 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpen-Vocabulary Semantic Segmentation Network Integrating Object-Level Label and Scene-Level Semantic Features for Multimodal Remote Sensing Images
Apr 27, 2026Semantic segmentation of multi-modal remote sensing imagery plays a pivotal role in land use/land cover (LULC) mapping, environmental monitoring, and precision earth observation. Current multi-modal approaches mainly focus on integrating complementary visual modalities, yet neglect the incorporating of non-visual textual data - a rich source of knowledge that can bridge semantic gaps between visual patterns and real-world concepts. To address this limitation, we propose TSMNet, a text supervised multi-modal open vocabulary semantic segmentation network that synergistically integrates textual supervision with visual representation for open-vocabulary semantic segmentation. Unlike conventional multi-modal segmentation frameworks, TSMNet introduces a dual-branch text encoder to extract both scene-level semantic and object-level label information from various textual data, enabling dynamic cross-modal fusion. These text-derived features dynamically interact with visual embeddings through the proposed text-guided visual semantic fusion module, enabling domain-aware feature refinement and human-interpretable decision-making. To verify our method, we innovatively construct two new multi-modal datasets, and carry out extensive experiments to make a comprehensive comparison between the proposed method and other state-of-the-art (SOTA) semantic segmentation models. Results demonstrate that TSMNet achieves superior segmentation accuracy while exhibiting robust generalization capabilities across diverse geographical and sensor-specific scenarios. This work establishes a new paradigm for explainable remote sensing analysis, demonstrating that textual knowledge integration significantly enhances model generalizability. The source code will be available at https://github.com/yeyuanxin110/TSMNet
CLEAR: Context-Aware Learning with End-to-End Mask-Free Inference for Adaptive Video Subtitle Removal
Mar 23, 2026Video subtitle removal aims to distinguish text overlays from background content while preserving temporal coherence. Existing diffusion-based methods necessitate explicit mask sequences during both training and inference phases, which restricts their practical deployment. In this paper, we present CLEAR (Context-aware Learning for End-to-end Adaptive Video Subtitle Removal), a mask-free framework that achieves truly end-to-end inference through context-aware adaptive learning. Our two-stage design decouples prior extraction from generative refinement: Stage I learns disentangled subtitle representations via self-supervised orthogonality constraints on dual encoders, while Stage II employs LoRA-based adaptation with generation feedback for dynamic context adjustment. Notably, our method only requires 0.77% of the parameters of the base diffusion model for training. On Chinese subtitle benchmarks, CLEAR outperforms mask-dependent baselines by + 6.77dB PSNR and -74.7% VFID, while demonstrating superior zero-shot generalization across six languages (English, Korean, French, Japanese, Russian, German), a performance enabled by our generation-driven feedback mechanism that ensures robust subtitle removal without ground-truth masks during inference.
Learning to Explore: Policy-Guided Outlier Synthesis for Graph Out-of-Distribution Detection
Feb 28, 2026Detecting out-of-distribution (OOD) graphs is crucial for ensuring the safety and reliability of Graph Neural Networks. In unsupervised graph-level OOD detection, models are typically trained using only in-distribution (ID) data, resulting in incomplete feature space characterization and weak decision boundaries. Although synthesizing outliers offers a promising solution, existing approaches rely on fixed, non-adaptive sampling heuristics (e.g., distance- or density-based), limiting their ability to explore informative OOD regions. We propose a Policy-Guided Outlier Synthesis (PGOS) framework that replaces static heuristics with a learned exploration strategy. Specifically, PGOS trains a reinforcement learning agent to navigate low-density regions in a structured latent space and sample representations that most effectively refine the OOD decision boundary. These representations are then decoded into high-quality pseudo-OOD graphs to improve detector robustness. Extensive experiments demonstrate that PGOS achieves state-of-the-art performance on multiple graph OOD and anomaly detection benchmarks.
FFP-300K: Scaling First-Frame Propagation for Generalizable Video Editing
Jan 06, 2026First-Frame Propagation (FFP) offers a promising paradigm for controllable video editing, but existing methods are hampered by a reliance on cumbersome run-time guidance. We identify the root cause of this limitation as the inadequacy of current training datasets, which are often too short, low-resolution, and lack the task diversity required to teach robust temporal priors. To address this foundational data gap, we first introduce FFP-300K, a new large-scale dataset comprising 300K high-fidelity video pairs at 720p resolution and 81 frames in length, constructed via a principled two-track pipeline for diverse local and global edits. Building on this dataset, we propose a novel framework designed for true guidance-free FFP that resolves the critical tension between maintaining first-frame appearance and preserving source video motion. Architecturally, we introduce Adaptive Spatio-Temporal RoPE (AST-RoPE), which dynamically remaps positional encodings to disentangle appearance and motion references. At the objective level, we employ a self-distillation strategy where an identity propagation task acts as a powerful regularizer, ensuring long-term temporal stability and preventing semantic drift. Comprehensive experiments on the EditVerseBench benchmark demonstrate that our method significantly outperforming existing academic and commercial models by receiving about 0.2 PickScore and 0.3 VLM score improvement against these competitors.
The devil is in the details: Enhancing Video Virtual Try-On via Keyframe-Driven Details Injection
Dec 23, 2025Although diffusion transformer (DiT)-based video virtual try-on (VVT) has made significant progress in synthesizing realistic videos, existing methods still struggle to capture fine-grained garment dynamics and preserve background integrity across video frames. They also incur high computational costs due to additional interaction modules introduced into DiTs, while the limited scale and quality of existing public datasets also restrict model generalization and effective training. To address these challenges, we propose a novel framework, KeyTailor, along with a large-scale, high-definition dataset, ViT-HD. The core idea of KeyTailor is a keyframe-driven details injection strategy, motivated by the fact that keyframes inherently contain both foreground dynamics and background consistency. Specifically, KeyTailor adopts an instruction-guided keyframe sampling strategy to filter informative frames from the input video. Subsequently,two tailored keyframe-driven modules, the garment details enhancement module and the collaborative background optimization module, are employed to distill garment dynamics into garment-related latents and to optimize the integrity of background latents, both guided by keyframes.These enriched details are then injected into standard DiT blocks together with pose, mask, and noise latents, enabling efficient and realistic try-on video synthesis. This design ensures consistency without explicitly modifying the DiT architecture, while simultaneously avoiding additional complexity. In addition, our dataset ViT-HD comprises 15, 070 high-quality video samples at a resolution of 810*1080, covering diverse garments. Extensive experiments demonstrate that KeyTailor outperforms state-of-the-art baselines in terms of garment fidelity and background integrity across both dynamic and static scenarios.
MoE-SpeQ: Speculative Quantized Decoding with Proactive Expert Prefetching and Offloading for Mixture-of-Experts
Nov 18, 2025The immense memory requirements of state-of-the-art Mixture-of-Experts (MoE) models present a significant challenge for inference, often exceeding the capacity of a single accelerator. While offloading experts to host memory is a common solution, it introduces a severe I/O bottleneck over the PCIe bus, as the data-dependent nature of expert selection places these synchronous transfers directly on the critical path of execution, crippling performance. This paper argues that the I/O bottleneck can be overcome by trading a small amount of cheap, on-device computation to hide the immense cost of data movement. We present MoE-SpeQ, a new inference system built on a novel co-design of speculative execution and expert offloading. MoE-SpeQ employs a small, on-device draft model to predict the sequence of required experts for future tokens. This foresight enables a runtime orchestrator to prefetch these experts from host memory, effectively overlapping the expensive I/O with useful computation and hiding the latency from the critical path. To maximize performance, an adaptive governor, guided by an Amortization Roofline Model, dynamically tunes the speculation strategy to the underlying hardware. Our evaluation on memory-constrained devices shows that for the Phi-MoE model, MoE-SpeQ achieves at most 2.34x speedup over the state-of-the-art offloading framework. Our work establishes a new, principled approach for managing data-dependent memory access in resource-limited environments, making MoE inference more accessible on commodity hardware.
FedTopo: Topology-Informed Representation Alignment in Federated Learning under Non-I.I.D. Conditions
Nov 16, 2025Current federated-learning models deteriorate under heterogeneous (non-I.I.D.) client data, as their feature representations diverge and pixel- or patch-level objectives fail to capture the global topology which is essential for high-dimensional visual tasks. We propose FedTopo, a framework that integrates Topological-Guided Block Screening (TGBS) and Topological Embedding (TE) to leverage topological information, yielding coherently aligned cross-client representations by Topological Alignment Loss (TAL). First, Topology-Guided Block Screening (TGBS) automatically selects the most topology-informative block, i.e., the one with maximal topological separability, whose persistence-based signatures best distinguish within- versus between-class pairs, ensuring that subsequent analysis focuses on topology-rich features. Next, this block yields a compact Topological Embedding, which quantifies the topological information for each client. Finally, a Topological Alignment Loss (TAL) guides clients to maintain topological consistency with the global model during optimization, reducing representation drift across rounds. Experiments on Fashion-MNIST, CIFAR-10, and CIFAR-100 under four non-I.I.D. partitions show that FedTopo accelerates convergence and improves accuracy over strong baselines.
FedDEAP: Adaptive Dual-Prompt Tuning for Multi-Domain Federated Learning
Oct 21, 2025Federated learning (FL) enables multiple clients to collaboratively train machine learning models without exposing local data, balancing performance and privacy. However, domain shift and label heterogeneity across clients often hinder the generalization of the aggregated global model. Recently, large-scale vision-language models like CLIP have shown strong zero-shot classification capabilities, raising the question of how to effectively fine-tune CLIP across domains in a federated setting. In this work, we propose an adaptive federated prompt tuning framework, FedDEAP, to enhance CLIP's generalization in multi-domain scenarios. Our method includes the following three key components: (1) To mitigate the loss of domain-specific information caused by label-supervised tuning, we disentangle semantic and domain-specific features in images by using semantic and domain transformation networks with unbiased mappings; (2) To preserve domain-specific knowledge during global prompt aggregation, we introduce a dual-prompt design with a global semantic prompt and a local domain prompt to balance shared and personalized information; (3) To maximize the inclusion of semantic and domain information from images in the generated text features, we align textual and visual representations under the two learned transformations to preserve semantic and domain consistency. Theoretical analysis and extensive experiments on four datasets demonstrate the effectiveness of our method in enhancing the generalization of CLIP for federated image recognition across multiple domains.
Neural Canonical Polyadic Factorization for Traffic Analysis
Jun 18, 2025Modern intelligent transportation systems rely on accurate spatiotemporal traffic analysis to optimize urban mobility and infrastructure resilience. However, pervasive missing data caused by sensor failures and heterogeneous sensing gaps fundamentally hinders reliable traffic modeling. This paper proposes a Neural Canonical Polyadic Factorization (NCPF) model that synergizes low-rank tensor algebra with deep representation learning for robust traffic data imputation. The model innovatively embeds CP decomposition into neural architecture through learnable embedding projections, where sparse traffic tensors are encoded into dense latent factors across road segments, time intervals, and mobility metrics. A hierarchical feature fusion mechanism employs Hadamard products to explicitly model multilinear interactions, while stacked multilayer perceptron layers nonlinearly refine these representations to capture complex spatiotemporal couplings. Extensive evaluations on six urban traffic datasets demonstrate NCPF's superiority over six state-of-the-art baselines. By unifying CP decomposition's interpretable factor analysis with neural network's nonlinear expressive power, NCPF provides a principled yet flexible approaches for high-dimensional traffic data imputation, offering critical support for next-generation transportation digital twins and adaptive traffic control systems.
Devil's Hand: Data Poisoning Attacks to Locally Private Graph Learning Protocols
Jun 11, 2025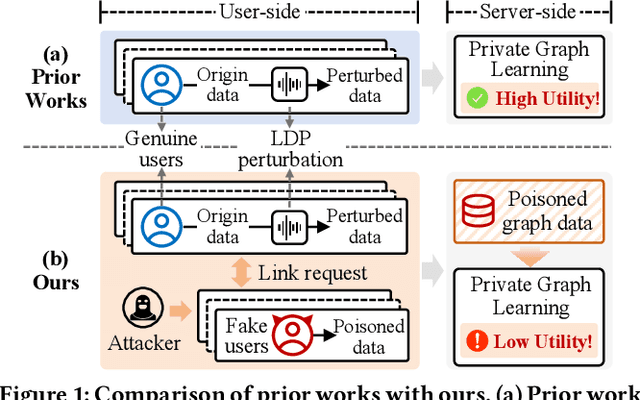
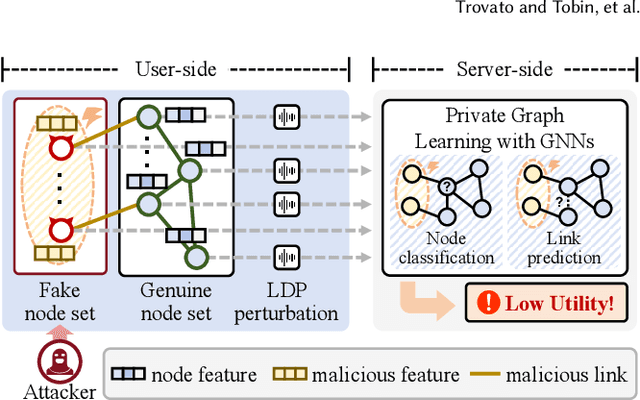
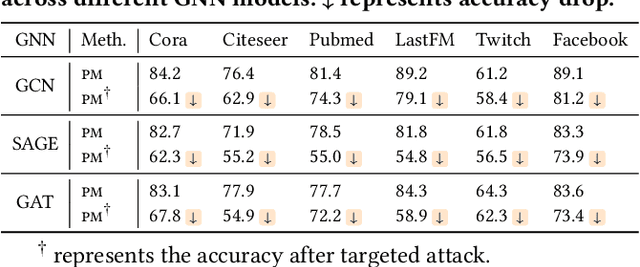
Graph neural networks (GNNs) have achieved significant success in graph representation learning and have been applied to various domains. However, many real-world graphs contain sensitive personal information, such as user profiles in social networks, raising serious privacy concerns when graph learning is performed using GNNs. To address this issue, locally private graph learning protocols have gained considerable attention. These protocols leverage the privacy advantages of local differential privacy (LDP) and the effectiveness of GNN's message-passing in calibrating noisy data, offering strict privacy guarantees for users' local data while maintaining high utility (e.g., node classification accuracy) for graph learning. Despite these advantages, such protocols may be vulnerable to data poisoning attacks, a threat that has not been considered in previous research. Identifying and addressing these threats is crucial for ensuring the robustness and security of privacy-preserving graph learning frameworks. This work introduces the first data poisoning attack targeting locally private graph learning protocols. The attacker injects fake users into the protocol, manipulates these fake users to establish links with genuine users, and sends carefully crafted data to the server, ultimately compromising the utility of private graph learning. The effectiveness of the attack is demonstrated both theoretically and empirically. In addition, several defense strategies have also been explored, but their limited effectiveness highlights the need for more robust defenses.