 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Activation with Knowledge Distillation for Energy-Efficient Spiking NN Ensembles
Feb 19, 2025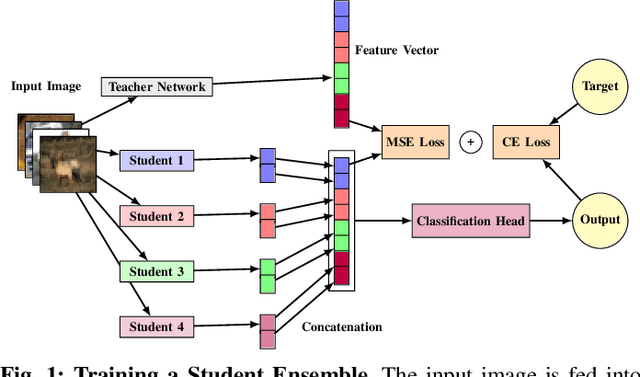
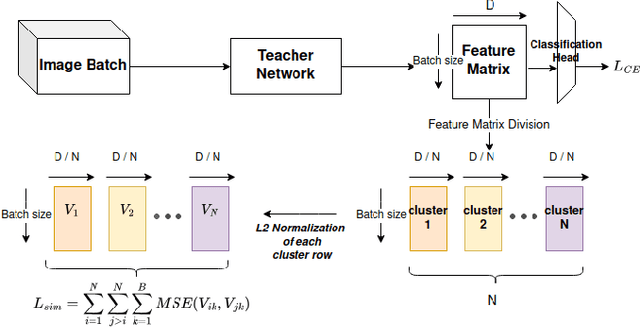
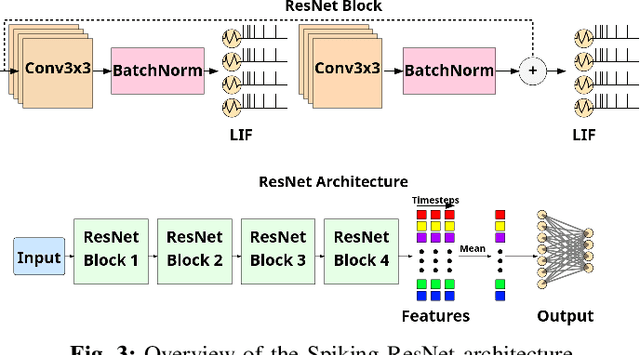
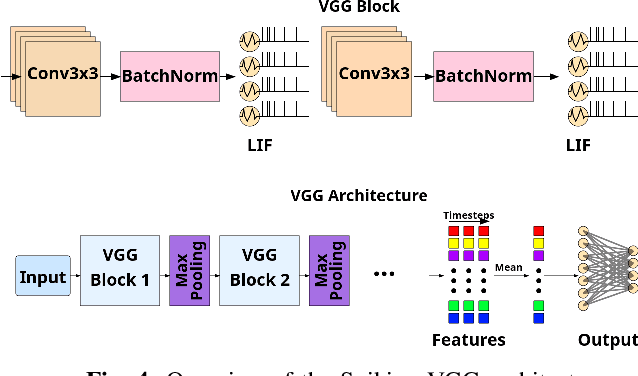
While foundation AI models excel at tasks like classification and decision-making, their high energy consumption makes them unsuitable for energy-constrained applications. Inspired by the brain's efficiency, spiking neural networks (SNNs) have emerged as a viable alternative due to their event-driven nature and compatibility with neuromorphic chips. This work introduces a novel system that combines knowledge distillation and ensemble learning to bridge the performance gap between artificial neural networks (ANNs) and SNNs. A foundation AI model acts as a teacher network, guiding smaller student SNNs organized into an ensemble, called Spiking Neural Ensemble (SNE). SNE enables the disentanglement of the teacher's knowledge, allowing each student to specialize in predicting a distinct aspect of it, while processing the same input. The core innovation of SNE is the adaptive activation of a subset of SNN models of an ensemble, leveraging knowledge-distillation, enhanced with an informed-partitioning (disentanglement) of the teacher's feature space. By dynamically activating only a subset of these student SNNs, the system balances accuracy and energy efficiency, achieving substantial energy savings with minimal accuracy loss. Moreover, SNE is significantly more efficient than the teacher network, reducing computational requirements by up to 20x with only a 2% drop in accuracy on the CIFAR-10 dataset. This disentanglement procedure achieves an accuracy improvement of up to 2.4% on the CIFAR-10 dataset compared to other partitioning schemes. Finally, we comparatively analyze SNE performance under noisy conditions, demonstrating enhanced robustness compared to its ANN teacher. In summary, SNE offers a promising new direction for energy-constrained applications.
Adversarial dictionary learning for a robust analysis and modelling of spontaneous neuronal activity
Nov 05, 2019



The field of neuroscience is experiencing rapid growth in the complexity and quantity of the recorded neural activity allowing us unprecedented access to its dynamics in different brain areas. One of the major goals of neuroscience is to find interpretable descriptions of what the brain represents and computes by trying to explain complex phenomena in simple terms. Considering this task from the perspective of dimensionality reduction provides an entry point into principled mathematical techniques allowing us to discover these representations directly from experimental data, a key step to developing rich yet comprehensible models for brain function. In this work, we employ two real-world binary datasets describing the spontaneous neuronal activity of two laboratory mice over time, and we aim to their efficient low-dimensional representation. We develop an innovative, robust to noise, dictionary learning algorithm for the identification of patterns with synchronous activity and we also extend it to identify patterns within larger time windows. The results on the classification accuracy for the discrimination between the clean and the adversarial-noisy activation patterns obtained by an SVM classifier highlight the efficacy of the proposed scheme, and the visualization of the dictionary's distribution demonstrates the multifarious information that we obtain from it.
DysLexML: Screening Tool for Dyslexia Using Machine Learning
Mar 14, 2019
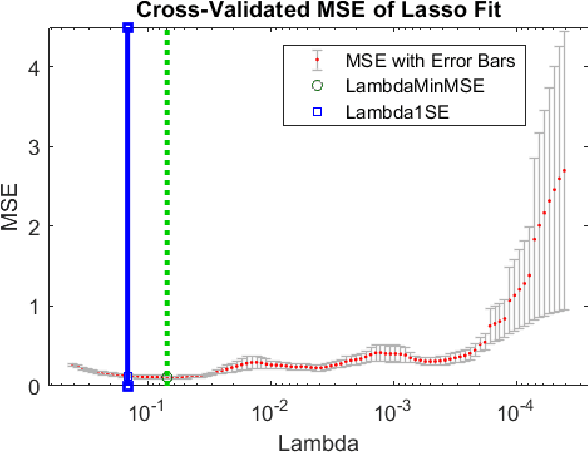
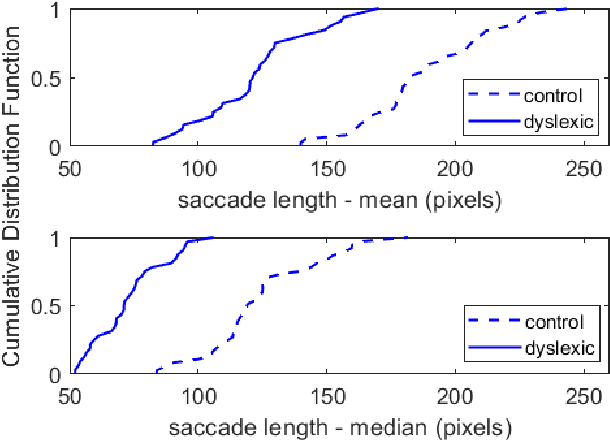
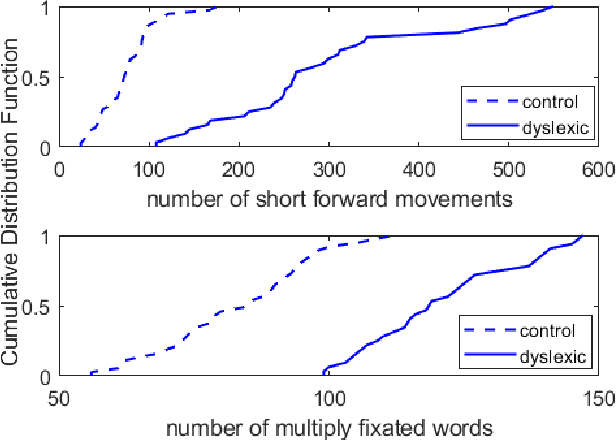
Eye movements during text reading can provide insights about reading disorders. Via eye-trackers, we can measure when, where and how eyes move with relation to the words they read. Machine Learning (ML) algorithms can decode this information and provide differential analysis. This work developed DysLexML, a screening tool for developmental dyslexia that applies various ML algorithms to analyze fixation points recorded via eye-tracking during silent reading of children. It comparatively evaluated its performance using measurements collected in a systematic field study with 69 native Greek speakers, children, 32 of which were diagnosed as dyslexic by the official governmental agency for diagnosing learning and reading difficulties in Greece. We examined a large set of features based on statistical properties of fixations and saccadic movements and identified the ones with prominent predictive power, performing dimensionality reduction. Specifically, DysLexML achieves its best performance using linear SVM, with an a accuracy of 97 %, with a small feature set, namely saccade length, number of short forward movements, and number of multiply fixated words. Furthermore, we analyzed the impact of noise on the fixation positions and showed that DysLexML is accurate and robust in the presence of noise. These encouraging results set the basis for developing screening tools in less controlled, larger-scale environments, with inexpensive eye-trackers, potentially reaching a larger population for early intervention.