 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding Multimodal Complementarity for Single-Frame Action Anticipation
Jan 29, 2026Human action anticipation is commonly treated as a video understanding problem, implicitly assuming that dense temporal information is required to reason about future actions. In this work, we challenge this assumption by investigating what can be achieved when action anticipation is constrained to a single visual observation. We ask a fundamental question: how much information about the future is already encoded in a single frame, and how can it be effectively exploited? Building on our prior work on Action Anticipation at a Glimpse (AAG), we conduct a systematic investigation of single-frame action anticipation enriched with complementary sources of information. We analyze the contribution of RGB appearance, depth-based geometric cues, and semantic representations of past actions, and investigate how different multimodal fusion strategies, keyframe selection policies and past-action history sources influence anticipation performance. Guided by these findings, we consolidate the most effective design choices into AAG+, a refined single-frame anticipation framework. Despite operating on a single frame, AAG+ consistently improves upon the original AAG and achieves performance comparable to, or exceeding, that of state-of-the-art video-based methods on challenging anticipation benchmarks including IKEA-ASM, Meccano and Assembly101. Our results offer new insights into the limits and potential of single-frame action anticipation, and clarify when dense temporal modeling is necessary and when a carefully selected glimpse is sufficient.
A vision-based framework for human behavior understanding in industrial assembly lines
Sep 25, 2024



This paper introduces a vision-based framework for capturing and understanding human behavior in industrial assembly lines, focusing on car door manufacturing. The framework leverages advanced computer vision techniques to estimate workers' locations and 3D poses and analyze work postures, actions, and task progress. A key contribution is the introduction of the CarDA dataset, which contains domain-relevant assembly actions captured in a realistic setting to support the analysis of the framework for human pose and action analysis. The dataset comprises time-synchronized multi-camera RGB-D videos, motion capture data recorded in a real car manufacturing environment, and annotations for EAWS-based ergonomic risk scores and assembly activities. Experimental results demonstrate the effectiveness of the proposed approach in classifying worker postures and robust performance in monitoring assembly task progress.
Anticipating Object State Changes
May 21, 2024Anticipating object state changes in images and videos is a challenging problem whose solution has important implications in vision-based scene understanding, automated monitoring systems, and action planning. In this work, we propose the first method for solving this problem. The proposed method predicts object state changes that will occur in the near future as a result of yet unseen human actions. To address this new problem, we propose a novel framework that integrates learnt visual features that represent the recent visual information, with natural language (NLP) features that represent past object state changes and actions. Leveraging the extensive and challenging Ego4D dataset which provides a large-scale collection of first-person perspective videos across numerous interaction scenarios, we introduce new curated annotation data for the object state change anticipation task (OSCA), noted as Ego4D-OSCA. An extensive experimental evaluation was conducted that demonstrates the efficacy of the proposed method in predicting object state changes in dynamic scenarios. The proposed work underscores the potential of integrating video and linguistic cues to enhance the predictive performance of video understanding systems. Moreover, it lays the groundwork for future research on the new task of object state change anticipation. The source code and the new annotation data (Ego4D-OSCA) will be made publicly available.
Graphing the Future: Activity and Next Active Object Prediction using Graph-based Activity Representations
Sep 12, 2022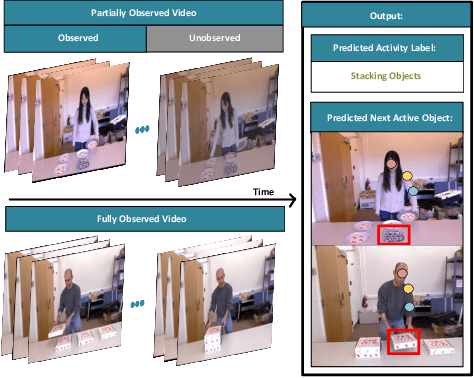

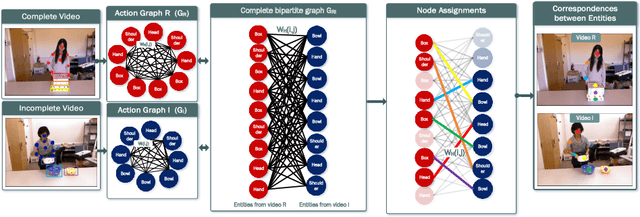
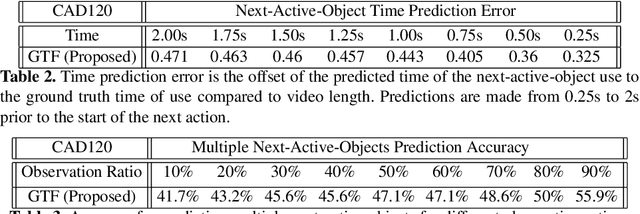
We present a novel approach for the visual prediction of human-object interactions in videos. Rather than forecasting the human and object motion or the future hand-object contact points, we aim at predicting (a)the class of the on-going human-object interaction and (b) the class(es) of the next active object(s) (NAOs), i.e., the object(s) that will be involved in the interaction in the near future as well as the time the interaction will occur. Graph matching relies on the efficient Graph Edit distance (GED) method. The experimental evaluation of the proposed approach was conducted using two well-established video datasets that contain human-object interactions, namely the MSR Daily Activities and the CAD120. High prediction accuracy was obtained for both action prediction and NAO forecasting.