 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNon-Contrast CT Esophageal Varices Grading through Clinical Prior-Enhanced Multi-Organ Analysis
Dec 22, 2025Esophageal varices (EV) represent a critical complication of portal hypertension, affecting approximately 60% of cirrhosis patients with a significant bleeding risk of ~30%. While traditionally diagnosed through invasive endoscopy, non-contrast computed tomography (NCCT) presents a potential non-invasive alternative that has yet to be fully utilized in clinical practice. We present Multi-Organ-COhesion Network++ (MOON++), a novel multimodal framework that enhances EV assessment through comprehensive analysis of NCCT scans. Inspired by clinical evidence correlating organ volumetric relationships with liver disease severity, MOON++ synthesizes imaging characteristics of the esophagus, liver, and spleen through multimodal learning. We evaluated our approach using 1,631 patients, those with endoscopically confirmed EV were classified into four severity grades. Validation in 239 patient cases and independent testing in 289 cases demonstrate superior performance compared to conventional single organ methods, achieving an AUC of 0.894 versus 0.803 for the severe grade EV classification (G3 versus <G3) and 0.921 versus 0.793 for the differentiation of moderate to severe grades (>=G2 versus <G2). We conducted a reader study involving experienced radiologists to further validate the performance of MOON++. To our knowledge, MOON++ represents the first comprehensive multi-organ NCCT analysis framework incorporating clinical knowledge priors for EV assessment, potentially offering a promising non-invasive diagnostic alternative.
MergeDNA: Context-aware Genome Modeling with Dynamic Tokenization through Token Merging
Nov 17, 2025



Modeling genomic sequences faces two unsolved challenges: the information density varies widely across different regions, while there is no clearly defined minimum vocabulary unit. Relying on either four primitive bases or independently designed DNA tokenizers, existing approaches with naive masked language modeling pre-training often fail to adapt to the varying complexities of genomic sequences. Leveraging Token Merging techniques, this paper introduces a hierarchical architecture that jointly optimizes a dynamic genomic tokenizer and latent Transformers with context-aware pre-training tasks. As for network structures, the tokenization module automatically chunks adjacent bases into words by stacking multiple layers of the differentiable token merging blocks with local-window constraints, then a Latent Encoder captures the global context of these merged words by full-attention blocks. Symmetrically employing a Latent Decoder and a Local Decoder, MergeDNA learns with two pre-training tasks: Merged Token Reconstruction simultaneously trains the dynamic tokenization module and adaptively filters important tokens, while Adaptive Masked Token Modeling learns to predict these filtered tokens to capture informative contents. Extensive experiments show that MergeDNA achieves superior performance on three popular DNA benchmarks and several multi-omics tasks with fine-tuning or zero-shot evaluation, outperforming typical tokenization methods and large-scale DNA foundation models.
An Energy-Efficient Edge Coprocessor for Neural Rendering with Explicit Data Reuse Strategies
Oct 09, 2025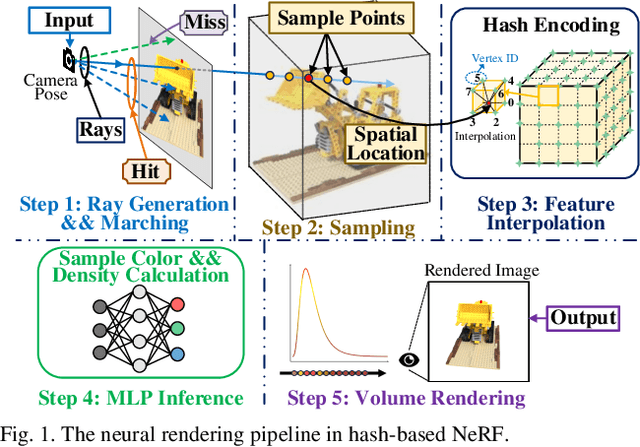
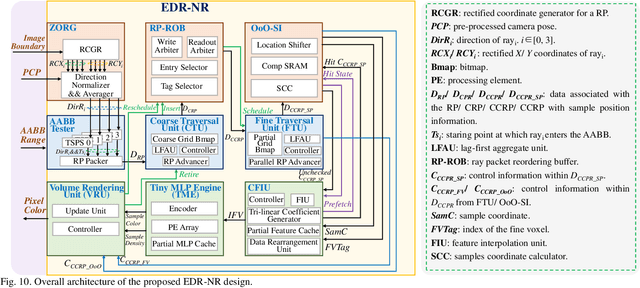
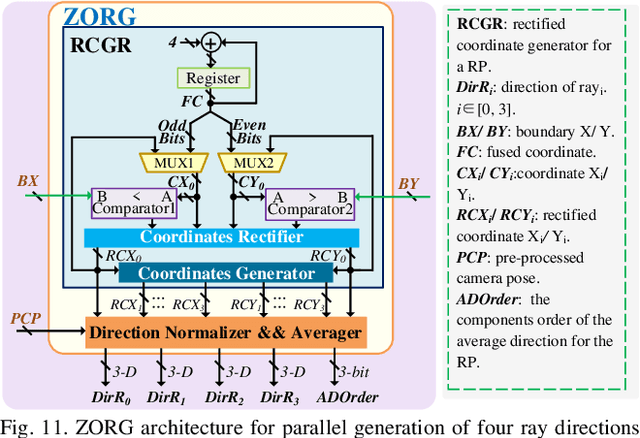
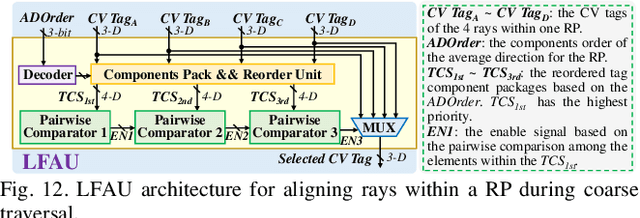
Neural radiance fields (NeRF) have transformed 3D reconstruction and rendering, facilitating photorealistic image synthesis from sparse viewpoints. This work introduces an explicit data reuse neural rendering (EDR-NR) architecture, which reduces frequent external memory accesses (EMAs) and cache misses by exploiting the spatial locality from three phases, including rays, ray packets (RPs), and samples. The EDR-NR architecture features a four-stage scheduler that clusters rays on the basis of Z-order, prioritize lagging rays when ray divergence happens, reorders RPs based on spatial proximity, and issues samples out-of-orderly (OoO) according to the availability of on-chip feature data. In addition, a four-tier hierarchical RP marching (HRM) technique is integrated with an axis-aligned bounding box (AABB) to facilitate spatial skipping (SS), reducing redundant computations and improving throughput. Moreover, a balanced allocation strategy for feature storage is proposed to mitigate SRAM bank conflicts. Fabricated using a 40 nm process with a die area of 10.5 mmX, the EDR-NR chip demonstrates a 2.41X enhancement in normalized energy efficiency, a 1.21X improvement in normalized area efficiency, a 1.20X increase in normalized throughput, and a 53.42% reduction in on-chip SRAM consumption compared to state-of-the-art accelerators.
Lifelong Evolution: Collaborative Learning between Large and Small Language Models for Continuous Emergent Fake News Detection
Jun 05, 2025The widespread dissemination of fake news on social media has significantly impacted society, resulting in serious consequences. Conventional deep learning methodologies employing small language models (SLMs) suffer from extensive supervised training requirements and difficulties adapting to evolving news environments due to data scarcity and distribution shifts. Large language models (LLMs), despite robust zero-shot capabilities, fall short in accurately detecting fake news owing to outdated knowledge and the absence of suitable demonstrations. In this paper, we propose a novel Continuous Collaborative Emergent Fake News Detection (C$^2$EFND) framework to address these challenges. The C$^2$EFND framework strategically leverages both LLMs' generalization power and SLMs' classification expertise via a multi-round collaborative learning framework. We further introduce a lifelong knowledge editing module based on a Mixture-of-Experts architecture to incrementally update LLMs and a replay-based continue learning method to ensure SLMs retain prior knowledge without retraining entirely. Extensive experiments on Pheme and Twitter16 datasets demonstrate that C$^2$EFND significantly outperforms existed methods, effectively improving detection accuracy and adaptability in continuous emergent fake news scenarios.
Refining Interactions: Enhancing Anisotropy in Graph Neural Networks with Language Semantics
Apr 02, 2025The integration of Large Language Models (LLMs) with Graph Neural Networks (GNNs) has recently been explored to enhance the capabilities of Text Attribute Graphs (TAGs). Most existing methods feed textual descriptions of the graph structure or neighbouring nodes' text directly into LLMs. However, these approaches often cause LLMs to treat structural information simply as general contextual text, thus limiting their effectiveness in graph-related tasks. In this paper, we introduce LanSAGNN (Language Semantic Anisotropic Graph Neural Network), a framework that extends the concept of anisotropic GNNs to the natural language level. This model leverages LLMs to extract tailor-made semantic information for node pairs, effectively capturing the unique interactions within node relationships. In addition, we propose an efficient dual-layer LLMs finetuning architecture to better align LLMs' outputs with graph tasks. Experimental results demonstrate that LanSAGNN significantly enhances existing LLM-based methods without increasing complexity while also exhibiting strong robustness against interference.
Collaborative Evolution: Multi-Round Learning Between Large and Small Language Models for Emergent Fake News Detection
Mar 27, 2025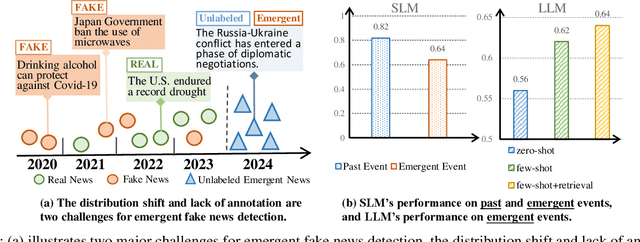
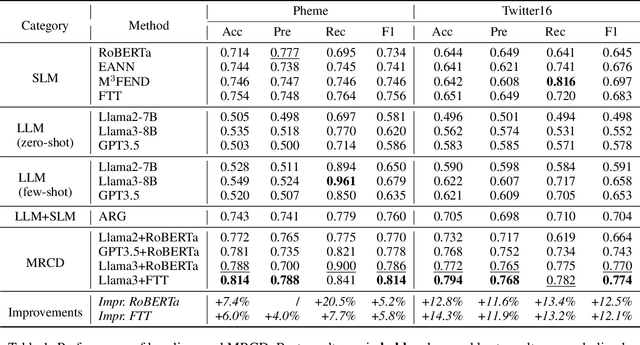
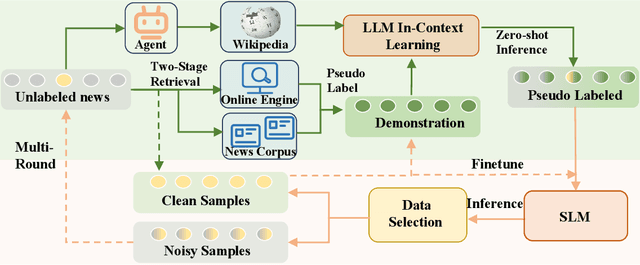
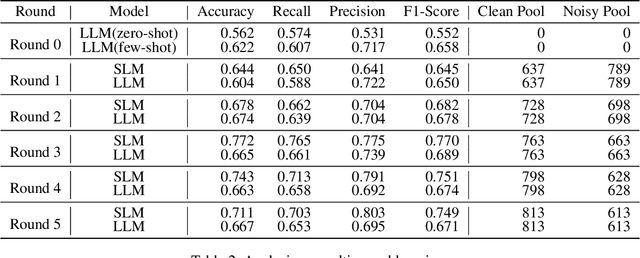
The proliferation of fake news on social media platforms has exerted a substantial influence on society, leading to discernible impacts and deleterious consequences. Conventional deep learning methodologies employing small language models (SLMs) suffer from the necessity for extensive supervised training and the challenge of adapting to rapidly evolving circumstances. Large language models (LLMs), despite their robust zero-shot capabilities, have fallen short in effectively identifying fake news due to a lack of pertinent demonstrations and the dynamic nature of knowledge. In this paper, a novel framework Multi-Round Collaboration Detection (MRCD) is proposed to address these aforementioned limitations. The MRCD framework is capable of enjoying the merits from both LLMs and SLMs by integrating their generalization abilities and specialized functionalities, respectively. Our approach features a two-stage retrieval module that selects relevant and up-to-date demonstrations and knowledge, enhancing in-context learning for better detection of emerging news events. We further design a multi-round learning framework to ensure more reliable detection results. Our framework MRCD achieves SOTA results on two real-world datasets Pheme and Twitter16, with accuracy improvements of 7.4\% and 12.8\% compared to using only SLMs, which effectively addresses the limitations of current models and improves the detection of emergent fake news.
Beyond Self-Talk: A Communication-Centric Survey of LLM-Based Multi-Agent Systems
Feb 20, 2025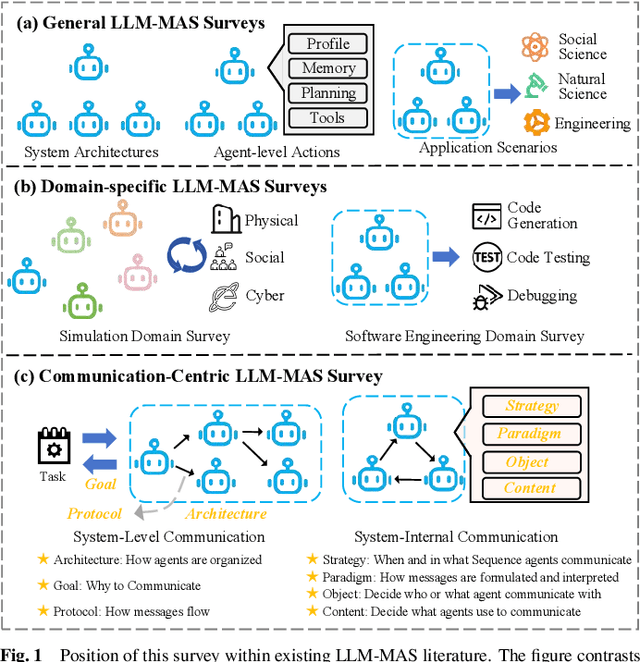
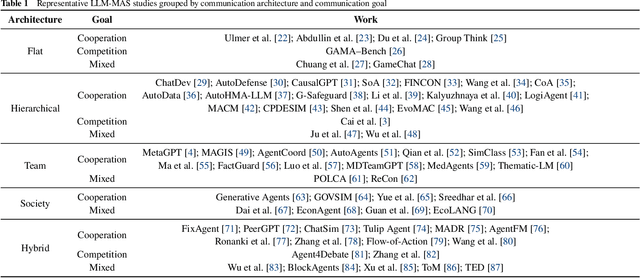
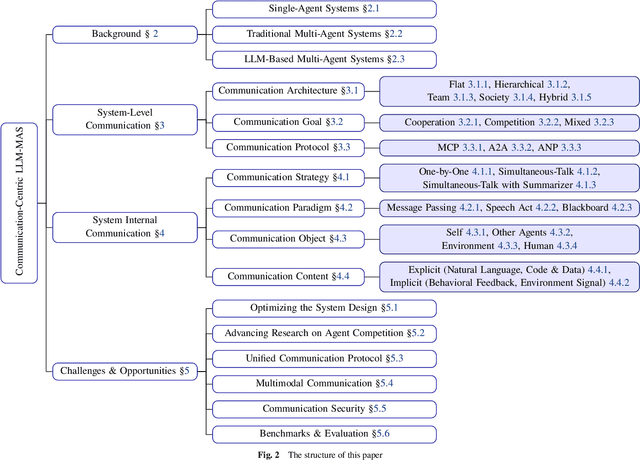
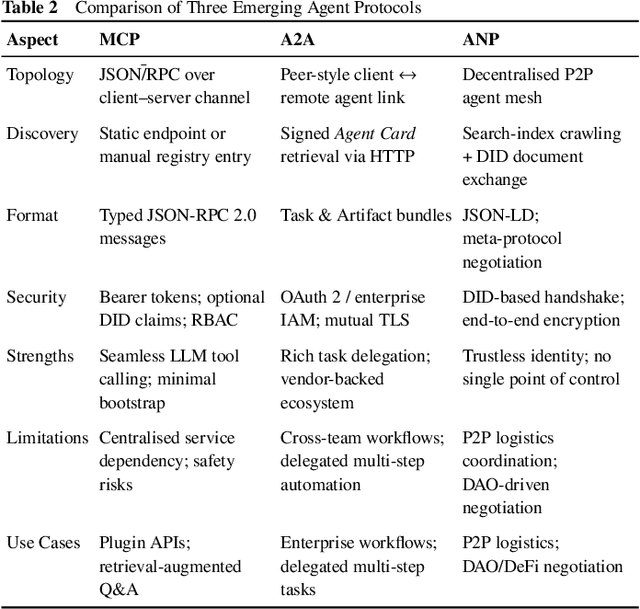
Large Language Models (LLMs) have recently demonstrated remarkable capabilities in reasoning, planning, and decision-making. Building upon these strengths, researchers have begun incorporating LLMs into multi-agent systems (MAS), where agents collaborate or compete through natural language interactions to tackle tasks beyond the scope of single-agent setups. In this survey, we present a communication-centric perspective on LLM-based multi-agent systems, examining key system-level features such as architecture design and communication goals, as well as internal mechanisms like communication strategies, paradigms, objects and content. We illustrate how these communication elements interplay to enable collective intelligence and flexible collaboration. Furthermore, we discuss prominent challenges, including scalability, security, and multimodal integration, and propose directions for future work to advance research in this emerging domain. Ultimately, this survey serves as a catalyst for further innovation, fostering more robust, scalable, and intelligent multi-agent systems across diverse application domains.
MAT: Multi-Range Attention Transformer for Efficient Image Super-Resolution
Nov 26, 2024



Recent advances in image super-resolution (SR) have significantly benefited from the incorporation of Transformer architectures. However, conventional techniques aimed at enlarging the self-attention window to capture broader contexts come with inherent drawbacks, especially the significantly increased computational demands. Moreover, the feature perception within a fixed-size window of existing models restricts the effective receptive fields and the intermediate feature diversity. This study demonstrates that a flexible integration of attention across diverse spatial extents can yield significant performance enhancements. In line with this insight, we introduce Multi-Range Attention Transformer (MAT) tailored for SR tasks. MAT leverages the computational advantages inherent in dilation operation, in conjunction with self-attention mechanism, to facilitate both multi-range attention (MA) and sparse multi-range attention (SMA), enabling efficient capture of both regional and sparse global features. Further coupled with local feature extraction, MAT adeptly capture dependencies across various spatial ranges, improving the diversity and efficacy of its feature representations. We also introduce the MSConvStar module, which augments the model's ability for multi-range representation learning. Comprehensive experiments show that our MAT exhibits superior performance to existing state-of-the-art SR models with remarkable efficiency (~3.3 faster than SRFormer-light).
Hierarchical Retrieval-Augmented Generation Model with Rethink for Multi-hop Question Answering
Aug 20, 2024Multi-hop Question Answering (QA) necessitates complex reasoning by integrating multiple pieces of information to resolve intricate questions. However, existing QA systems encounter challenges such as outdated information, context window length limitations, and an accuracy-quantity trade-off. To address these issues, we propose a novel framework, the Hierarchical Retrieval-Augmented Generation Model with Rethink (HiRAG), comprising Decomposer, Definer, Retriever, Filter, and Summarizer five key modules. We introduce a new hierarchical retrieval strategy that incorporates both sparse retrieval at the document level and dense retrieval at the chunk level, effectively integrating their strengths. Additionally, we propose a single-candidate retrieval method to mitigate the limitations of multi-candidate retrieval. We also construct two new corpora, Indexed Wikicorpus and Profile Wikicorpus, to address the issues of outdated and insufficient knowledge. Our experimental results on four datasets demonstrate that HiRAG outperforms state-of-the-art models across most metrics, and our Indexed Wikicorpus is effective. The code for HiRAG is available at https://github.com/2282588541a/HiRAG
Efficient Single Image Super-Resolution with Entropy Attention and Receptive Field Augmentation
Aug 08, 2024
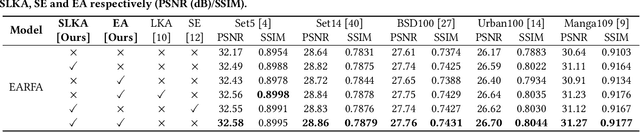

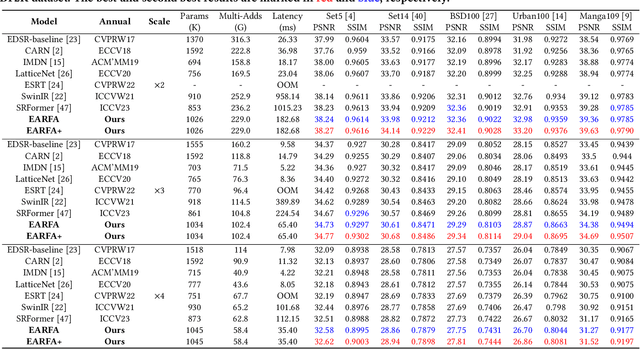
Transformer-based deep models for single image super-resolution (SISR) have greatly improved the performance of lightweight SISR tasks in recent years. However, they often suffer from heavy computational burden and slow inference due to the complex calculation of multi-head self-attention (MSA), seriously hindering their practical application and deployment. In this work, we present an efficient SR model to mitigate the dilemma between model efficiency and SR performance, which is dubbed Entropy Attention and Receptive Field Augmentation network (EARFA), and composed of a novel entropy attention (EA) and a shifting large kernel attention (SLKA). From the perspective of information theory, EA increases the entropy of intermediate features conditioned on a Gaussian distribution, providing more informative input for subsequent reasoning. On the other hand, SLKA extends the receptive field of SR models with the assistance of channel shifting, which also favors to boost the diversity of hierarchical features. Since the implementation of EA and SLKA does not involve complex computations (such as extensive matrix multiplications), the proposed method can achieve faster nonlinear inference than Transformer-based SR models while maintaining better SR performance. Extensive experiments show that the proposed model can significantly reduce the delay of model inference while achieving the SR performance comparable with other advanced models.