 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond the Textual: Generating Coherent Visual Options for MCQs
Aug 26, 2025Multiple-choice questions (MCQs) play a crucial role in fostering deep thinking and knowledge integration in education. However, previous research has primarily focused on generating MCQs with textual options, but it largely overlooks the visual options. Moreover, generating high-quality distractors remains a major challenge due to the high cost and limited scalability of manual authoring. To tackle these problems, we propose a Cross-modal Options Synthesis (CmOS), a novel framework for generating educational MCQs with visual options. Our framework integrates Multimodal Chain-of-Thought (MCoT) reasoning process and Retrieval-Augmented Generation (RAG) to produce semantically plausible and visually similar answer and distractors. It also includes a discrimination module to identify content suitable for visual options. Experimental results on test tasks demonstrate the superiority of CmOS in content discrimination, question generation and visual option generation over existing methods across various subjects and educational levels.
Devil's Hand: Data Poisoning Attacks to Locally Private Graph Learning Protocols
Jun 11, 2025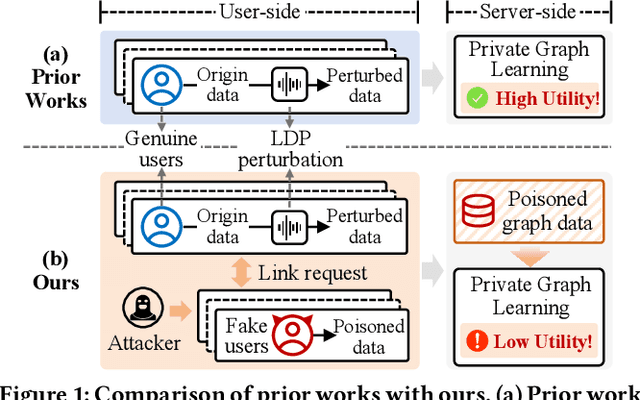
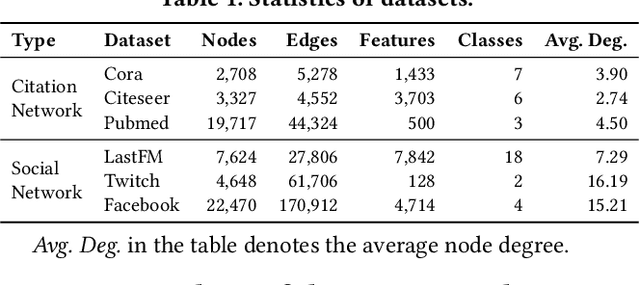
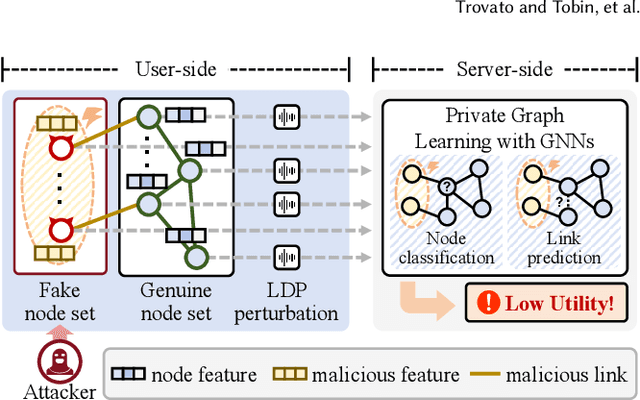
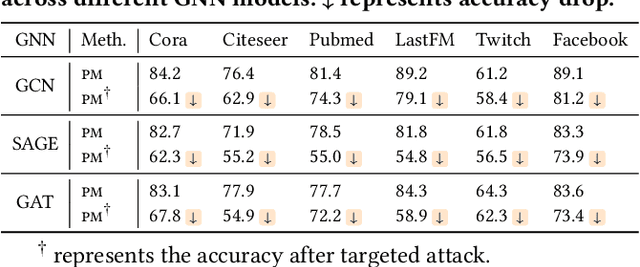
Graph neural networks (GNNs) have achieved significant success in graph representation learning and have been applied to various domains. However, many real-world graphs contain sensitive personal information, such as user profiles in social networks, raising serious privacy concerns when graph learning is performed using GNNs. To address this issue, locally private graph learning protocols have gained considerable attention. These protocols leverage the privacy advantages of local differential privacy (LDP) and the effectiveness of GNN's message-passing in calibrating noisy data, offering strict privacy guarantees for users' local data while maintaining high utility (e.g., node classification accuracy) for graph learning. Despite these advantages, such protocols may be vulnerable to data poisoning attacks, a threat that has not been considered in previous research. Identifying and addressing these threats is crucial for ensuring the robustness and security of privacy-preserving graph learning frameworks. This work introduces the first data poisoning attack targeting locally private graph learning protocols. The attacker injects fake users into the protocol, manipulates these fake users to establish links with genuine users, and sends carefully crafted data to the server, ultimately compromising the utility of private graph learning. The effectiveness of the attack is demonstrated both theoretically and empirically. In addition, several defense strategies have also been explored, but their limited effectiveness highlights the need for more robust defenses.
Alignment-Enhanced Decoding:Defending via Token-Level Adaptive Refining of Probability Distributions
Aug 14, 2024



Large language models are susceptible to jailbreak attacks, which can result in the generation of harmful content. While prior defenses mitigate these risks by perturbing or inspecting inputs, they ignore competing objectives, the underlying cause of alignment failures. In this paper, we propose Alignment-Enhanced Decoding (AED), a novel defense that employs adaptive decoding to address the root causes of jailbreak issues. We first define the Competitive Index to quantify alignment failures and utilize feedback from self-evaluation to compute post-alignment logits. Then, AED adaptively combines AED and post-alignment logits with the original logits to obtain harmless and helpful distributions. Consequently, our method enhances safety alignment while maintaining helpfulness. We conduct experiments across five models and four common jailbreaks, with the results validating the effectiveness of our approach. Code is available at https://github.com/GIGABaozi/AED.git.