 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding Multimodal Complementarity for Single-Frame Action Anticipation
Jan 29, 2026Human action anticipation is commonly treated as a video understanding problem, implicitly assuming that dense temporal information is required to reason about future actions. In this work, we challenge this assumption by investigating what can be achieved when action anticipation is constrained to a single visual observation. We ask a fundamental question: how much information about the future is already encoded in a single frame, and how can it be effectively exploited? Building on our prior work on Action Anticipation at a Glimpse (AAG), we conduct a systematic investigation of single-frame action anticipation enriched with complementary sources of information. We analyze the contribution of RGB appearance, depth-based geometric cues, and semantic representations of past actions, and investigate how different multimodal fusion strategies, keyframe selection policies and past-action history sources influence anticipation performance. Guided by these findings, we consolidate the most effective design choices into AAG+, a refined single-frame anticipation framework. Despite operating on a single frame, AAG+ consistently improves upon the original AAG and achieves performance comparable to, or exceeding, that of state-of-the-art video-based methods on challenging anticipation benchmarks including IKEA-ASM, Meccano and Assembly101. Our results offer new insights into the limits and potential of single-frame action anticipation, and clarify when dense temporal modeling is necessary and when a carefully selected glimpse is sufficient.
OCCAM: Class-Agnostic, Training-Free, Prior-Free and Multi-Class Object Counting
Jan 20, 2026Class-Agnostic object Counting (CAC) involves counting instances of objects from arbitrary classes within an image. Due to its practical importance, CAC has received increasing attention in recent years. Most existing methods assume a single object class per image, rely on extensive training of large deep learning models and address the problem by incorporating additional information, such as visual exemplars or text prompts. In this paper, we present OCCAM, the first training-free approach to CAC that operates without the need of any supplementary information. Moreover, our approach addresses the multi-class variant of the problem, as it is capable of counting the object instances in each and every class among arbitrary object classes within an image. We leverage Segment Anything Model 2 (SAM2), a foundation model, and a custom threshold-based variant of the First Integer Neighbor Clustering Hierarchy (FINCH) algorithm to achieve competitive performance on widely used benchmark datasets, FSC-147 and CARPK. We propose a synthetic multi-class dataset and F1 score as a more suitable evaluation metric. The code for our method and the proposed synthetic dataset will be made publicly available at https://mikespanak.github.io/OCCAM_counter.
Combining facial videos and biosignals for stress estimation during driving
Jan 07, 2026Reliable stress recognition from facial videos is challenging due to stress's subjective nature and voluntary facial control. While most methods rely on Facial Action Units, the role of disentangled 3D facial geometry remains underexplored. We address this by analyzing stress during distracted driving using EMOCA-derived 3D expression and pose coefficients. Paired hypothesis tests between baseline and stressor phases reveal that 41 of 56 coefficients show consistent, phase-specific stress responses comparable to physiological markers. Building on this, we propose a Transformer-based temporal modeling framework and assess unimodal, early-fusion, and cross-modal attention strategies. Cross-Modal Attention fusion of EMOCA and physiological signals achieves best performance (AUROC 92\%, Accuracy 86.7\%), with EMOCA-gaze fusion also competitive (AUROC 91.8\%). This highlights the effectiveness of temporal modeling and cross-modal attention for stress recognition.
Reflections on Diversity: A Real-time Virtual Mirror for Inclusive 3D Face Transformations
Mar 25, 2025Real-time 3D face manipulation has significant applications in virtual reality, social media and human-computer interaction. This paper introduces a novel system, which we call Mirror of Diversity (MOD), that combines Generative Adversarial Networks (GANs) for texture manipulation and 3D Morphable Models (3DMMs) for facial geometry to achieve realistic face transformations that reflect various demographic characteristics, emphasizing the beauty of diversity and the universality of human features. As participants sit in front of a computer monitor with a camera positioned above, their facial characteristics are captured in real time and can further alter their digital face reconstruction with transformations reflecting different demographic characteristics, such as gender and ethnicity (e.g., a person from Africa, Asia, Europe). Another feature of our system, which we call Collective Face, generates an averaged face representation from multiple participants' facial data. A comprehensive evaluation protocol is implemented to assess the realism and demographic accuracy of the transformations. Qualitative feedback is gathered through participant questionnaires, which include comparisons of MOD transformations with similar filters on platforms like Snapchat and TikTok. Additionally, quantitative analysis is conducted using a pretrained Convolutional Neural Network that predicts gender and ethnicity, to validate the accuracy of demographic transformations.
Enhancing Action Recognition by Leveraging the Hierarchical Structure of Actions and Textual Context
Oct 28, 2024



The sequential execution of actions and their hierarchical structure consisting of different levels of abstraction, provide features that remain unexplored in the task of action recognition. In this study, we present a novel approach to improve action recognition by exploiting the hierarchical organization of actions and by incorporating contextualized textual information, including location and prior actions to reflect the sequential context. To achieve this goal, we introduce a novel transformer architecture tailored for action recognition that utilizes both visual and textual features. Visual features are obtained from RGB and optical flow data, while text embeddings represent contextual information. Furthermore, we define a joint loss function to simultaneously train the model for both coarse and fine-grained action recognition, thereby exploiting the hierarchical nature of actions. To demonstrate the effectiveness of our method, we extend the Toyota Smarthome Untrimmed (TSU) dataset to introduce action hierarchies, introducing the Hierarchical TSU dataset. We also conduct an ablation study to assess the impact of different methods for integrating contextual and hierarchical data on action recognition performance. Results show that the proposed approach outperforms pre-trained SOTA methods when trained with the same hyperparameters. Moreover, they also show a 17.12% improvement in top-1 accuracy over the equivalent fine-grained RGB version when using ground-truth contextual information, and a 5.33% improvement when contextual information is obtained from actual predictions.
D-PoSE: Depth as an Intermediate Representation for 3D Human Pose and Shape Estimation
Oct 07, 2024We present D-PoSE (Depth as an Intermediate Representation for 3D Human Pose and Shape Estimation), a one-stage method that estimates human pose and SMPL-X shape parameters from a single RGB image. Recent works use larger models with transformer backbones and decoders to improve the accuracy in human pose and shape (HPS) benchmarks. D-PoSE proposes a vision based approach that uses the estimated human depth-maps as an intermediate representation for HPS and leverages training with synthetic data and the ground-truth depth-maps provided with them for depth supervision during training. Although trained on synthetic datasets, D-PoSE achieves state-of-the-art performance on the real-world benchmark datasets, EMDB and 3DPW. Despite its simple lightweight design and the CNN backbone, it outperforms ViT-based models that have a number of parameters that is larger by almost an order of magnitude. D-PoSE code is available at: https://github.com/nvasilik/D-PoSE
ENACT: Entropy-based Clustering of Attention Input for Improving the Computational Performance of Object Detection Transformers
Sep 11, 2024


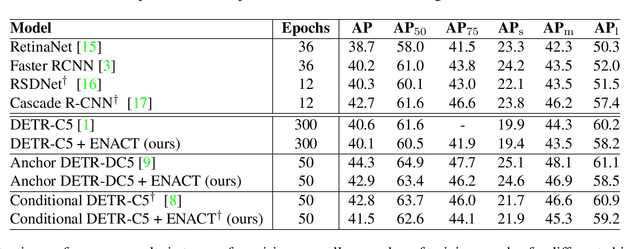
Transformers demonstrate competitive performance in terms of precision on the problem of vision-based object detection. However, they require considerable computational resources due to the quadratic size of the attention weights. In this work, we propose to cluster the transformer input on the basis of its entropy. The reason for this is that the self-information of each pixel (whose sum is the entropy), is likely to be similar among pixels corresponding to the same objects. Clustering reduces the size of data given as input to the transformer and therefore reduces training time and GPU memory usage, while at the same time preserves meaningful information to be passed through the remaining parts of the network. The proposed process is organized in a module called ENACT, that can be plugged-in any transformer architecture that consists of a multi-head self-attention computation in its encoder. We ran extensive experiments using the COCO object detection dataset, and three detection transformers. The obtained results demonstrate that in all tested cases, there is consistent reduction in the required computational resources, while the precision of the detection task is only slightly reduced. The code of the ENACT module will become available at https://github.com/GSavathrakis/ENACT
Anticipating Object State Changes
May 21, 2024Anticipating object state changes in images and videos is a challenging problem whose solution has important implications in vision-based scene understanding, automated monitoring systems, and action planning. In this work, we propose the first method for solving this problem. The proposed method predicts object state changes that will occur in the near future as a result of yet unseen human actions. To address this new problem, we propose a novel framework that integrates learnt visual features that represent the recent visual information, with natural language (NLP) features that represent past object state changes and actions. Leveraging the extensive and challenging Ego4D dataset which provides a large-scale collection of first-person perspective videos across numerous interaction scenarios, we introduce new curated annotation data for the object state change anticipation task (OSCA), noted as Ego4D-OSCA. An extensive experimental evaluation was conducted that demonstrates the efficacy of the proposed method in predicting object state changes in dynamic scenarios. The proposed work underscores the potential of integrating video and linguistic cues to enhance the predictive performance of video understanding systems. Moreover, it lays the groundwork for future research on the new task of object state change anticipation. The source code and the new annotation data (Ego4D-OSCA) will be made publicly available.
Fusing Domain-Specific Content from Large Language Models into Knowledge Graphs for Enhanced Zero Shot Object State Classification
Mar 25, 2024



Domain-specific knowledge can significantly contribute to addressing a wide variety of vision tasks. However, the generation of such knowledge entails considerable human labor and time costs. This study investigates the potential of Large Language Models (LLMs) in generating and providing domain-specific information through semantic embeddings. To achieve this, an LLM is integrated into a pipeline that utilizes Knowledge Graphs and pre-trained semantic vectors in the context of the Vision-based Zero-shot Object State Classification task. We thoroughly examine the behavior of the LLM through an extensive ablation study. Our findings reveal that the integration of LLM-based embeddings, in combination with general-purpose pre-trained embeddings, leads to substantial performance improvements. Drawing insights from this ablation study, we conduct a comparative analysis against competing models, thereby highlighting the state-of-the-art performance achieved by the proposed approach.
Leveraging Knowledge Graphs for Zero-Shot Object-agnostic State Classification
Jul 22, 2023



We investigate the problem of Object State Classification (OSC) as a zero-shot learning problem. Specifically, we propose the first Object-agnostic State Classification (OaSC) method that infers the state of a certain object without relying on the knowledge or the estimation of the object class. In that direction, we capitalize on Knowledge Graphs (KGs) for structuring and organizing knowledge, which, in combination with visual information, enable the inference of the states of objects in object/state pairs that have not been encountered in the method's training set. A series of experiments investigate the performance of the proposed method in various settings, against several hypotheses and in comparison with state of the art approaches for object attribute classification. The experimental results demonstrate that the knowledge of an object class is not decisive for the prediction of its state. Moreover, the proposed OaSC method outperforms existing methods in all datasets and benchmarks by a great margin.