 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFeed-forward Gaussian Registration for Head Avatar Creation and Editing
Mar 16, 2026We present MATCH (Multi-view Avatars from Topologically Corresponding Heads), a multi-view Gaussian registration method for high-quality head avatar creation and editing. State-of-the-art multi-view head avatar methods require time-consuming head tracking followed by expensive avatar optimization, often resulting in a total creation time of more than one day. MATCH, in contrast, directly predicts Gaussian splat textures in correspondence from calibrated multi-view images in just 0.5 seconds per frame, without requiring data preprocessing. The learned intra-subject correspondence across frames enables fast creation of personalized head avatars, while correspondence across subjects supports applications such as expression transfer, optimization-free tracking, semantic editing, and identity interpolation. We establish these correspondences end-to-end using a transformer-based model that predicts Gaussian splat textures in the fixed UV layout of a template mesh. To achieve this, we introduce a novel registration-guided attention block, where each UV-map token attends exclusively to image tokens depicting its corresponding mesh region. This design improves efficiency and performance compared to dense cross-view attention. MATCH outperforms existing methods in novel-view synthesis, geometry registration, and head avatar generation, while making avatar creation 10 times faster than the closest competing baseline. The code and model weights are available on the project website.
TeGA: Texture Space Gaussian Avatars for High-Resolution Dynamic Head Modeling
May 08, 2025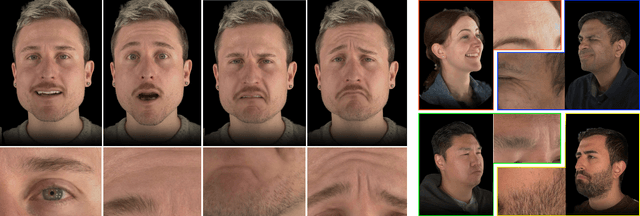
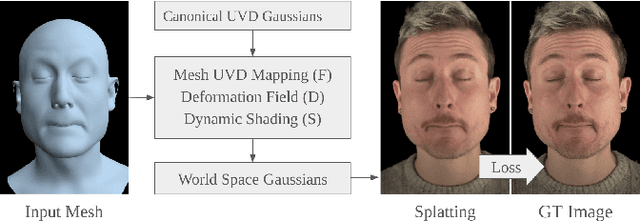


Sparse volumetric reconstruction and rendering via 3D Gaussian splatting have recently enabled animatable 3D head avatars that are rendered under arbitrary viewpoints with impressive photorealism. Today, such photoreal avatars are seen as a key component in emerging applications in telepresence, extended reality, and entertainment. Building a photoreal avatar requires estimating the complex non-rigid motion of different facial components as seen in input video images; due to inaccurate motion estimation, animatable models typically present a loss of fidelity and detail when compared to their non-animatable counterparts, built from an individual facial expression. Also, recent state-of-the-art models are often affected by memory limitations that reduce the number of 3D Gaussians used for modeling, leading to lower detail and quality. To address these problems, we present a new high-detail 3D head avatar model that improves upon the state of the art, largely increasing the number of 3D Gaussians and modeling quality for rendering at 4K resolution. Our high-quality model is reconstructed from multiview input video and builds on top of a mesh-based 3D morphable model, which provides a coarse deformation layer for the head. Photoreal appearance is modelled by 3D Gaussians embedded within the continuous UVD tangent space of this mesh, allowing for more effective densification where most needed. Additionally, these Gaussians are warped by a novel UVD deformation field to capture subtle, localized motion. Our key contribution is the novel deformable Gaussian encoding and overall fitting procedure that allows our head model to preserve appearance detail, while capturing facial motion and other transient high-frequency features such as skin wrinkling.
Pixels2Points: Fusing 2D and 3D Features for Facial Skin Segmentation
Apr 28, 2025Face registration deforms a template mesh to closely fit a 3D face scan, the quality of which commonly degrades in non-skin regions (e.g., hair, beard, accessories), because the optimized template-to-scan distance pulls the template mesh towards the noisy scan surface. Improving registration quality requires a clean separation of skin and non-skin regions on the scan mesh. Existing image-based (2D) or scan-based (3D) segmentation methods however perform poorly. Image-based segmentation outputs multi-view inconsistent masks, and they cannot account for scan inaccuracies or scan-image misalignment, while scan-based methods suffer from lower spatial resolution compared to images. In this work, we introduce a novel method that accurately separates skin from non-skin geometry on 3D human head scans. For this, our method extracts features from multi-view images using a frozen image foundation model and aggregates these features in 3D. These lifted 2D features are then fused with 3D geometric features extracted from the scan mesh, to then predict a segmentation mask directly on the scan mesh. We show that our segmentations improve the registration accuracy over pure 2D or 3D segmentation methods by 8.89% and 14.3%, respectively. Although trained only on synthetic data, our model generalizes well to real data.
Synthetic Prior for Few-Shot Drivable Head Avatar Inversion
Jan 12, 2025We present SynShot, a novel method for the few-shot inversion of a drivable head avatar based on a synthetic prior. We tackle two major challenges. First, training a controllable 3D generative network requires a large number of diverse sequences, for which pairs of images and high-quality tracked meshes are not always available. Second, state-of-the-art monocular avatar models struggle to generalize to new views and expressions, lacking a strong prior and often overfitting to a specific viewpoint distribution. Inspired by machine learning models trained solely on synthetic data, we propose a method that learns a prior model from a large dataset of synthetic heads with diverse identities, expressions, and viewpoints. With few input images, SynShot fine-tunes the pretrained synthetic prior to bridge the domain gap, modeling a photorealistic head avatar that generalizes to novel expressions and viewpoints. We model the head avatar using 3D Gaussian splatting and a convolutional encoder-decoder that outputs Gaussian parameters in UV texture space. To account for the different modeling complexities over parts of the head (e.g., skin vs hair), we embed the prior with explicit control for upsampling the number of per-part primitives. Compared to state-of-the-art monocular methods that require thousands of real training images, SynShot significantly improves novel view and expression synthesis.
Learning to Stabilize Faces
Nov 22, 2024Nowadays, it is possible to scan faces and automatically register them with high quality. However, the resulting face meshes often need further processing: we need to stabilize them to remove unwanted head movement. Stabilization is important for tasks like game development or movie making which require facial expressions to be cleanly separated from rigid head motion. Since manual stabilization is labor-intensive, there have been attempts to automate it. However, previous methods remain impractical: they either still require some manual input, produce imprecise alignments, rely on dubious heuristics and slow optimization, or assume a temporally ordered input. Instead, we present a new learning-based approach that is simple and fully automatic. We treat stabilization as a regression problem: given two face meshes, our network directly predicts the rigid transform between them that brings their skulls into alignment. We generate synthetic training data using a 3D Morphable Model (3DMM), exploiting the fact that 3DMM parameters separate skull motion from facial skin motion. Through extensive experiments we show that our approach outperforms the state-of-the-art both quantitatively and qualitatively on the tasks of stabilizing discrete sets of facial expressions as well as dynamic facial performances. Furthermore, we provide an ablation study detailing the design choices and best practices to help others adopt our approach for their own uses. Supplementary videos can be found on the project webpage syntec-research.github.io/FaceStab.
OFER: Occluded Face Expression Reconstruction
Oct 29, 2024Reconstructing 3D face models from a single image is an inherently ill-posed problem, which becomes even more challenging in the presence of occlusions. In addition to fewer available observations, occlusions introduce an extra source of ambiguity, where multiple reconstructions can be equally valid. Despite the ubiquity of the problem, very few methods address its multi-hypothesis nature. In this paper we introduce OFER, a novel approach for single image 3D face reconstruction that can generate plausible, diverse, and expressive 3D faces, even under strong occlusions. Specifically, we train two diffusion models to generate the shape and expression coefficients of a face parametric model, conditioned on the input image. This approach captures the multi-modal nature of the problem, generating a distribution of solutions as output. Although this addresses the ambiguity problem, the challenge remains to pick the best matching shape to ensure consistency across diverse expressions. To achieve this, we propose a novel ranking mechanism that sorts the outputs of the shape diffusion network based on the predicted shape accuracy scores to select the best match. We evaluate our method using standard benchmarks and introduce CO-545, a new protocol and dataset designed to assess the accuracy of expressive faces under occlusion. Our results show improved performance over occlusion-based methods, with added ability to generate multiple expressions for a given image.
Gaussian Eigen Models for Human Heads
Jul 05, 2024

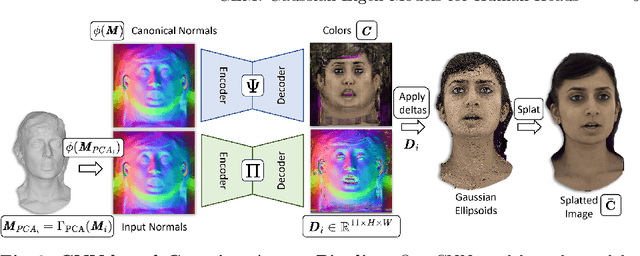
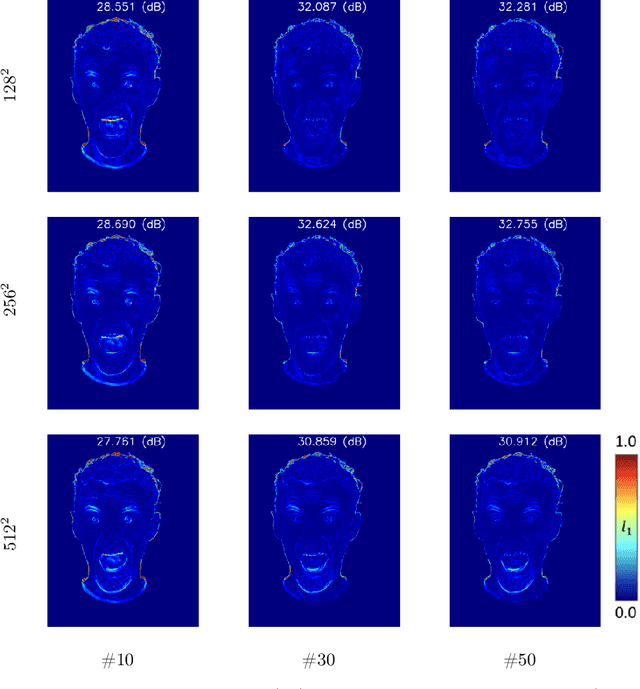
We present personalized Gaussian Eigen Models (GEMs) for human heads, a novel method that compresses dynamic 3D Gaussians into low-dimensional linear spaces. Our approach is inspired by the seminal work of Blanz and Vetter, where a mesh-based 3D morphable model (3DMM) is constructed from registered meshes. Based on dynamic 3D Gaussians, we create a lower-dimensional representation of primitives that applies to most 3DGS head avatars. Specifically, we propose a universal method to distill the appearance of a mesh-controlled UNet Gaussian avatar using an ensemble of linear eigenbasis. We replace heavy CNN-based architectures with a single linear layer improving speed and enabling a range of real-time downstream applications. To create a particular facial expression, one simply needs to perform a dot product between the eigen coefficients and the distilled basis. This efficient method removes the requirement for an input mesh during testing, enhancing simplicity and speed in expression generation. This process is highly efficient and supports real-time rendering on everyday devices, leveraging the effectiveness of standard Gaussian Splatting. In addition, we demonstrate how the GEM can be controlled using a ResNet-based regression architecture. We show and compare self-reenactment and cross-person reenactment to state-of-the-art 3D avatar methods, demonstrating higher quality and better control. A real-time demo showcases the applicability of the GEM representation.
3D Facial Expressions through Analysis-by-Neural-Synthesis
Apr 05, 2024While existing methods for 3D face reconstruction from in-the-wild images excel at recovering the overall face shape, they commonly miss subtle, extreme, asymmetric, or rarely observed expressions. We improve upon these methods with SMIRK (Spatial Modeling for Image-based Reconstruction of Kinesics), which faithfully reconstructs expressive 3D faces from images. We identify two key limitations in existing methods: shortcomings in their self-supervised training formulation, and a lack of expression diversity in the training images. For training, most methods employ differentiable rendering to compare a predicted face mesh with the input image, along with a plethora of additional loss functions. This differentiable rendering loss not only has to provide supervision to optimize for 3D face geometry, camera, albedo, and lighting, which is an ill-posed optimization problem, but the domain gap between rendering and input image further hinders the learning process. Instead, SMIRK replaces the differentiable rendering with a neural rendering module that, given the rendered predicted mesh geometry, and sparsely sampled pixels of the input image, generates a face image. As the neural rendering gets color information from sampled image pixels, supervising with neural rendering-based reconstruction loss can focus solely on the geometry. Further, it enables us to generate images of the input identity with varying expressions while training. These are then utilized as input to the reconstruction model and used as supervision with ground truth geometry. This effectively augments the training data and enhances the generalization for diverse expressions. Our qualitative, quantitative and particularly our perceptual evaluations demonstrate that SMIRK achieves the new state-of-the art performance on accurate expression reconstruction. Project webpage: https://georgeretsi.github.io/smirk/.
Emotional Speech-driven 3D Body Animation via Disentangled Latent Diffusion
Dec 07, 2023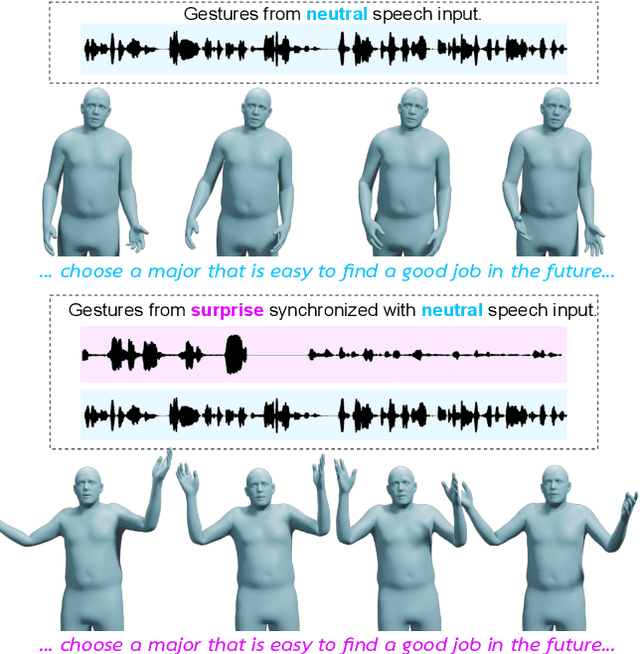



Existing methods for synthesizing 3D human gestures from speech have shown promising results, but they do not explicitly model the impact of emotions on the generated gestures. Instead, these methods directly output animations from speech without control over the expressed emotion. To address this limitation, we present AMUSE, an emotional speech-driven body animation model based on latent diffusion. Our observation is that content (i.e., gestures related to speech rhythm and word utterances), emotion, and personal style are separable. To account for this, AMUSE maps the driving audio to three disentangled latent vectors: one for content, one for emotion, and one for personal style. A latent diffusion model, trained to generate gesture motion sequences, is then conditioned on these latent vectors. Once trained, AMUSE synthesizes 3D human gestures directly from speech with control over the expressed emotions and style by combining the content from the driving speech with the emotion and style of another speech sequence. Randomly sampling the noise of the diffusion model further generates variations of the gesture with the same emotional expressivity. Qualitative, quantitative, and perceptual evaluations demonstrate that AMUSE outputs realistic gesture sequences. Compared to the state of the art, the generated gestures are better synchronized with the speech content and better represent the emotion expressed by the input speech. Our project website is amuse.is.tue.mpg.de.
Learning Disentangled Avatars with Hybrid 3D Representations
Sep 12, 2023
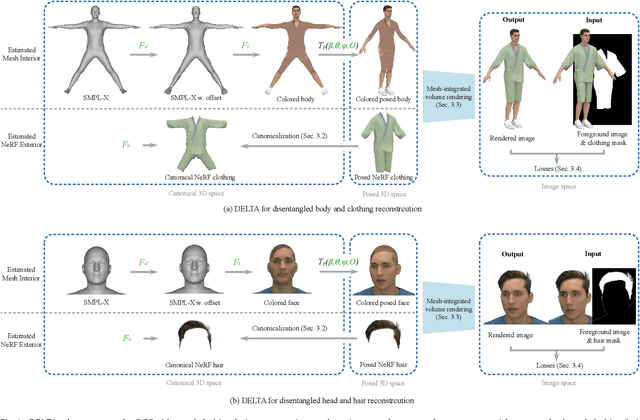
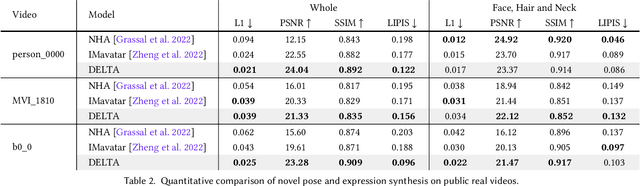
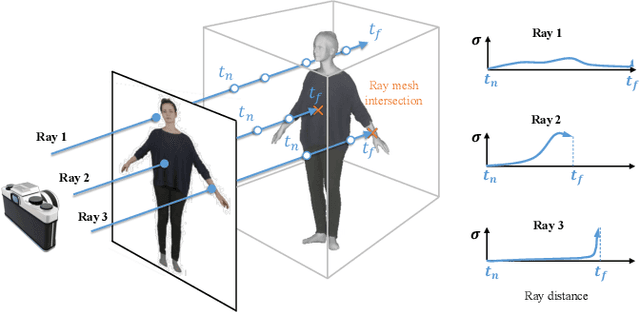
Tremendous efforts have been made to learn animatable and photorealistic human avatars. Towards this end, both explicit and implicit 3D representations are heavily studied for a holistic modeling and capture of the whole human (e.g., body, clothing, face and hair), but neither representation is an optimal choice in terms of representation efficacy since different parts of the human avatar have different modeling desiderata. For example, meshes are generally not suitable for modeling clothing and hair. Motivated by this, we present Disentangled Avatars~(DELTA), which models humans with hybrid explicit-implicit 3D representations. DELTA takes a monocular RGB video as input, and produces a human avatar with separate body and clothing/hair layers. Specifically, we demonstrate two important applications for DELTA. For the first one, we consider the disentanglement of the human body and clothing and in the second, we disentangle the face and hair. To do so, DELTA represents the body or face with an explicit mesh-based parametric 3D model and the clothing or hair with an implicit neural radiance field. To make this possible, we design an end-to-end differentiable renderer that integrates meshes into volumetric rendering, enabling DELTA to learn directly from monocular videos without any 3D supervision. Finally, we show that how these two applications can be easily combined to model full-body avatars, such that the hair, face, body and clothing can be fully disentangled yet jointly rendered. Such a disentanglement enables hair and clothing transfer to arbitrary body shapes. We empirically validate the effectiveness of DELTA's disentanglement by demonstrating its promising performance on disentangled reconstruction, virtual clothing try-on and hairstyle transfer. To facilitate future research, we also release an open-sourced pipeline for the study of hybrid human avatar modeling.