 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCombining facial videos and biosignals for stress estimation during driving
Jan 07, 2026Reliable stress recognition from facial videos is challenging due to stress's subjective nature and voluntary facial control. While most methods rely on Facial Action Units, the role of disentangled 3D facial geometry remains underexplored. We address this by analyzing stress during distracted driving using EMOCA-derived 3D expression and pose coefficients. Paired hypothesis tests between baseline and stressor phases reveal that 41 of 56 coefficients show consistent, phase-specific stress responses comparable to physiological markers. Building on this, we propose a Transformer-based temporal modeling framework and assess unimodal, early-fusion, and cross-modal attention strategies. Cross-Modal Attention fusion of EMOCA and physiological signals achieves best performance (AUROC 92\%, Accuracy 86.7\%), with EMOCA-gaze fusion also competitive (AUROC 91.8\%). This highlights the effectiveness of temporal modeling and cross-modal attention for stress recognition.
Reflections on Diversity: A Real-time Virtual Mirror for Inclusive 3D Face Transformations
Mar 25, 2025Real-time 3D face manipulation has significant applications in virtual reality, social media and human-computer interaction. This paper introduces a novel system, which we call Mirror of Diversity (MOD), that combines Generative Adversarial Networks (GANs) for texture manipulation and 3D Morphable Models (3DMMs) for facial geometry to achieve realistic face transformations that reflect various demographic characteristics, emphasizing the beauty of diversity and the universality of human features. As participants sit in front of a computer monitor with a camera positioned above, their facial characteristics are captured in real time and can further alter their digital face reconstruction with transformations reflecting different demographic characteristics, such as gender and ethnicity (e.g., a person from Africa, Asia, Europe). Another feature of our system, which we call Collective Face, generates an averaged face representation from multiple participants' facial data. A comprehensive evaluation protocol is implemented to assess the realism and demographic accuracy of the transformations. Qualitative feedback is gathered through participant questionnaires, which include comparisons of MOD transformations with similar filters on platforms like Snapchat and TikTok. Additionally, quantitative analysis is conducted using a pretrained Convolutional Neural Network that predicts gender and ethnicity, to validate the accuracy of demographic transformations.
A Transformer-Based Framework for Greek Sign Language Production using Extended Skeletal Motion Representations
Mar 04, 2025Sign Languages are the primary form of communication for Deaf communities across the world. To break the communication barriers between the Deaf and Hard-of-Hearing and the hearing communities, it is imperative to build systems capable of translating the spoken language into sign language and vice versa. Building on insights from previous research, we propose a deep learning model for Sign Language Production (SLP), which to our knowledge is the first attempt on Greek SLP. We tackle this task by utilizing a transformer-based architecture that enables the translation from text input to human pose keypoints, and the opposite. We evaluate the effectiveness of the proposed pipeline on the Greek SL dataset Elementary23, through a series of comparative analyses and ablation studies. Our pipeline's components, which include data-driven gloss generation, training through video to text translation and a scheduling algorithm for teacher forcing - auto-regressive decoding seem to actively enhance the quality of produced SL videos.
3D Facial Expressions through Analysis-by-Neural-Synthesis
Apr 05, 2024While existing methods for 3D face reconstruction from in-the-wild images excel at recovering the overall face shape, they commonly miss subtle, extreme, asymmetric, or rarely observed expressions. We improve upon these methods with SMIRK (Spatial Modeling for Image-based Reconstruction of Kinesics), which faithfully reconstructs expressive 3D faces from images. We identify two key limitations in existing methods: shortcomings in their self-supervised training formulation, and a lack of expression diversity in the training images. For training, most methods employ differentiable rendering to compare a predicted face mesh with the input image, along with a plethora of additional loss functions. This differentiable rendering loss not only has to provide supervision to optimize for 3D face geometry, camera, albedo, and lighting, which is an ill-posed optimization problem, but the domain gap between rendering and input image further hinders the learning process. Instead, SMIRK replaces the differentiable rendering with a neural rendering module that, given the rendered predicted mesh geometry, and sparsely sampled pixels of the input image, generates a face image. As the neural rendering gets color information from sampled image pixels, supervising with neural rendering-based reconstruction loss can focus solely on the geometry. Further, it enables us to generate images of the input identity with varying expressions while training. These are then utilized as input to the reconstruction model and used as supervision with ground truth geometry. This effectively augments the training data and enhances the generalization for diverse expressions. Our qualitative, quantitative and particularly our perceptual evaluations demonstrate that SMIRK achieves the new state-of-the art performance on accurate expression reconstruction. Project webpage: https://georgeretsi.github.io/smirk/.
Neural Text to Articulate Talk: Deep Text to Audiovisual Speech Synthesis achieving both Auditory and Photo-realism
Dec 11, 2023Recent advances in deep learning for sequential data have given rise to fast and powerful models that produce realistic videos of talking humans. The state of the art in talking face generation focuses mainly on lip-syncing, being conditioned on audio clips. However, having the ability to synthesize talking humans from text transcriptions rather than audio is particularly beneficial for many applications and is expected to receive more and more attention, following the recent breakthroughs in large language models. For that, most methods implement a cascaded 2-stage architecture of a text-to-speech module followed by an audio-driven talking face generator, but this ignores the highly complex interplay between audio and visual streams that occurs during speaking. In this paper, we propose the first, to the best of our knowledge, text-driven audiovisual speech synthesizer that uses Transformers and does not follow a cascaded approach. Our method, which we call NEUral Text to ARticulate Talk (NEUTART), is a talking face generator that uses a joint audiovisual feature space, as well as speech-informed 3D facial reconstructions and a lip-reading loss for visual supervision. The proposed model produces photorealistic talking face videos with human-like articulation and well-synced audiovisual streams. Our experiments on audiovisual datasets as well as in-the-wild videos reveal state-of-the-art generation quality both in terms of objective metrics and human evaluation.
3D Neural Sculpting (3DNS): Editing Neural Signed Distance Functions
Sep 28, 2022
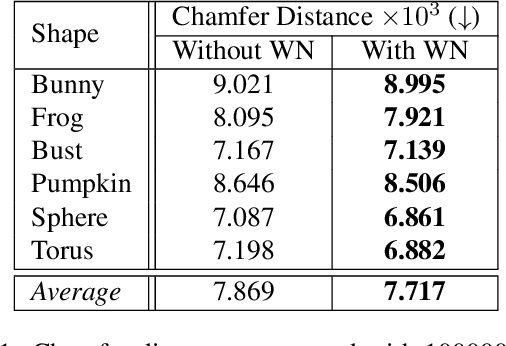
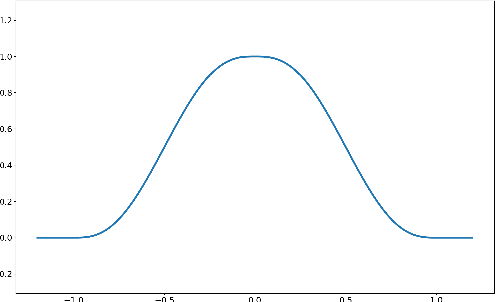
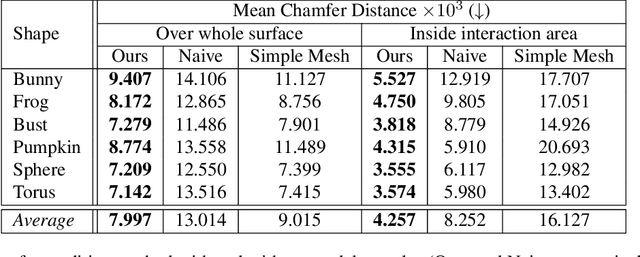
In recent years, implicit surface representations through neural networks that encode the signed distance have gained popularity and have achieved state-of-the-art results in various tasks (e.g. shape representation, shape reconstruction, and learning shape priors). However, in contrast to conventional shape representations such as polygon meshes, the implicit representations cannot be easily edited and existing works that attempt to address this problem are extremely limited. In this work, we propose the first method for efficient interactive editing of signed distance functions expressed through neural networks, allowing free-form editing. Inspired by 3D sculpting software for meshes, we use a brush-based framework that is intuitive and can in the future be used by sculptors and digital artists. In order to localize the desired surface deformations, we regulate the network by using a copy of it to sample the previously expressed surface. We introduce a novel framework for simulating sculpting-style surface edits, in conjunction with interactive surface sampling and efficient adaptation of network weights. We qualitatively and quantitatively evaluate our method in various different 3D objects and under many different edits. The reported results clearly show that our method yields high accuracy, in terms of achieving the desired edits, while at the same time preserving the geometry outside the interaction areas.
Neural Sign Reenactor: Deep Photorealistic Sign Language Retargeting
Sep 03, 2022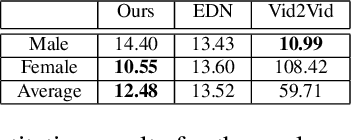
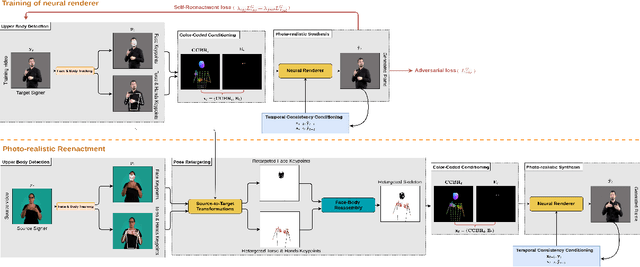

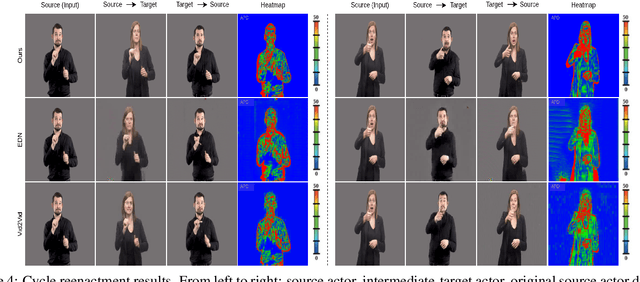
In this paper, we introduce a neural rendering pipeline for transferring the facial expressions, head pose and body movements of one person in a source video to another in a target video. We apply our method to the challenging case of Sign Language videos: given a source video of a sign language user, we can faithfully transfer the performed manual (e.g. handshape, palm orientation, movement, location) and non-manual (e.g. eye gaze, facial expressions, head movements) signs to a target video in a photo-realistic manner. To effectively capture the aforementioned cues, which are crucial for sign language communication, we build upon an effective combination of the most robust and reliable deep learning methods for body, hand and face tracking that have been introduced lately. Using a 3D-aware representation, the estimated motions of the body parts are combined and retargeted to the target signer. They are then given as conditional input to our Video Rendering Network, which generates temporally consistent and photo-realistic videos. We conduct detailed qualitative and quantitative evaluations and comparisons, which demonstrate the effectiveness of our approach and its advantages over existing approaches. Our method yields promising results of unprecedented realism and can be used for Sign Language Anonymization. In addition, it can be readily applicable to reenactment of other types of full body activities (dancing, acting performance, exercising, etc.), as well as to the synthesis module of Sign Language Production systems.
Visual Speech-Aware Perceptual 3D Facial Expression Reconstruction from Videos
Jul 22, 2022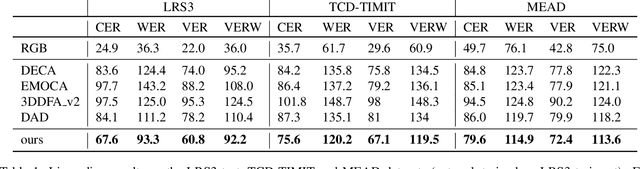
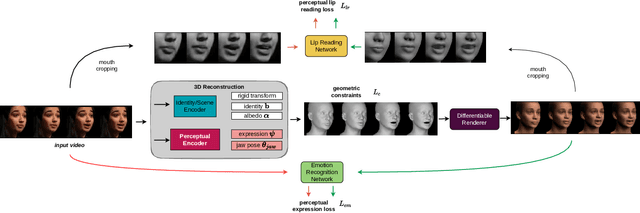


The recent state of the art on monocular 3D face reconstruction from image data has made some impressive advancements, thanks to the advent of Deep Learning. However, it has mostly focused on input coming from a single RGB image, overlooking the following important factors: a) Nowadays, the vast majority of facial image data of interest do not originate from single images but rather from videos, which contain rich dynamic information. b) Furthermore, these videos typically capture individuals in some form of verbal communication (public talks, teleconferences, audiovisual human-computer interactions, interviews, monologues/dialogues in movies, etc). When existing 3D face reconstruction methods are applied in such videos, the artifacts in the reconstruction of the shape and motion of the mouth area are often severe, since they do not match well with the speech audio. To overcome the aforementioned limitations, we present the first method for visual speech-aware perceptual reconstruction of 3D mouth expressions. We do this by proposing a "lipread" loss, which guides the fitting process so that the elicited perception from the 3D reconstructed talking head resembles that of the original video footage. We demonstrate that, interestingly, the lipread loss is better suited for 3D reconstruction of mouth movements compared to traditional landmark losses, and even direct 3D supervision. Furthermore, the devised method does not rely on any text transcriptions or corresponding audio, rendering it ideal for training in unlabeled datasets. We verify the efficiency of our method through exhaustive objective evaluations on three large-scale datasets, as well as subjective evaluation with two web-based user studies.
Neural Emotion Director: Speech-preserving semantic control of facial expressions in "in-the-wild" videos
Dec 01, 2021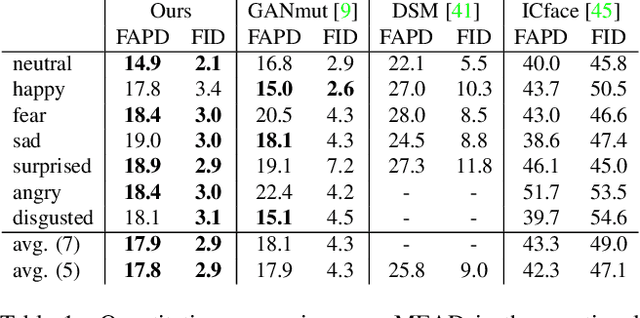
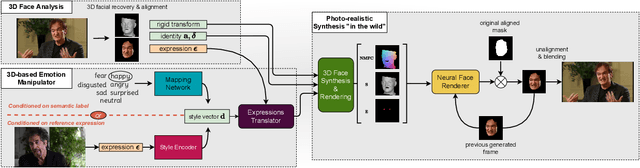


In this paper, we introduce a novel deep learning method for photo-realistic manipulation of the emotional state of actors in "in-the-wild" videos. The proposed method is based on a parametric 3D face representation of the actor in the input scene that offers a reliable disentanglement of the facial identity from the head pose and facial expressions. It then uses a novel deep domain translation framework that alters the facial expressions in a consistent and plausible manner, taking into account their dynamics. Finally, the altered facial expressions are used to photo-realistically manipulate the facial region in the input scene based on an especially-designed neural face renderer. To the best of our knowledge, our method is the first to be capable of controlling the actor's facial expressions by even using as a sole input the semantic labels of the manipulated emotions, while at the same time preserving the speech-related lip movements. We conduct extensive qualitative and quantitative evaluations and comparisons, which demonstrate the effectiveness of our approach and the especially promising results that we obtain. Our method opens a plethora of new possibilities for useful applications of neural rendering technologies, ranging from movie post-production and video games to photo-realistic affective avatars.
Deep Semantic Manipulation of Facial Videos
Nov 15, 2021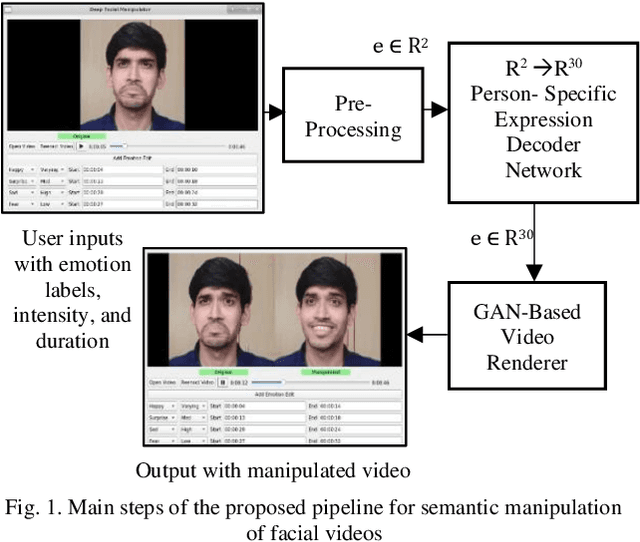
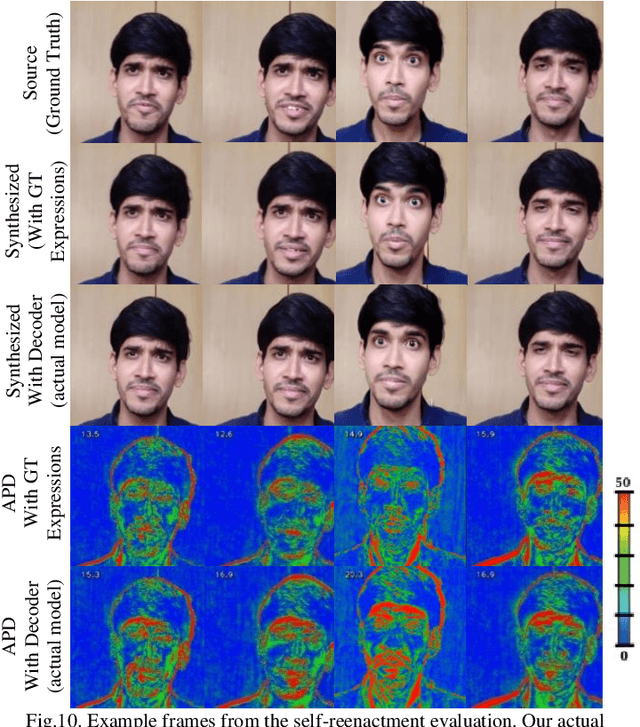
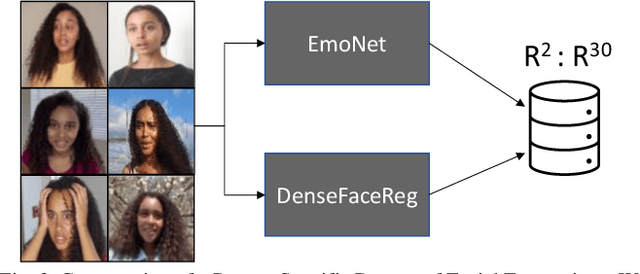

Editing and manipulating facial features in videos is an interesting and important field of research with a plethora of applications, ranging from movie post-production and visual effects to realistic avatars for video games and virtual assistants. To the best of our knowledge, this paper proposes the first method to perform photorealistic manipulation of facial expressions in videos. Our method supports semantic video manipulation based on neural rendering and 3D-based facial expression modelling. We focus on interactive manipulation of the videos by altering and controlling the facial expressions, achieving promising photorealistic results. The proposed method is based on a disentangled representation and estimation of the 3D facial shape and activity, providing the user with intuitive and easy-to-use control of the facial expressions in the input video. We also introduce a user-friendly, interactive AI tool that processes human-readable semantic labels about the desired emotion manipulations in specific parts of the input video and synthesizes photorealistic manipulated videos. We achieve that by mapping the emotion labels to valence-arousal (VA) values, which in turn are mapped to disentangled 3D facial expressions through an especially designed and trained expression decoder network. The paper presents detailed qualitative and quantitative experiments, which demonstrate the effectiveness of our system and the promising results it achieves. Additional results and videos can be found at the supplementary material (https://github.com/Girish-03/DeepSemManipulation).