 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnticipating Object State Changes
May 21, 2024Anticipating object state changes in images and videos is a challenging problem whose solution has important implications in vision-based scene understanding, automated monitoring systems, and action planning. In this work, we propose the first method for solving this problem. The proposed method predicts object state changes that will occur in the near future as a result of yet unseen human actions. To address this new problem, we propose a novel framework that integrates learnt visual features that represent the recent visual information, with natural language (NLP) features that represent past object state changes and actions. Leveraging the extensive and challenging Ego4D dataset which provides a large-scale collection of first-person perspective videos across numerous interaction scenarios, we introduce new curated annotation data for the object state change anticipation task (OSCA), noted as Ego4D-OSCA. An extensive experimental evaluation was conducted that demonstrates the efficacy of the proposed method in predicting object state changes in dynamic scenarios. The proposed work underscores the potential of integrating video and linguistic cues to enhance the predictive performance of video understanding systems. Moreover, it lays the groundwork for future research on the new task of object state change anticipation. The source code and the new annotation data (Ego4D-OSCA) will be made publicly available.
Fusing Domain-Specific Content from Large Language Models into Knowledge Graphs for Enhanced Zero Shot Object State Classification
Mar 25, 2024



Domain-specific knowledge can significantly contribute to addressing a wide variety of vision tasks. However, the generation of such knowledge entails considerable human labor and time costs. This study investigates the potential of Large Language Models (LLMs) in generating and providing domain-specific information through semantic embeddings. To achieve this, an LLM is integrated into a pipeline that utilizes Knowledge Graphs and pre-trained semantic vectors in the context of the Vision-based Zero-shot Object State Classification task. We thoroughly examine the behavior of the LLM through an extensive ablation study. Our findings reveal that the integration of LLM-based embeddings, in combination with general-purpose pre-trained embeddings, leads to substantial performance improvements. Drawing insights from this ablation study, we conduct a comparative analysis against competing models, thereby highlighting the state-of-the-art performance achieved by the proposed approach.
Leveraging Knowledge Graphs for Zero-Shot Object-agnostic State Classification
Jul 22, 2023



We investigate the problem of Object State Classification (OSC) as a zero-shot learning problem. Specifically, we propose the first Object-agnostic State Classification (OaSC) method that infers the state of a certain object without relying on the knowledge or the estimation of the object class. In that direction, we capitalize on Knowledge Graphs (KGs) for structuring and organizing knowledge, which, in combination with visual information, enable the inference of the states of objects in object/state pairs that have not been encountered in the method's training set. A series of experiments investigate the performance of the proposed method in various settings, against several hypotheses and in comparison with state of the art approaches for object attribute classification. The experimental results demonstrate that the knowledge of an object class is not decisive for the prediction of its state. Moreover, the proposed OaSC method outperforms existing methods in all datasets and benchmarks by a great margin.
Detecting Object States vs Detecting Objects: A New Dataset and a Quantitative Experimental Study
Dec 15, 2021
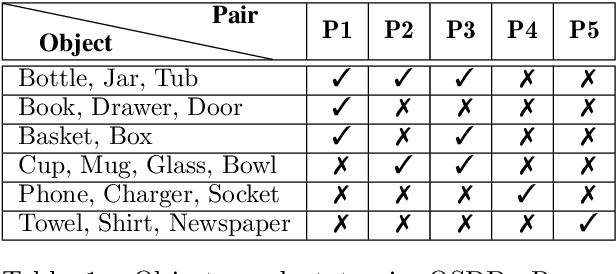

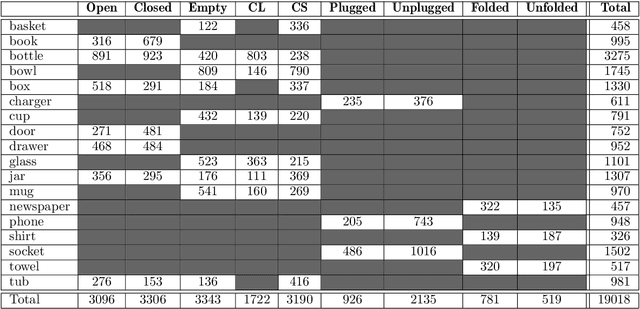
The detection of object states in images (State Detection - SD) is a problem of both theoretical and practical importance and it is tightly interwoven with other important computer vision problems, such as action recognition and affordance detection. It is also highly relevant to any entity that needs to reason and act in dynamic domains, such as robotic systems and intelligent agents. Despite its importance, up to now, the research on this problem has been limited. In this paper, we attempt a systematic study of the SD problem. First, we introduce the Object State Detection Dataset (OSDD), a new publicly available dataset consisting of more than 19,000 annotations for 18 object categories and 9 state classes. Second, using a standard deep learning framework used for Object Detection (OD), we conduct a number of appropriately designed experiments, towards an in-depth study of the behavior of the SD problem. This study enables the setup of a baseline on the performance of SD, as well as its relative performance in comparison to OD, in a variety of scenarios. Overall, the experimental outcomes confirm that SD is harder than OD and that tailored SD methods need to be developed for addressing effectively this significant problem.
Linguistic Cues of Deception in a Multilingual April Fools' Day Context
Nov 09, 2021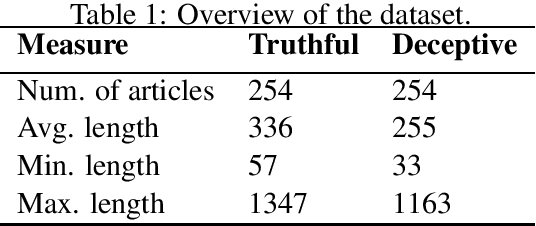
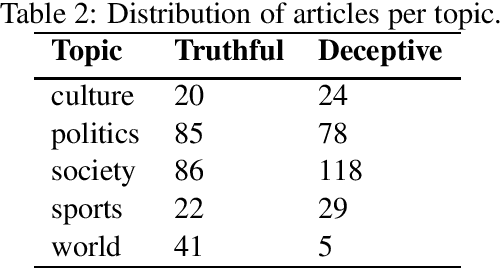

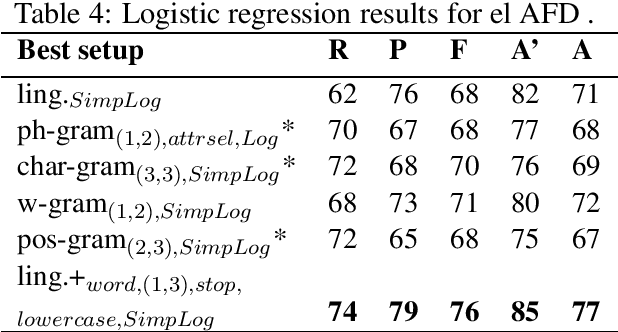
In this work we consider the collection of deceptive April Fools' Day(AFD) news articles as a useful addition in existing datasets for deception detection tasks. Such collections have an established ground truth and are relatively easy to construct across languages. As a result, we introduce a corpus that includes diachronic AFD and normal articles from Greek newspapers and news websites. On top of that, we build a rich linguistic feature set, and analyze and compare its deception cues with the only AFD collection currently available, which is in English. Following a current research thread, we also discuss the individualism/collectivism dimension in deception with respect to these two datasets. Lastly, we build classifiers by testing various monolingual and crosslingual settings. The results showcase that AFD datasets can be helpful in deception detection studies, and are in alignment with the observations of other deception detection works.
Deception detection in text and its relation to the cultural dimension of individualism/collectivism
May 26, 2021



Deception detection is a task with many applications both in direct physical and in computer-mediated communication. Our focus is on automatic deception detection in text across cultures. We view culture through the prism of the individualism/collectivism dimension and we approximate culture by using country as a proxy. Having as a starting point recent conclusions drawn from the social psychology discipline, we explore if differences in the usage of specific linguistic features of deception across cultures can be confirmed and attributed to norms in respect to the individualism/collectivism divide. We also investigate if a universal feature set for cross-cultural text deception detection tasks exists. We evaluate the predictive power of different feature sets and approaches. We create culture/language-aware classifiers by experimenting with a wide range of n-gram features based on phonology, morphology and syntax, other linguistic cues like word and phoneme counts, pronouns use, etc., and token embeddings. We conducted our experiments over 11 datasets from 5 languages i.e., English, Dutch, Russian, Spanish and Romanian, from six countries (US, Belgium, India, Russia, Mexico and Romania), and we applied two classification methods i.e, logistic regression and fine-tuned BERT models. The results showed that our task is fairly complex and demanding. There are indications that some linguistic cues of deception have cultural origins, and are consistent in the context of diverse domains and dataset settings for the same language. This is more evident for the usage of pronouns and the expression of sentiment in deceptive language. The results of this work show that the automatic deception detection across cultures and languages cannot be handled in a unified manner, and that such approaches should be augmented with knowledge about cultural differences and the domains of interest.
A Review on Intelligent Object Perception Methods Combining Knowledge-based Reasoning and Machine Learning
Dec 26, 2019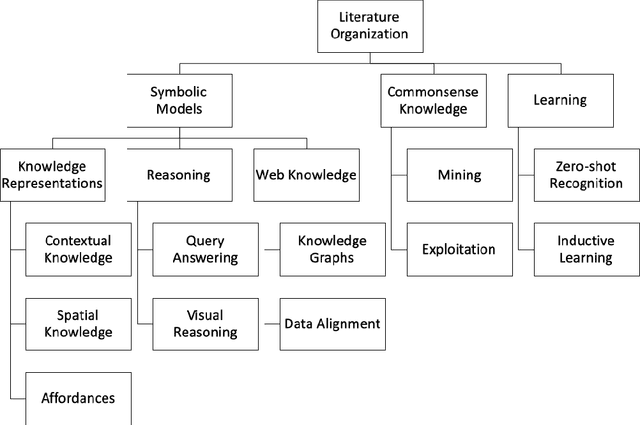
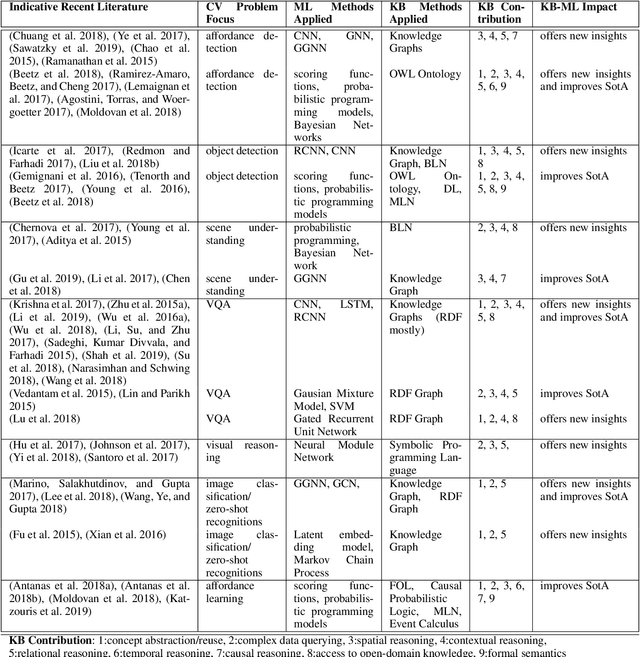
Object perception is a fundamental sub-field of Computer Vision, covering a multitude of individual areas and having contributed high-impact results. While Machine Learning has been traditionally applied to address related problems, recent works also seek ways to integrate knowledge engineering in order to expand the level of intelligence of the visual interpretation of objects, their properties and their relations with their environment. In this paper, we attempt a systematic investigation of how knowledge-based methods contribute to diverse object perception tasks. We review the latest achievements and identify prominent research directions.
LD-SDS: Towards an Expressive Spoken Dialogue System based on Linked-Data
Oct 09, 2017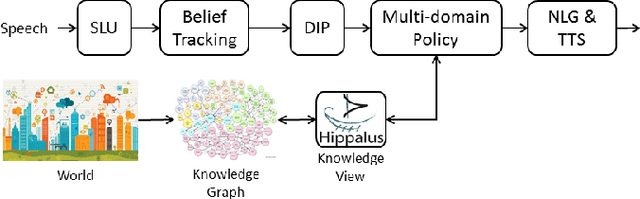
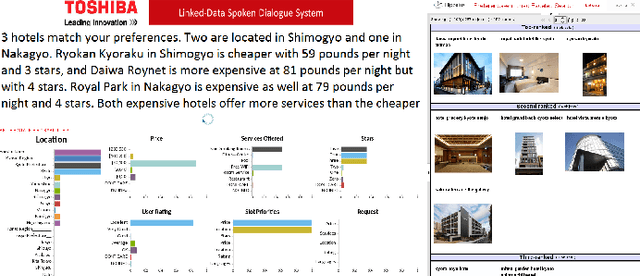

In this work we discuss the related challenges and describe an approach towards the fusion of state-of-the-art technologies from the Spoken Dialogue Systems (SDS) and the Semantic Web and Information Retrieval domains. We envision a dialogue system named LD-SDS that will support advanced, expressive, and engaging user requests, over multiple, complex, rich, and open-domain data sources that will leverage the wealth of the available Linked Data. Specifically, we focus on: a) improving the identification, disambiguation and linking of entities occurring in data sources and user input; b) offering advanced query services for exploiting the semantics of the data, with reasoning and exploratory capabilities; and c) expanding the typical information seeking dialogue model (slot filling) to better reflect real-world conversational search scenarios.
An Event Calculus Production Rule System for Reasoning in Dynamic and Uncertain Domains
Dec 16, 2015
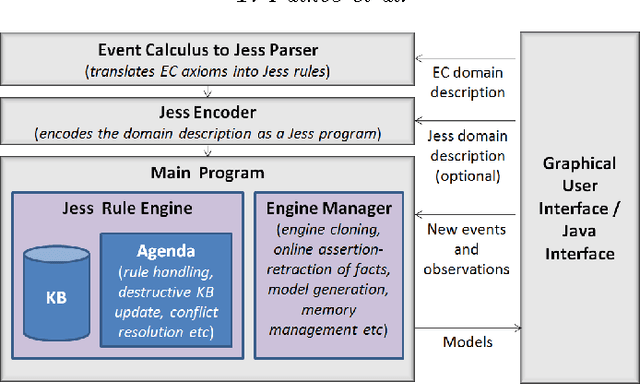

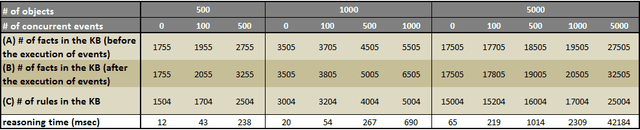
Action languages have emerged as an important field of Knowledge Representation for reasoning about change and causality in dynamic domains. This article presents Cerbere, a production system designed to perform online causal, temporal and epistemic reasoning based on the Event Calculus. The framework implements the declarative semantics of the underlying logic theories in a forward-chaining rule-based reasoning system, coupling the high expressiveness of its formalisms with the efficiency of rule-based systems. To illustrate its applicability, we present both the modeling of benchmark problems in the field, as well as its utilization in the challenging domain of smart spaces. A hybrid framework that combines logic-based with probabilistic reasoning has been developed, that aims to accommodate activity recognition and monitoring tasks in smart spaces. Under consideration in Theory and Practice of Logic Programming (TPLP)
* Under consideration in Theory and Practice of Logic Programming (TPLP)