 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnticipating Object State Changes
May 21, 2024Anticipating object state changes in images and videos is a challenging problem whose solution has important implications in vision-based scene understanding, automated monitoring systems, and action planning. In this work, we propose the first method for solving this problem. The proposed method predicts object state changes that will occur in the near future as a result of yet unseen human actions. To address this new problem, we propose a novel framework that integrates learnt visual features that represent the recent visual information, with natural language (NLP) features that represent past object state changes and actions. Leveraging the extensive and challenging Ego4D dataset which provides a large-scale collection of first-person perspective videos across numerous interaction scenarios, we introduce new curated annotation data for the object state change anticipation task (OSCA), noted as Ego4D-OSCA. An extensive experimental evaluation was conducted that demonstrates the efficacy of the proposed method in predicting object state changes in dynamic scenarios. The proposed work underscores the potential of integrating video and linguistic cues to enhance the predictive performance of video understanding systems. Moreover, it lays the groundwork for future research on the new task of object state change anticipation. The source code and the new annotation data (Ego4D-OSCA) will be made publicly available.
Graphing the Future: Activity and Next Active Object Prediction using Graph-based Activity Representations
Sep 12, 2022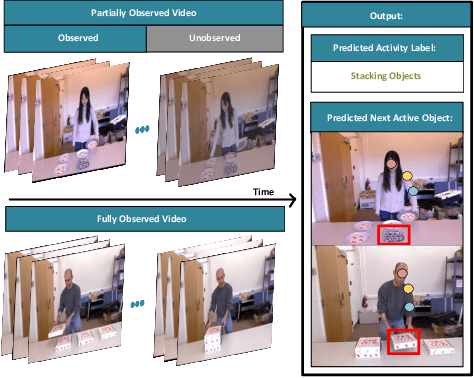

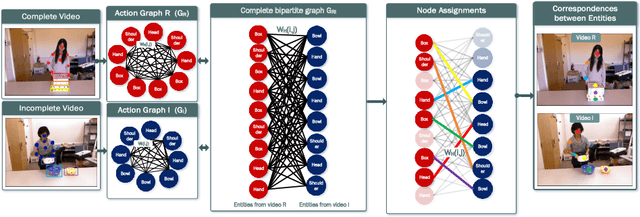
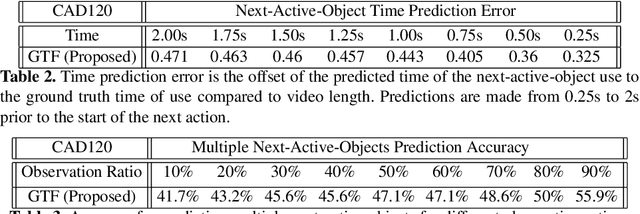
We present a novel approach for the visual prediction of human-object interactions in videos. Rather than forecasting the human and object motion or the future hand-object contact points, we aim at predicting (a)the class of the on-going human-object interaction and (b) the class(es) of the next active object(s) (NAOs), i.e., the object(s) that will be involved in the interaction in the near future as well as the time the interaction will occur. Graph matching relies on the efficient Graph Edit distance (GED) method. The experimental evaluation of the proposed approach was conducted using two well-established video datasets that contain human-object interactions, namely the MSR Daily Activities and the CAD120. High prediction accuracy was obtained for both action prediction and NAO forecasting.
DysLexML: Screening Tool for Dyslexia Using Machine Learning
Mar 14, 2019
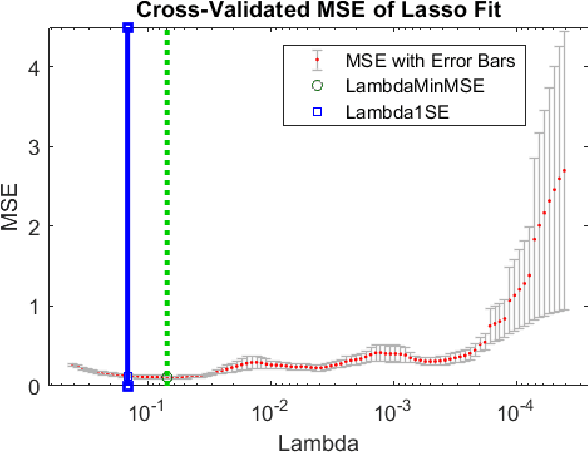
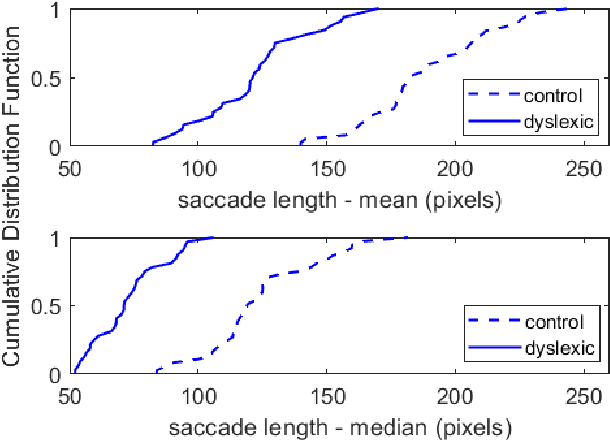
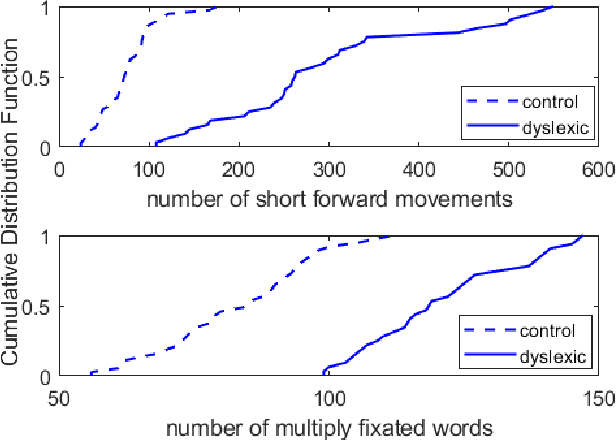
Eye movements during text reading can provide insights about reading disorders. Via eye-trackers, we can measure when, where and how eyes move with relation to the words they read. Machine Learning (ML) algorithms can decode this information and provide differential analysis. This work developed DysLexML, a screening tool for developmental dyslexia that applies various ML algorithms to analyze fixation points recorded via eye-tracking during silent reading of children. It comparatively evaluated its performance using measurements collected in a systematic field study with 69 native Greek speakers, children, 32 of which were diagnosed as dyslexic by the official governmental agency for diagnosing learning and reading difficulties in Greece. We examined a large set of features based on statistical properties of fixations and saccadic movements and identified the ones with prominent predictive power, performing dimensionality reduction. Specifically, DysLexML achieves its best performance using linear SVM, with an a accuracy of 97 %, with a small feature set, namely saccade length, number of short forward movements, and number of multiply fixated words. Furthermore, we analyzed the impact of noise on the fixation positions and showed that DysLexML is accurate and robust in the presence of noise. These encouraging results set the basis for developing screening tools in less controlled, larger-scale environments, with inexpensive eye-trackers, potentially reaching a larger population for early intervention.