 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDocKD: Knowledge Distillation from LLMs for Open-World Document Understanding Models
Oct 04, 2024



Visual document understanding (VDU) is a challenging task that involves understanding documents across various modalities (text and image) and layouts (forms, tables, etc.). This study aims to enhance generalizability of small VDU models by distilling knowledge from LLMs. We identify that directly prompting LLMs often fails to generate informative and useful data. In response, we present a new framework (called DocKD) that enriches the data generation process by integrating external document knowledge. Specifically, we provide an LLM with various document elements like key-value pairs, layouts, and descriptions, to elicit open-ended answers. Our experiments show that DocKD produces high-quality document annotations and surpasses the direct knowledge distillation approach that does not leverage external document knowledge. Moreover, student VDU models trained with solely DocKD-generated data are not only comparable to those trained with human-annotated data on in-domain tasks but also significantly excel them on out-of-domain tasks.
DocTr: Document Transformer for Structured Information Extraction in Documents
Jul 16, 2023We present a new formulation for structured information extraction (SIE) from visually rich documents. It aims to address the limitations of existing IOB tagging or graph-based formulations, which are either overly reliant on the correct ordering of input text or struggle with decoding a complex graph. Instead, motivated by anchor-based object detectors in vision, we represent an entity as an anchor word and a bounding box, and represent entity linking as the association between anchor words. This is more robust to text ordering, and maintains a compact graph for entity linking. The formulation motivates us to introduce 1) a DOCument TRansformer (DocTr) that aims at detecting and associating entity bounding boxes in visually rich documents, and 2) a simple pre-training strategy that helps learn entity detection in the context of language. Evaluations on three SIE benchmarks show the effectiveness of the proposed formulation, and the overall approach outperforms existing solutions.
REGAS: REspiratory-GAted Synthesis of Views for Multi-Phase CBCT Reconstruction from a single 3D CBCT Acquisition
Aug 17, 2022



It is a long-standing challenge to reconstruct Cone Beam Computed Tomography (CBCT) of the lung under respiratory motion. This work takes a step further to address a challenging setting in reconstructing a multi-phase}4D lung image from just a single}3D CBCT acquisition. To this end, we introduce REpiratory-GAted Synthesis of views, or REGAS. REGAS proposes a self-supervised method to synthesize the undersampled tomographic views and mitigate aliasing artifacts in reconstructed images. This method allows a much better estimation of between-phase Deformation Vector Fields (DVFs), which are used to enhance reconstruction quality from direct observations without synthesis. To address the large memory cost of deep neural networks on high resolution 4D data, REGAS introduces a novel Ray Path Transformation (RPT) that allows for distributed, differentiable forward projections. REGAS require no additional measurements like prior scans, air-flow volume, or breathing velocity. Our extensive experiments show that REGAS significantly outperforms comparable methods in quantitative metrics and visual quality.
Breast Cancer Induced Bone Osteolysis Prediction Using Temporal Variational Auto-Encoders
Mar 28, 2022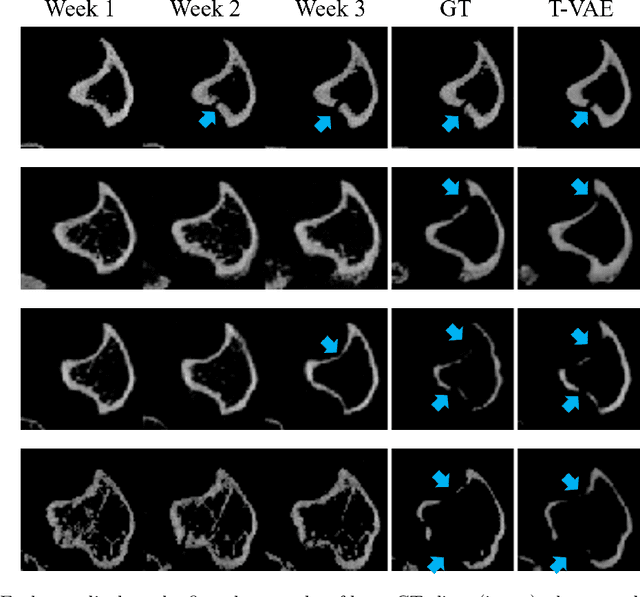
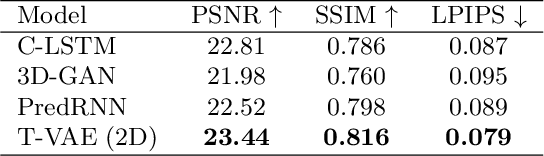
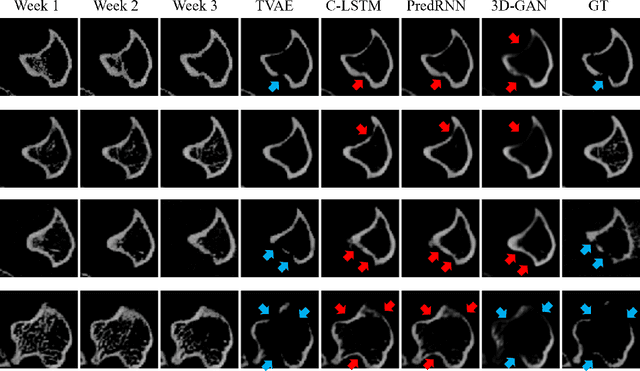

Objective and Impact Statement. We adopt a deep learning model for bone osteolysis prediction on computed tomography (CT) images of murine breast cancer bone metastases. Given the bone CT scans at previous time steps, the model incorporates the bone-cancer interactions learned from the sequential images and generates future CT images. Its ability of predicting the development of bone lesions in cancer-invading bones can assist in assessing the risk of impending fractures and choosing proper treatments in breast cancer bone metastasis. Introduction. Breast cancer often metastasizes to bone, causes osteolytic lesions, and results in skeletal related events (SREs) including severe pain and even fatal fractures. Although current imaging techniques can detect macroscopic bone lesions, predicting the occurrence and progression of bone lesions remains a challenge. Methods. We adopt a temporal variational auto-encoder (T-VAE) model that utilizes a combination of variational auto-encoders and long short-term memory networks to predict bone lesion emergence on our micro-CT dataset containing sequential images of murine tibiae. Given the CT scans of murine tibiae at early weeks, our model can learn the distribution of their future states from data. Results. We test our model against other deep learning-based prediction models on the bone lesion progression prediction task. Our model produces much more accurate predictions than existing models under various evaluation metrics. Conclusion. We develop a deep learning framework that can accurately predict and visualize the progression of osteolytic bone lesions. It will assist in planning and evaluating treatment strategies to prevent SREs in breast cancer patients.
Learning Bias-Invariant Representation by Cross-Sample Mutual Information Minimization
Aug 13, 2021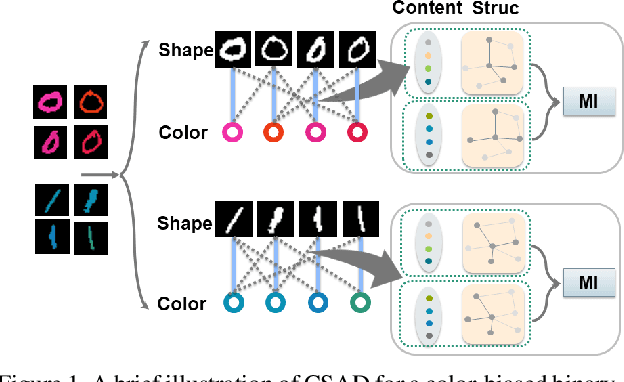
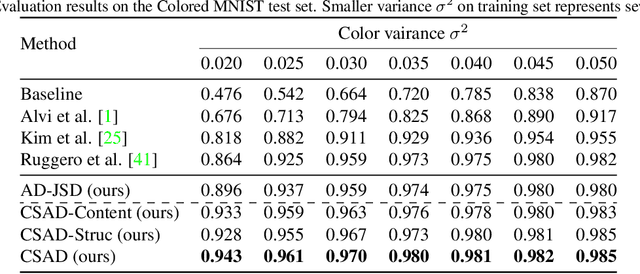
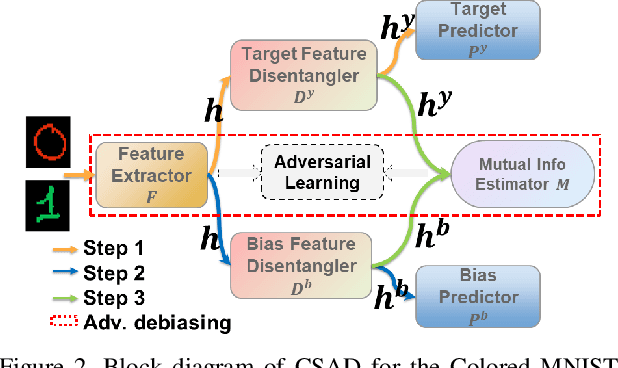
Deep learning algorithms mine knowledge from the training data and thus would likely inherit the dataset's bias information. As a result, the obtained model would generalize poorly and even mislead the decision process in real-life applications. We propose to remove the bias information misused by the target task with a cross-sample adversarial debiasing (CSAD) method. CSAD explicitly extracts target and bias features disentangled from the latent representation generated by a feature extractor and then learns to discover and remove the correlation between the target and bias features. The correlation measurement plays a critical role in adversarial debiasing and is conducted by a cross-sample neural mutual information estimator. Moreover, we propose joint content and local structural representation learning to boost mutual information estimation for better performance. We conduct thorough experiments on publicly available datasets to validate the advantages of the proposed method over state-of-the-art approaches.
Visual Composite Set Detection Using Part-and-Sum Transformers
May 05, 2021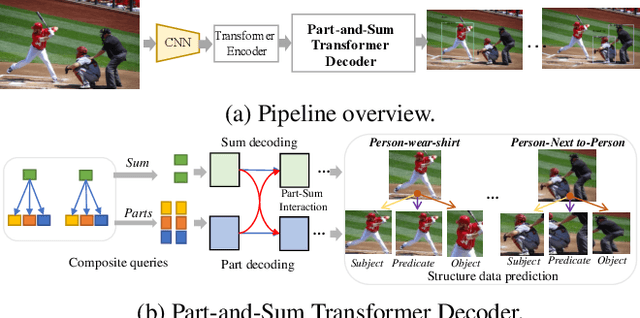

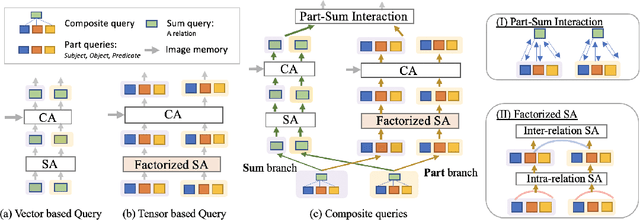

Computer vision applications such as visual relationship detection and human-object interaction can be formulated as a composite (structured) set detection problem in which both the parts (subject, object, and predicate) and the sum (triplet as a whole) are to be detected in a hierarchical fashion. In this paper, we present a new approach, denoted Part-and-Sum detection Transformer (PST), to perform end-to-end composite set detection. Different from existing Transformers in which queries are at a single level, we simultaneously model the joint part and sum hypotheses/interactions with composite queries and attention modules. We explicitly incorporate sum queries to enable better modeling of the part-and-sum relations that are absent in the standard Transformers. Our approach also uses novel tensor-based part queries and vector-based sum queries, and models their joint interaction. We report experiments on two vision tasks, visual relationship detection, and human-object interaction, and demonstrate that PST achieves state-of-the-art results among single-stage models, while nearly matching the results of custom-designed two-stage models.
XraySyn: Realistic View Synthesis From a Single Radiograph Through CT Priors
Dec 04, 2020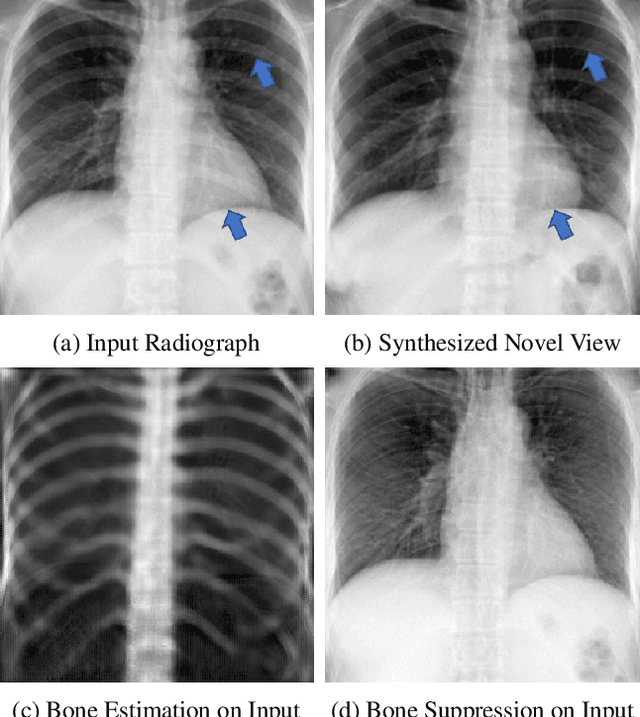



A radiograph visualizes the internal anatomy of a patient through the use of X-ray, which projects 3D information onto a 2D plane. Hence, radiograph analysis naturally requires physicians to relate the prior about 3D human anatomy to 2D radiographs. Synthesizing novel radiographic views in a small range can assist physicians in interpreting anatomy more reliably; however, radiograph view synthesis is heavily ill-posed, lacking in paired data, and lacking in differentiable operations to leverage learning-based approaches. To address these problems, we use Computed Tomography (CT) for radiograph simulation and design a differentiable projection algorithm, which enables us to achieve geometrically consistent transformations between the radiography and CT domains. Our method, XraySyn, can synthesize novel views on real radiographs through a combination of realistic simulation and finetuning on real radiographs. To the best of our knowledge, this is the first work on radiograph view synthesis. We show that by gaining an understanding of radiography in 3D space, our method can be applied to radiograph bone extraction and suppression without groundtruth bone labels.
A Smartphone-based System for Real-time Early Childhood Caries Diagnosis
Aug 17, 2020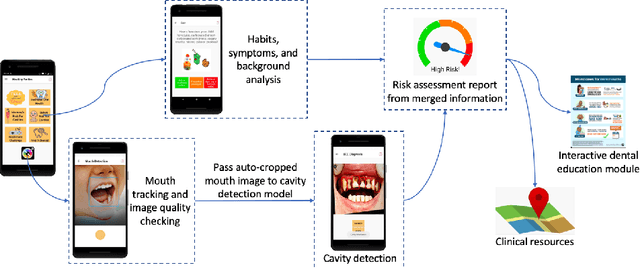


Early childhood caries (ECC) is the most common, yet preventable chronic disease in children under the age of 6. Treatments on severe ECC are extremely expensive and unaffordable for socioeconomically disadvantaged families. The identification of ECC in an early stage usually requires expertise in the field, and hence is often ignored by parents. Therefore, early prevention strategies and easy-to-adopt diagnosis techniques are desired. In this study, we propose a multistage deep learning-based system for cavity detection. We create a dataset containing RGB oral images labeled manually by dental practitioners. We then investigate the effectiveness of different deep learning models on the dataset. Furthermore, we integrate the deep learning system into an easy-to-use mobile application that can diagnose ECC from an early stage and provide real-time results to untrained users.
Structured Landmark Detection via Topology-Adapting Deep Graph Learning
Apr 23, 2020
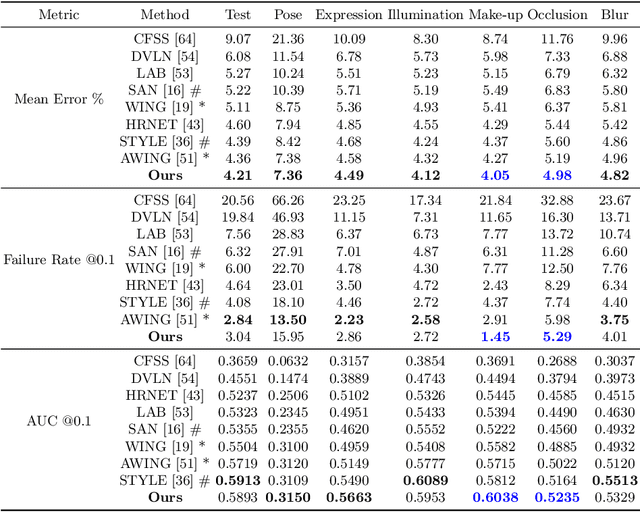


Image landmark detection aims to automatically identify the locations of predefined fiducial points. Despite recent success in this filed, higher-ordered structural modeling to capture implicit or explicit relationships among anatomical landmarks has not been adequately exploited. In this work, we present a new topology-adapting deep graph learning approach for accurate anatomical facial and medical (e.g., hand, pelvis) landmark detection. The proposed method constructs graph signals leveraging both local image features and global shape features. The adaptive graph topology naturally explores and lands on task-specific structures which is learned end-to-end with two Graph Convolutional Networks (GCNs). Extensive experiments are conducted on three public facial image datasets (WFLW, 300W and COFW-68) as well as three real-world X-ray medical datasets (Cephalometric (public), Hand and Pelvis). Quantitative results comparing with the previous state-of-the-art approaches across all studied datasets indicating the superior performance in both robustness and accuracy. Qualitative visualizations of the learned graph topologies demonstrate a physically plausible connectivity laying behind the landmarks.
Alleviating the Incompatibility between Cross Entropy Loss and Episode Training for Few-shot Skin Disease Classification
Apr 21, 2020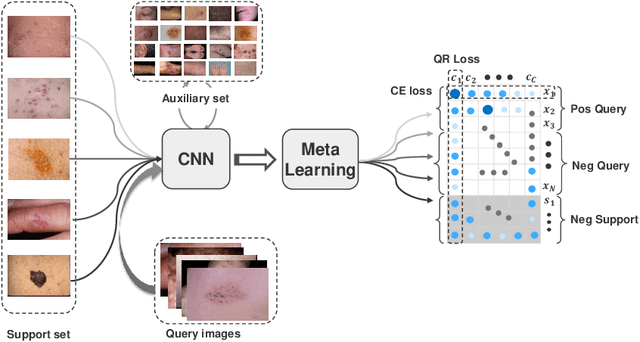


Skin disease classification from images is crucial to dermatological diagnosis. However, identifying skin lesions involves a variety of aspects in terms of size, color, shape, and texture. To make matters worse, many categories only contain very few samples, posing great challenges to conventional machine learning algorithms and even human experts. Inspired by the recent success of Few-Shot Learning (FSL) in natural image classification, we propose to apply FSL to skin disease identification to address the extreme scarcity of training sample problem. However, directly applying FSL to this task does not work well in practice, and we find that the problem can be largely attributed to the incompatibility between Cross Entropy (CE) and episode training, which are both commonly used in FSL. Based on a detailed analysis, we propose the Query-Relative (QR) loss, which proves superior to CE under episode training and is closely related to recently proposed mutual information estimation. Moreover, we further strengthen the proposed QR loss with a novel adaptive hard margin strategy. Comprehensive experiments validate the effectiveness of the proposed FSL scheme and the possibility to diagnosis rare skin disease with a few labeled samples.