 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProCrop: Learning Aesthetic Image Cropping from Professional Compositions
May 28, 2025Image cropping is crucial for enhancing the visual appeal and narrative impact of photographs, yet existing rule-based and data-driven approaches often lack diversity or require annotated training data. We introduce ProCrop, a retrieval-based method that leverages professional photography to guide cropping decisions. By fusing features from professional photographs with those of the query image, ProCrop learns from professional compositions, significantly boosting performance. Additionally, we present a large-scale dataset of 242K weakly-annotated images, generated by out-painting professional images and iteratively refining diverse crop proposals. This composition-aware dataset generation offers diverse high-quality crop proposals guided by aesthetic principles and becomes the largest publicly available dataset for image cropping. Extensive experiments show that ProCrop significantly outperforms existing methods in both supervised and weakly-supervised settings. Notably, when trained on the new dataset, our ProCrop surpasses previous weakly-supervised methods and even matches fully supervised approaches. Both the code and dataset will be made publicly available to advance research in image aesthetics and composition analysis.
DistiLLM-2: A Contrastive Approach Boosts the Distillation of LLMs
Mar 10, 2025



Despite the success of distillation in large language models (LLMs), most prior work applies identical loss functions to both teacher- and student-generated data. These strategies overlook the synergy between loss formulations and data types, leading to a suboptimal performance boost in student models. To address this, we propose DistiLLM-2, a contrastive approach that simultaneously increases the likelihood of teacher responses and decreases that of student responses by harnessing this synergy. Our extensive experiments show that DistiLLM-2 not only builds high-performing student models across a wide range of tasks, including instruction-following and code generation, but also supports diverse applications, such as preference alignment and vision-language extensions. These findings highlight the potential of a contrastive approach to enhance the efficacy of LLM distillation by effectively aligning teacher and student models across varied data types.
Automatic Joint Structured Pruning and Quantization for Efficient Neural Network Training and Compression
Feb 23, 2025Structured pruning and quantization are fundamental techniques used to reduce the size of deep neural networks (DNNs) and typically are applied independently. Applying these techniques jointly via co-optimization has the potential to produce smaller, high-quality models. However, existing joint schemes are not widely used because of (1) engineering difficulties (complicated multi-stage processes), (2) black-box optimization (extensive hyperparameter tuning to control the overall compression), and (3) insufficient architecture generalization. To address these limitations, we present the framework GETA, which automatically and efficiently performs joint structured pruning and quantization-aware training on any DNNs. GETA introduces three key innovations: (i) a quantization-aware dependency graph (QADG) that constructs a pruning search space for generic quantization-aware DNN, (ii) a partially projected stochastic gradient method that guarantees layerwise bit constraints are satisfied, and (iii) a new joint learning strategy that incorporates interpretable relationships between pruning and quantization. We present numerical experiments on both convolutional neural networks and transformer architectures that show that our approach achieves competitive (often superior) performance compared to existing joint pruning and quantization methods.
OFER: Occluded Face Expression Reconstruction
Oct 29, 2024Reconstructing 3D face models from a single image is an inherently ill-posed problem, which becomes even more challenging in the presence of occlusions. In addition to fewer available observations, occlusions introduce an extra source of ambiguity, where multiple reconstructions can be equally valid. Despite the ubiquity of the problem, very few methods address its multi-hypothesis nature. In this paper we introduce OFER, a novel approach for single image 3D face reconstruction that can generate plausible, diverse, and expressive 3D faces, even under strong occlusions. Specifically, we train two diffusion models to generate the shape and expression coefficients of a face parametric model, conditioned on the input image. This approach captures the multi-modal nature of the problem, generating a distribution of solutions as output. Although this addresses the ambiguity problem, the challenge remains to pick the best matching shape to ensure consistency across diverse expressions. To achieve this, we propose a novel ranking mechanism that sorts the outputs of the shape diffusion network based on the predicted shape accuracy scores to select the best match. We evaluate our method using standard benchmarks and introduce CO-545, a new protocol and dataset designed to assess the accuracy of expressive faces under occlusion. Our results show improved performance over occlusion-based methods, with added ability to generate multiple expressions for a given image.
Motion Graph Unleashed: A Novel Approach to Video Prediction
Oct 29, 2024We introduce motion graph, a novel approach to the video prediction problem, which predicts future video frames from limited past data. The motion graph transforms patches of video frames into interconnected graph nodes, to comprehensively describe the spatial-temporal relationships among them. This representation overcomes the limitations of existing motion representations such as image differences, optical flow, and motion matrix that either fall short in capturing complex motion patterns or suffer from excessive memory consumption. We further present a video prediction pipeline empowered by motion graph, exhibiting substantial performance improvements and cost reductions. Experiments on various datasets, including UCF Sports, KITTI and Cityscapes, highlight the strong representative ability of motion graph. Especially on UCF Sports, our method matches and outperforms the SOTA methods with a significant reduction in model size by 78% and a substantial decrease in GPU memory utilization by 47%.
FORA: Fast-Forward Caching in Diffusion Transformer Acceleration
Jul 01, 2024Diffusion transformers (DiT) have become the de facto choice for generating high-quality images and videos, largely due to their scalability, which enables the construction of larger models for enhanced performance. However, the increased size of these models leads to higher inference costs, making them less attractive for real-time applications. We present Fast-FORward CAching (FORA), a simple yet effective approach designed to accelerate DiT by exploiting the repetitive nature of the diffusion process. FORA implements a caching mechanism that stores and reuses intermediate outputs from the attention and MLP layers across denoising steps, thereby reducing computational overhead. This approach does not require model retraining and seamlessly integrates with existing transformer-based diffusion models. Experiments show that FORA can speed up diffusion transformers several times over while only minimally affecting performance metrics such as the IS Score and FID. By enabling faster processing with minimal trade-offs in quality, FORA represents a significant advancement in deploying diffusion transformers for real-time applications. Code will be made publicly available at: https://github.com/prathebaselva/FORA.
AdaContour: Adaptive Contour Descriptor with Hierarchical Representation
Apr 12, 2024Existing angle-based contour descriptors suffer from lossy representation for non-starconvex shapes. By and large, this is the result of the shape being registered with a single global inner center and a set of radii corresponding to a polar coordinate parameterization. In this paper, we propose AdaContour, an adaptive contour descriptor that uses multiple local representations to desirably characterize complex shapes. After hierarchically encoding object shapes in a training set and constructing a contour matrix of all subdivided regions, we compute a robust low-rank robust subspace and approximate each local contour by linearly combining the shared basis vectors to represent an object. Experiments show that AdaContour is able to represent shapes more accurately and robustly than other descriptors while retaining effectiveness. We validate AdaContour by integrating it into off-the-shelf detectors to enable instance segmentation which demonstrates faithful performance. The code is available at https://github.com/tding1/AdaContour.
S3Editor: A Sparse Semantic-Disentangled Self-Training Framework for Face Video Editing
Apr 11, 2024Face attribute editing plays a pivotal role in various applications. However, existing methods encounter challenges in achieving high-quality results while preserving identity, editing faithfulness, and temporal consistency. These challenges are rooted in issues related to the training pipeline, including limited supervision, architecture design, and optimization strategy. In this work, we introduce S3Editor, a Sparse Semantic-disentangled Self-training framework for face video editing. S3Editor is a generic solution that comprehensively addresses these challenges with three key contributions. Firstly, S3Editor adopts a self-training paradigm to enhance the training process through semi-supervision. Secondly, we propose a semantic disentangled architecture with a dynamic routing mechanism that accommodates diverse editing requirements. Thirdly, we present a structured sparse optimization schema that identifies and deactivates malicious neurons to further disentangle impacts from untarget attributes. S3Editor is model-agnostic and compatible with various editing approaches. Our extensive qualitative and quantitative results affirm that our approach significantly enhances identity preservation, editing fidelity, as well as temporal consistency.
OTOv3: Automatic Architecture-Agnostic Neural Network Training and Compression from Structured Pruning to Erasing Operators
Dec 15, 2023Compressing a predefined deep neural network (DNN) into a compact sub-network with competitive performance is crucial in the efficient machine learning realm. This topic spans various techniques, from structured pruning to neural architecture search, encompassing both pruning and erasing operators perspectives. Despite advancements, existing methods suffers from complex, multi-stage processes that demand substantial engineering and domain knowledge, limiting their broader applications. We introduce the third-generation Only-Train-Once (OTOv3), which first automatically trains and compresses a general DNN through pruning and erasing operations, creating a compact and competitive sub-network without the need of fine-tuning. OTOv3 simplifies and automates the training and compression process, minimizes the engineering efforts required from users. It offers key technological advancements: (i) automatic search space construction for general DNNs based on dependency graph analysis; (ii) Dual Half-Space Projected Gradient (DHSPG) and its enhanced version with hierarchical search (H2SPG) to reliably solve (hierarchical) structured sparsity problems and ensure sub-network validity; and (iii) automated sub-network construction using solutions from DHSPG/H2SPG and dependency graphs. Our empirical results demonstrate the efficacy of OTOv3 across various benchmarks in structured pruning and neural architecture search. OTOv3 produces sub-networks that match or exceed the state-of-the-arts. The source code will be available at https://github.com/tianyic/only_train_once.
The Efficiency Spectrum of Large Language Models: An Algorithmic Survey
Dec 01, 2023
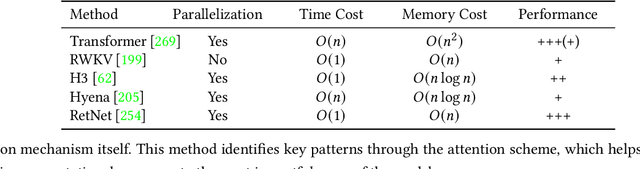
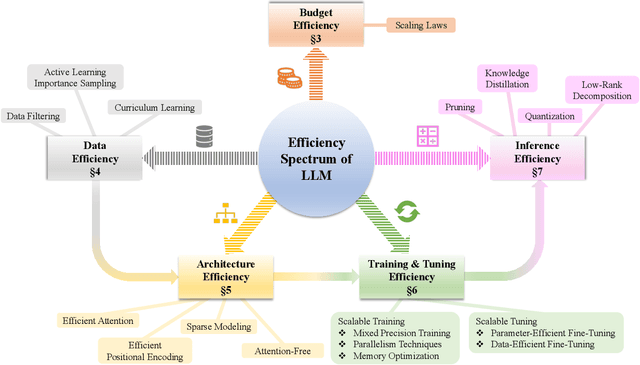
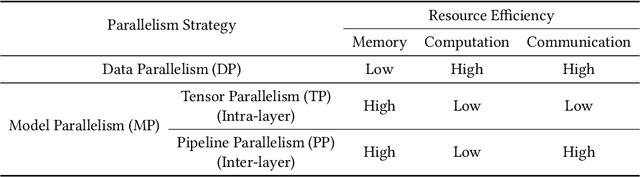
The rapid growth of Large Language Models (LLMs) has been a driving force in transforming various domains, reshaping the artificial general intelligence landscape. However, the increasing computational and memory demands of these models present substantial challenges, hindering both academic research and practical applications. To address these issues, a wide array of methods, including both algorithmic and hardware solutions, have been developed to enhance the efficiency of LLMs. This survey delivers a comprehensive review of algorithmic advancements aimed at improving LLM efficiency. Unlike other surveys that typically focus on specific areas such as training or model compression, this paper examines the multi-faceted dimensions of efficiency essential for the end-to-end algorithmic development of LLMs. Specifically, it covers various topics related to efficiency, including scaling laws, data utilization, architectural innovations, training and tuning strategies, and inference techniques. This paper aims to serve as a valuable resource for researchers and practitioners, laying the groundwork for future innovations in this critical research area. Our repository of relevant references is maintained at url{https://github.com/tding1/Efficient-LLM-Survey}.