-Eye-View images, contributing to a comprehensive overview of the entire scene. Empirically, Ross3D achieves state-of-the-art performance across various 3D scene understanding benchmarks. More importantly, our semi-supervised experiments demonstrate significant potential in leveraging large amounts of unlabeled 3D vision-only data.
Multi-GraspLLM: A Multimodal LLM for Multi-Hand Semantic Guided Grasp Generation
Dec 11, 2024


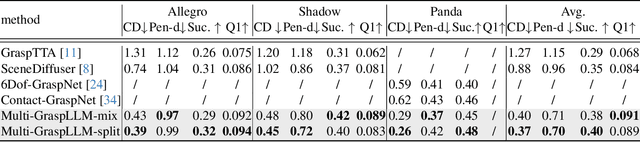
Multi-hand semantic grasp generation aims to generate feasible and semantically appropriate grasp poses for different robotic hands based on natural language instructions. Although the task is highly valuable, due to the lack of multi-hand grasp datasets with fine-grained contact description between robotic hands and objects, it is still a long-standing difficult task. In this paper, we present Multi-GraspSet, the first large-scale multi-hand grasp dataset with automatically contact annotations. Based on Multi-GraspSet, we propose Multi-GraspLLM, a unified language-guided grasp generation framework. It leverages large language models (LLM) to handle variable-length sequences, generating grasp poses for diverse robotic hands in a single unified architecture. Multi-GraspLLM first aligns the encoded point cloud features and text features into a unified semantic space. It then generates grasp bin tokens which are subsequently converted into grasp pose for each robotic hand via hand-aware linear mapping. The experimental results demonstrate that our approach significantly outperforms existing methods on Multi-GraspSet. More information can be found on our project page https://multi-graspllm.github.io.
FlowPolicy: Enabling Fast and Robust 3D Flow-based Policy via Consistency Flow Matching for Robot Manipulation
Dec 06, 2024Robots can acquire complex manipulation skills by learning policies from expert demonstrations, which is often known as vision-based imitation learning. Generating policies based on diffusion and flow matching models has been shown to be effective, particularly in robotics manipulation tasks. However, recursion-based approaches are often inference inefficient in working from noise distributions to policy distributions, posing a challenging trade-off between efficiency and quality. This motivates us to propose FlowPolicy, a novel framework for fast policy generation based on consistency flow matching and 3D vision. Our approach refines the flow dynamics by normalizing the self-consistency of the velocity field, enabling the model to derive task execution policies in a single inference step. Specifically, FlowPolicy conditions on the observed 3D point cloud, where consistency flow matching directly defines straight-line flows from different time states to the same action space, while simultaneously constraining their velocity values, that is, we approximate the trajectories from noise to robot actions by normalizing the self-consistency of the velocity field within the action space, thus improving the inference efficiency. We validate the effectiveness of FlowPolicy on Adroit and Metaworld, demonstrating a 7$\times$ increase in inference speed while maintaining competitive average success rates compared to state-of-the-art policy models. Codes will be made publicly available.
RoboMatrix: A Skill-centric Hierarchical Framework for Scalable Robot Task Planning and Execution in Open-World
Nov 29, 2024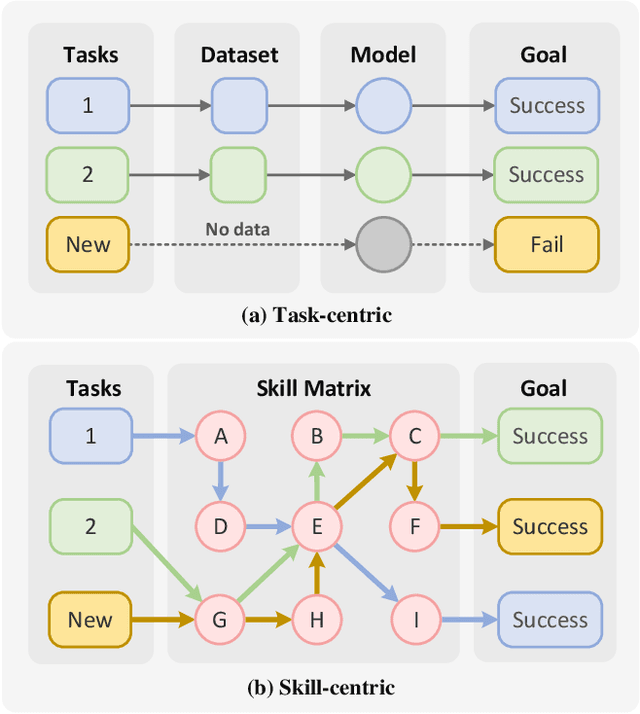

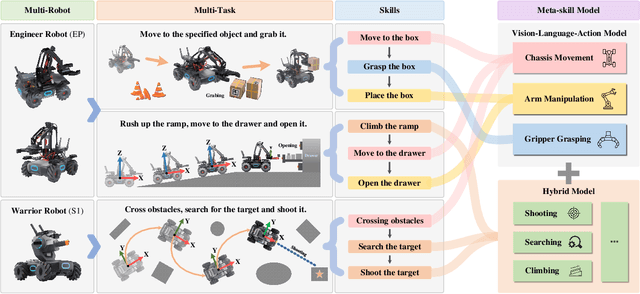

Existing policy learning methods predominantly adopt the task-centric paradigm, necessitating the collection of task data in an end-to-end manner. Consequently, the learned policy tends to fail to tackle novel tasks. Moreover, it is hard to localize the errors for a complex task with multiple stages due to end-to-end learning. To address these challenges, we propose RoboMatrix, a skill-centric and hierarchical framework for scalable task planning and execution. We first introduce a novel skill-centric paradigm that extracts the common meta-skills from different complex tasks. This allows for the capture of embodied demonstrations through a kill-centric approach, enabling the completion of open-world tasks by combining learned meta-skills. To fully leverage meta-skills, we further develop a hierarchical framework that decouples complex robot tasks into three interconnected layers: (1) a high-level modular scheduling layer; (2) a middle-level skill layer; and (3) a low-level hardware layer. Experimental results illustrate that our skill-centric and hierarchical framework achieves remarkable generalization performance across novel objects, scenes, tasks, and embodiments. This framework offers a novel solution for robot task planning and execution in open-world scenarios. Our software and hardware are available at https://github.com/WayneMao/RoboMatrix.
RoboGSim: A Real2Sim2Real Robotic Gaussian Splatting Simulator
Nov 18, 2024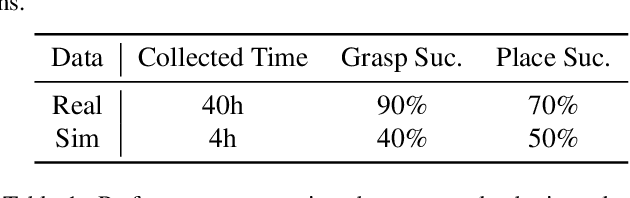
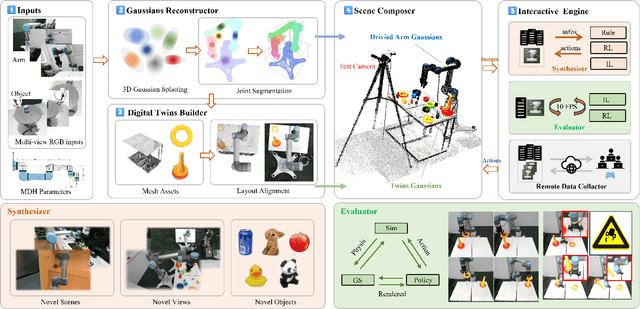


Efficient acquisition of real-world embodied data has been increasingly critical. However, large-scale demonstrations captured by remote operation tend to take extremely high costs and fail to scale up the data size in an efficient manner. Sampling the episodes under a simulated environment is a promising way for large-scale collection while existing simulators fail to high-fidelity modeling on texture and physics. To address these limitations, we introduce the RoboGSim, a real2sim2real robotic simulator, powered by 3D Gaussian Splatting and the physics engine. RoboGSim mainly includes four parts: Gaussian Reconstructor, Digital Twins Builder, Scene Composer, and Interactive Engine. It can synthesize the simulated data with novel views, objects, trajectories, and scenes. RoboGSim also provides an online, reproducible, and safe evaluation for different manipulation policies. The real2sim and sim2real transfer experiments show a high consistency in the texture and physics. Moreover, the effectiveness of synthetic data is validated under the real-world manipulated tasks. We hope RoboGSim serves as a closed-loop simulator for fair comparison on policy learning. More information can be found on our project page https://robogsim.github.io/ .