 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScalable Frameworks for Real-World Audio-Visual Speech Recognition
Dec 16, 2025



The practical deployment of Audio-Visual Speech Recognition (AVSR) systems is fundamentally challenged by significant performance degradation in real-world environments, characterized by unpredictable acoustic noise and visual interference. This dissertation posits that a systematic, hierarchical approach is essential to overcome these challenges, achieving the robust scalability at the representation, architecture, and system levels. At the representation level, we investigate methods for building a unified model that learns audio-visual features inherently robust to diverse real-world corruptions, thereby enabling generalization to new environments without specialized modules. To address architectural scalability, we explore how to efficiently expand model capacity while ensuring the adaptive and reliable use of multimodal inputs, developing a framework that intelligently allocates computational resources based on the input characteristics. Finally, at the system level, we present methods to expand the system's functionality through modular integration with large-scale foundation models, leveraging their powerful cognitive and generative capabilities to maximize final recognition accuracy. By systematically providing solutions at each of these three levels, this dissertation aims to build a next-generation, robust, and scalable AVSR system with high reliability in real-world applications.
Flex-Judge: Think Once, Judge Anywhere
May 24, 2025Human-generated reward signals are critical for aligning generative models with human preferences, guiding both training and inference-time evaluations. While large language models (LLMs) employed as proxy evaluators, i.e., LLM-as-a-Judge, significantly reduce the costs associated with manual annotations, they typically require extensive modality-specific training data and fail to generalize well across diverse multimodal tasks. In this paper, we propose Flex-Judge, a reasoning-guided multimodal judge model that leverages minimal textual reasoning data to robustly generalize across multiple modalities and evaluation formats. Our core intuition is that structured textual reasoning explanations inherently encode generalizable decision-making patterns, enabling an effective transfer to multimodal judgments, e.g., with images or videos. Empirical results demonstrate that Flex-Judge, despite being trained on significantly fewer text data, achieves competitive or superior performance compared to state-of-the-art commercial APIs and extensively trained multimodal evaluators. Notably, Flex-Judge presents broad impact in modalities like molecule, where comprehensive evaluation benchmarks are scarce, underscoring its practical value in resource-constrained domains. Our framework highlights reasoning-based text supervision as a powerful, cost-effective alternative to traditional annotation-intensive approaches, substantially advancing scalable multimodal model-as-a-judge.
MAVFlow: Preserving Paralinguistic Elements with Conditional Flow Matching for Zero-Shot AV2AV Multilingual Translation
Mar 14, 2025



Despite recent advances in text-to-speech (TTS) models, audio-visual to audio-visual (AV2AV) translation still faces a critical challenge: maintaining speaker consistency between the original and translated vocal and facial features. To address this issue, we propose a conditional flow matching (CFM) zero-shot audio-visual renderer that utilizes strong dual guidance from both audio and visual modalities. By leveraging multi-modal guidance with CFM, our model robustly preserves speaker-specific characteristics and significantly enhances zero-shot AV2AV translation abilities. For the audio modality, we enhance the CFM process by integrating robust speaker embeddings with x-vectors, which serve to bolster speaker consistency. Additionally, we convey emotional nuances to the face rendering module. The guidance provided by both audio and visual cues remains independent of semantic or linguistic content, allowing our renderer to effectively handle zero-shot translation tasks for monolingual speakers in different languages. We empirically demonstrate that the inclusion of high-quality mel-spectrograms conditioned on facial information not only enhances the quality of the synthesized speech but also positively influences facial generation, leading to overall performance improvements.
DistiLLM-2: A Contrastive Approach Boosts the Distillation of LLMs
Mar 10, 2025



Despite the success of distillation in large language models (LLMs), most prior work applies identical loss functions to both teacher- and student-generated data. These strategies overlook the synergy between loss formulations and data types, leading to a suboptimal performance boost in student models. To address this, we propose DistiLLM-2, a contrastive approach that simultaneously increases the likelihood of teacher responses and decreases that of student responses by harnessing this synergy. Our extensive experiments show that DistiLLM-2 not only builds high-performing student models across a wide range of tasks, including instruction-following and code generation, but also supports diverse applications, such as preference alignment and vision-language extensions. These findings highlight the potential of a contrastive approach to enhance the efficacy of LLM distillation by effectively aligning teacher and student models across varied data types.
DocKD: Knowledge Distillation from LLMs for Open-World Document Understanding Models
Oct 04, 2024



Visual document understanding (VDU) is a challenging task that involves understanding documents across various modalities (text and image) and layouts (forms, tables, etc.). This study aims to enhance generalizability of small VDU models by distilling knowledge from LLMs. We identify that directly prompting LLMs often fails to generate informative and useful data. In response, we present a new framework (called DocKD) that enriches the data generation process by integrating external document knowledge. Specifically, we provide an LLM with various document elements like key-value pairs, layouts, and descriptions, to elicit open-ended answers. Our experiments show that DocKD produces high-quality document annotations and surpasses the direct knowledge distillation approach that does not leverage external document knowledge. Moreover, student VDU models trained with solely DocKD-generated data are not only comparable to those trained with human-annotated data on in-domain tasks but also significantly excel them on out-of-domain tasks.
Diffusion-based Episodes Augmentation for Offline Multi-Agent Reinforcement Learning
Aug 23, 2024Offline multi-agent reinforcement learning (MARL) is increasingly recognized as crucial for effectively deploying RL algorithms in environments where real-time interaction is impractical, risky, or costly. In the offline setting, learning from a static dataset of past interactions allows for the development of robust and safe policies without the need for live data collection, which can be fraught with challenges. Building on this foundational importance, we present EAQ, Episodes Augmentation guided by Q-total loss, a novel approach for offline MARL framework utilizing diffusion models. EAQ integrates the Q-total function directly into the diffusion model as a guidance to maximize the global returns in an episode, eliminating the need for separate training. Our focus primarily lies on cooperative scenarios, where agents are required to act collectively towards achieving a shared goal-essentially, maximizing global returns. Consequently, we demonstrate that our episodes augmentation in a collaborative manner significantly boosts offline MARL algorithm compared to the original dataset, improving the normalized return by +17.3% and +12.9% for medium and poor behavioral policies in SMAC simulator, respectively.
Learning Video Temporal Dynamics with Cross-Modal Attention for Robust Audio-Visual Speech Recognition
Jul 04, 2024



Audio-visual speech recognition (AVSR) aims to transcribe human speech using both audio and video modalities. In practical environments with noise-corrupted audio, the role of video information becomes crucial. However, prior works have primarily focused on enhancing audio features in AVSR, overlooking the importance of video features. In this study, we strengthen the video features by learning three temporal dynamics in video data: context order, playback direction, and the speed of video frames. Cross-modal attention modules are introduced to enrich video features with audio information so that speech variability can be taken into account when training on the video temporal dynamics. Based on our approach, we achieve the state-of-the-art performance on the LRS2 and LRS3 AVSR benchmarks for the noise-dominant settings. Our approach excels in scenarios especially for babble and speech noise, indicating the ability to distinguish the speech signal that should be recognized from lip movements in the video modality. We support the validity of our methodology by offering the ablation experiments for the temporal dynamics losses and the cross-modal attention architecture design.
FedDr+: Stabilizing Dot-regression with Global Feature Distillation for Federated Learning
Jun 04, 2024Federated Learning (FL) has emerged as a pivotal framework for the development of effective global models (global FL) or personalized models (personalized FL) across clients with heterogeneous, non-iid data distribution. A key challenge in FL is client drift, where data heterogeneity impedes the aggregation of scattered knowledge. Recent studies have tackled the client drift issue by identifying significant divergence in the last classifier layer. To mitigate this divergence, strategies such as freezing the classifier weights and aligning the feature extractor accordingly have proven effective. Although the local alignment between classifier and feature extractor has been studied as a crucial factor in FL, we observe that it may lead the model to overemphasize the observed classes within each client. Thus, our objectives are twofold: (1) enhancing local alignment while (2) preserving the representation of unseen class samples. This approach aims to effectively integrate knowledge from individual clients, thereby improving performance for both global and personalized FL. To achieve this, we introduce a novel algorithm named FedDr+, which empowers local model alignment using dot-regression loss. FedDr+ freezes the classifier as a simplex ETF to align the features and improves aggregated global models by employing a feature distillation mechanism to retain information about unseen/missing classes. Consequently, we provide empirical evidence demonstrating that our algorithm surpasses existing methods that use a frozen classifier to boost alignment across the diverse distribution.
DistiLLM: Towards Streamlined Distillation for Large Language Models
Feb 06, 2024



Knowledge distillation (KD) is widely used for compressing a teacher model to a smaller student model, reducing its inference cost and memory footprint while preserving model capabilities. However, current KD methods for auto-regressive sequence models (e.g., large language models) suffer from missing a standardized objective function. Moreover, the recent use of student-generated outputs to address training-inference mismatches has significantly escalated computational costs. To tackle these issues, we introduce DistiLLM, a more effective and efficient KD framework for auto-regressive language models. DistiLLM comprises two components: (1) a novel skew Kullback-Leibler divergence loss, where we unveil and leverage its theoretical properties, and (2) an adaptive off-policy approach designed to enhance the efficiency in utilizing student-generated outputs. Extensive experiments, including instruction-following tasks, demonstrate the effectiveness of DistiLLM in building high-performing student models while achieving up to 4.3$\times$ speedup compared to recent KD methods.
STaR: Distilling Speech Temporal Relation for Lightweight Speech Self-Supervised Learning Models
Dec 14, 2023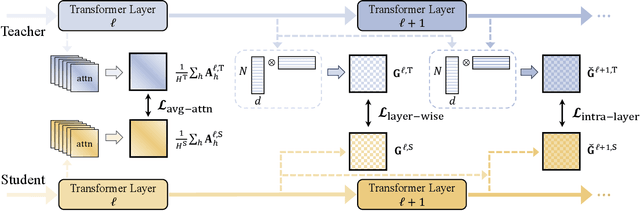



Albeit great performance of Transformer-based speech selfsupervised learning (SSL) models, their large parameter size and computational cost make them unfavorable to utilize. In this study, we propose to compress the speech SSL models by distilling speech temporal relation (STaR). Unlike previous works that directly match the representation for each speech frame, STaR distillation transfers temporal relation between speech frames, which is more suitable for lightweight student with limited capacity. We explore three STaR distillation objectives and select the best combination as the final STaR loss. Our model distilled from HuBERT BASE achieves an overall score of 79.8 on SUPERB benchmark, the best performance among models with up to 27 million parameters. We show that our method is applicable across different speech SSL models and maintains robust performance with further reduced parameters.