 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvo-Attacker: Memory-Augmented Reinforcement Learning for Long-Horizon Tool Attacks on LLM-MAS
May 25, 2026While Large Language Model-based Multi-Agent Systems (LLM-MAS) demonstrate remarkable capabilities in solving complex tasks by orchestrating specialized agents and external tools, the implicit trust in tool outputs creates a critical attack surface. Existing tool attacks are limited by domain specificity or fixed and static templates. To address these challenges, we propose Evo-Attacker, which formulates the tool attack as a self-evolving, memory-augmented reinforcement learning process. Evo-Attacker constructs a dynamic attack memory and employs deliberative reasoning to retrieve adversarial patterns and strategize modifying interventions at critical moments. Furthermore, we introduce Attack-Flow GRPO to optimize intermediate reasoning steps via terminal outcomes, addressing the long-horizon credit assignment challenge. Comprehensive experiments demonstrate that Evo-Attacker consistently outperforms baselines, highlighting its generalization and evolutionary capabilities and the urgent need for defensive tool safeguards.
ClawKeeper: Comprehensive Safety Protection for OpenClaw Agents Through Skills, Plugins, and Watchers
Mar 25, 2026OpenClaw has rapidly established itself as a leading open-source autonomous agent runtime, offering powerful capabilities including tool integration, local file access, and shell command execution. However, these broad operational privileges introduce critical security vulnerabilities, transforming model errors into tangible system-level threats such as sensitive data leakage, privilege escalation, and malicious third-party skill execution. Existing security measures for the OpenClaw ecosystem remain highly fragmented, addressing only isolated stages of the agent lifecycle rather than providing holistic protection. To bridge this gap, we present ClawKeeper, a real-time security framework that integrates multi-dimensional protection mechanisms across three complementary architectural layers. (1) \textbf{Skill-based protection} operates at the instruction level, injecting structured security policies directly into the agent context to enforce environment-specific constraints and cross-platform boundaries. (2) \textbf{Plugin-based protection} serves as an internal runtime enforcer, providing configuration hardening, proactive threat detection, and continuous behavioral monitoring throughout the execution pipeline. (3) \textbf{Watcher-based protection} introduces a novel, decoupled system-level security middleware that continuously verifies agent state evolution. It enables real-time execution intervention without coupling to the agent's internal logic, supporting operations such as halting high-risk actions or enforcing human confirmation. We argue that this Watcher paradigm holds strong potential to serve as a foundational building block for securing next-generation autonomous agent systems. Extensive qualitative and quantitative evaluations demonstrate the effectiveness and robustness of ClawKeeper across diverse threat scenarios. We release our code.
The Devil Behind Moltbook: Anthropic Safety is Always Vanishing in Self-Evolving AI Societies
Feb 11, 2026The emergence of multi-agent systems built from large language models (LLMs) offers a promising paradigm for scalable collective intelligence and self-evolution. Ideally, such systems would achieve continuous self-improvement in a fully closed loop while maintaining robust safety alignment--a combination we term the self-evolution trilemma. However, we demonstrate both theoretically and empirically that an agent society satisfying continuous self-evolution, complete isolation, and safety invariance is impossible. Drawing on an information-theoretic framework, we formalize safety as the divergence degree from anthropic value distributions. We theoretically demonstrate that isolated self-evolution induces statistical blind spots, leading to the irreversible degradation of the system's safety alignment. Empirical and qualitative results from an open-ended agent community (Moltbook) and two closed self-evolving systems reveal phenomena that align with our theoretical prediction of inevitable safety erosion. We further propose several solution directions to alleviate the identified safety concern. Our work establishes a fundamental limit on the self-evolving AI societies and shifts the discourse from symptom-driven safety patches to a principled understanding of intrinsic dynamical risks, highlighting the need for external oversight or novel safety-preserving mechanisms.
LANCET: Neural Intervention via Structural Entropy for Mitigating Faithfulness Hallucinations in LLMs
Jan 04, 2026Large Language Models have revolutionized information processing, yet their reliability is severely compromised by faithfulness hallucinations. While current approaches attempt to mitigate this issue through node-level adjustments or coarse suppression, they often overlook the distributed nature of neural information, leading to imprecise interventions. Recognizing that hallucinations propagate through specific forward transmission pathways like an infection, we aim to surgically block this flow using precise structural analysis. To leverage this, we propose Lancet, a novel framework that achieves precise neural intervention by leveraging structural entropy and hallucination difference ratios. Lancet first locates hallucination-prone neurons via gradient-driven contrastive analysis, then maps their propagation pathways by minimizing structural entropy, and finally implements a hierarchical intervention strategy that preserves general model capabilities. Comprehensive evaluations across hallucination benchmark datasets demonstrate that Lancet significantly outperforms state-of-the-art methods, validating the effectiveness of our surgical approach to neural intervention.
How Real is Your Jailbreak? Fine-grained Jailbreak Evaluation with Anchored Reference
Jan 04, 2026Jailbreak attacks present a significant challenge to the safety of Large Language Models (LLMs), yet current automated evaluation methods largely rely on coarse classifications that focus mainly on harmfulness, leading to substantial overestimation of attack success. To address this problem, we propose FJAR, a fine-grained jailbreak evaluation framework with anchored references. We first categorized jailbreak responses into five fine-grained categories: Rejective, Irrelevant, Unhelpful, Incorrect, and Successful, based on the degree to which the response addresses the malicious intent of the query. This categorization serves as the basis for FJAR. Then, we introduce a novel harmless tree decomposition approach to construct high-quality anchored references by breaking down the original queries. These references guide the evaluator in determining whether the response genuinely fulfills the original query. Extensive experiments demonstrate that FJAR achieves the highest alignment with human judgment and effectively identifies the root causes of jailbreak failures, providing actionable guidance for improving attack strategies.
Devil's Hand: Data Poisoning Attacks to Locally Private Graph Learning Protocols
Jun 11, 2025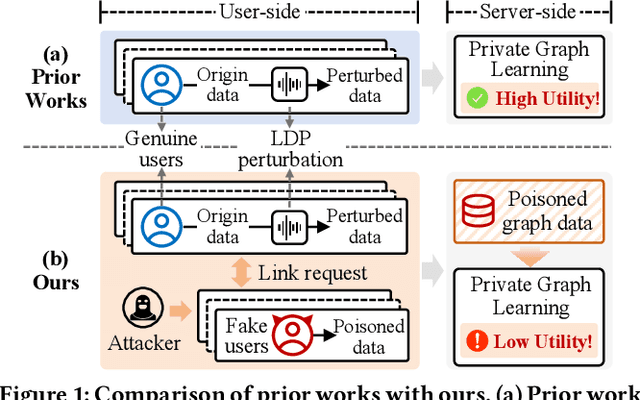
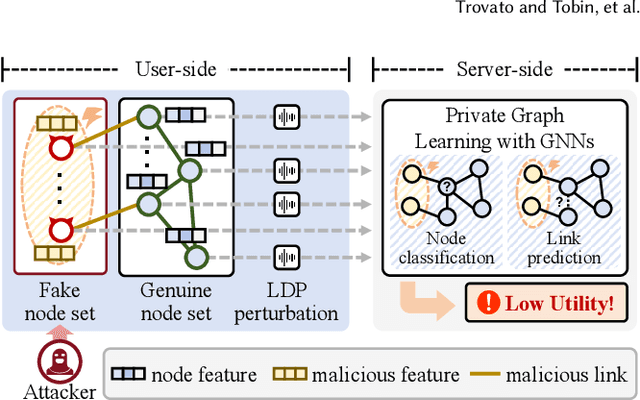
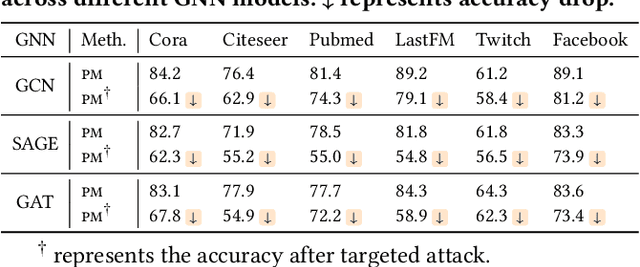
Graph neural networks (GNNs) have achieved significant success in graph representation learning and have been applied to various domains. However, many real-world graphs contain sensitive personal information, such as user profiles in social networks, raising serious privacy concerns when graph learning is performed using GNNs. To address this issue, locally private graph learning protocols have gained considerable attention. These protocols leverage the privacy advantages of local differential privacy (LDP) and the effectiveness of GNN's message-passing in calibrating noisy data, offering strict privacy guarantees for users' local data while maintaining high utility (e.g., node classification accuracy) for graph learning. Despite these advantages, such protocols may be vulnerable to data poisoning attacks, a threat that has not been considered in previous research. Identifying and addressing these threats is crucial for ensuring the robustness and security of privacy-preserving graph learning frameworks. This work introduces the first data poisoning attack targeting locally private graph learning protocols. The attacker injects fake users into the protocol, manipulates these fake users to establish links with genuine users, and sends carefully crafted data to the server, ultimately compromising the utility of private graph learning. The effectiveness of the attack is demonstrated both theoretically and empirically. In addition, several defense strategies have also been explored, but their limited effectiveness highlights the need for more robust defenses.
Lifelong Evolution: Collaborative Learning between Large and Small Language Models for Continuous Emergent Fake News Detection
Jun 05, 2025The widespread dissemination of fake news on social media has significantly impacted society, resulting in serious consequences. Conventional deep learning methodologies employing small language models (SLMs) suffer from extensive supervised training requirements and difficulties adapting to evolving news environments due to data scarcity and distribution shifts. Large language models (LLMs), despite robust zero-shot capabilities, fall short in accurately detecting fake news owing to outdated knowledge and the absence of suitable demonstrations. In this paper, we propose a novel Continuous Collaborative Emergent Fake News Detection (C$^2$EFND) framework to address these challenges. The C$^2$EFND framework strategically leverages both LLMs' generalization power and SLMs' classification expertise via a multi-round collaborative learning framework. We further introduce a lifelong knowledge editing module based on a Mixture-of-Experts architecture to incrementally update LLMs and a replay-based continue learning method to ensure SLMs retain prior knowledge without retraining entirely. Extensive experiments on Pheme and Twitter16 datasets demonstrate that C$^2$EFND significantly outperforms existed methods, effectively improving detection accuracy and adaptability in continuous emergent fake news scenarios.
Diffusion with a Linguistic Compass: Steering the Generation of Clinically Plausible Future sMRI Representations for Early MCI Conversion Prediction
Jun 05, 2025Early prediction of Mild Cognitive Impairment (MCI) conversion is hampered by a trade-off between immediacy--making fast predictions from a single baseline sMRI--and accuracy--leveraging longitudinal scans to capture disease progression. We propose MCI-Diff, a diffusion-based framework that synthesizes clinically plausible future sMRI representations directly from baseline data, achieving both real-time risk assessment and high predictive performance. First, a multi-task sequence reconstruction strategy trains a shared denoising network on interpolation and extrapolation tasks to handle irregular follow-up sampling and learn robust latent trajectories. Second, an LLM-driven "linguistic compass" is introduced for clinical plausibility sampling: generated feature candidates are quantized, tokenized, and scored by a fine-tuned language model conditioned on expected structural biomarkers, guiding autoregressive generation toward realistic disease patterns. Experiments on ADNI and AIBL cohorts show that MCI-Diff outperforms state-of-the-art baselines, improving early conversion accuracy by 5-12%.
Collaborative Evolution: Multi-Round Learning Between Large and Small Language Models for Emergent Fake News Detection
Mar 27, 2025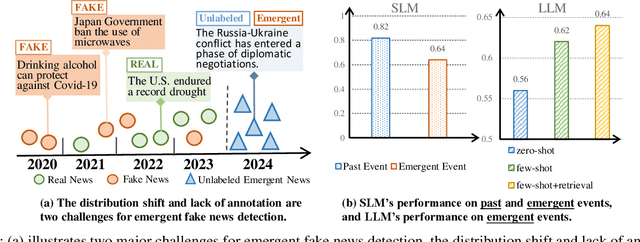
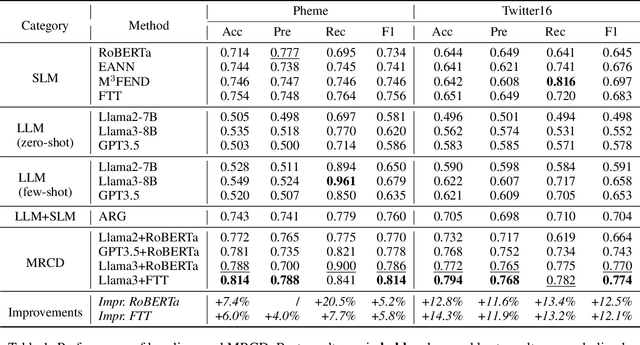
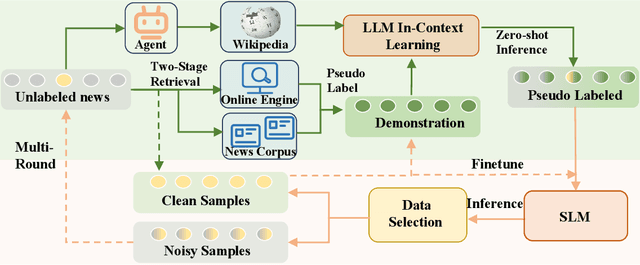
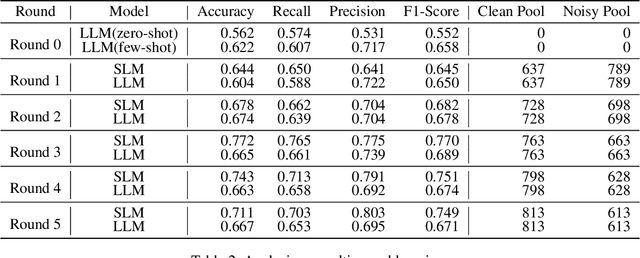
The proliferation of fake news on social media platforms has exerted a substantial influence on society, leading to discernible impacts and deleterious consequences. Conventional deep learning methodologies employing small language models (SLMs) suffer from the necessity for extensive supervised training and the challenge of adapting to rapidly evolving circumstances. Large language models (LLMs), despite their robust zero-shot capabilities, have fallen short in effectively identifying fake news due to a lack of pertinent demonstrations and the dynamic nature of knowledge. In this paper, a novel framework Multi-Round Collaboration Detection (MRCD) is proposed to address these aforementioned limitations. The MRCD framework is capable of enjoying the merits from both LLMs and SLMs by integrating their generalization abilities and specialized functionalities, respectively. Our approach features a two-stage retrieval module that selects relevant and up-to-date demonstrations and knowledge, enhancing in-context learning for better detection of emerging news events. We further design a multi-round learning framework to ensure more reliable detection results. Our framework MRCD achieves SOTA results on two real-world datasets Pheme and Twitter16, with accuracy improvements of 7.4\% and 12.8\% compared to using only SLMs, which effectively addresses the limitations of current models and improves the detection of emergent fake news.
MirrorGuard: Adaptive Defense Against Jailbreaks via Entropy-Guided Mirror Crafting
Mar 17, 2025Defending large language models (LLMs) against jailbreak attacks is crucial for ensuring their safe deployment. Existing defense strategies generally rely on predefined static criteria to differentiate between harmful and benign prompts. However, such rigid rules are incapable of accommodating the inherent complexity and dynamic nature of real jailbreak attacks. In this paper, we propose a novel concept of ``mirror'' to enable dynamic and adaptive defense. A mirror refers to a dynamically generated prompt that mirrors the syntactic structure of the input while ensuring semantic safety. The personalized discrepancies between the input prompts and their corresponding mirrors serve as the guiding principles for defense. A new defense paradigm, MirrorGuard, is further proposed to detect and calibrate risky inputs based on such mirrors. An entropy-based detection metric, Relative Input Uncertainty (RIU), is integrated into MirrorGuard to quantify the discrepancies between input prompts and mirrors. MirrorGuard is evaluated on several popular datasets, demonstrating state-of-the-art defense performance while maintaining general effectiveness.