 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNLP for The Greek Language: A Longer Survey
Aug 20, 2024English language is in the spotlight of the Natural Language Processing (NLP) community with other languages, like Greek, lagging behind in terms of offered methods, tools and resources. Due to the increasing interest in NLP, in this paper we try to condense research efforts for the automatic processing of Greek language covering the last three decades. In particular, we list and briefly discuss related works, resources and tools, categorized according to various processing layers and contexts. We are not restricted to the modern form of Greek language but also cover Ancient Greek and various Greek dialects. This survey can be useful for researchers and students interested in NLP tasks, Information Retrieval and Knowledge Management for the Greek language.
Validating ChatGPT Facts through RDF Knowledge Graphs and Sentence Similarity
Nov 17, 2023Since ChatGPT offers detailed responses without justifications, and erroneous facts even for popular persons, events and places, in this paper we present a novel pipeline that retrieves the response of ChatGPT in RDF and tries to validate the ChatGPT facts using one or more RDF Knowledge Graphs (KGs). To this end we leverage DBpedia and LODsyndesis (an aggregated Knowledge Graph that contains 2 billion triples from 400 RDF KGs of many domains) and short sentence embeddings, and introduce an algorithm that returns the more relevant triple(s) accompanied by their provenance and a confidence score. This enables the validation of ChatGPT responses and their enrichment with justifications and provenance. To evaluate this service (such services in general), we create an evaluation benchmark that includes 2,000 ChatGPT facts; specifically 1,000 facts for famous Greek Persons, 500 facts for popular Greek Places, and 500 facts for Events related to Greece. The facts were manually labelled (approximately 73% of ChatGPT facts were correct and 27% of facts were erroneous). The results are promising; indicatively for the whole benchmark, we managed to verify the 85.3% of the correct facts of ChatGPT and to find the correct answer for the 58% of the erroneous ChatGPT facts.
Using Multiple RDF Knowledge Graphs for Enriching ChatGPT Responses
Apr 12, 2023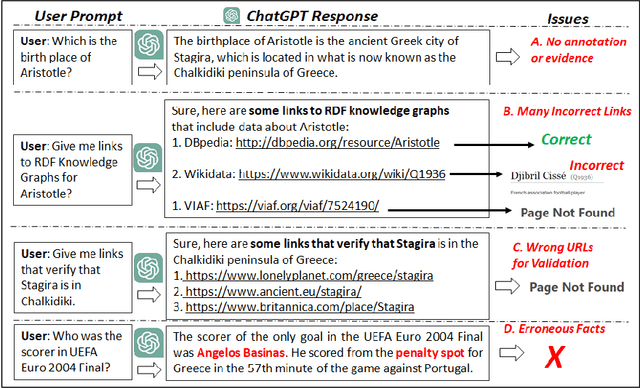
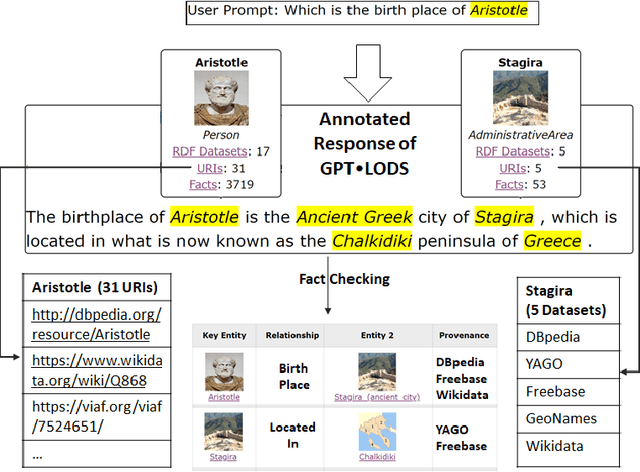
There is a recent trend for using the novel Artificial Intelligence ChatGPT chatbox, which provides detailed responses and articulate answers across many domains of knowledge. However, in many cases it returns plausible-sounding but incorrect or inaccurate responses, whereas it does not provide evidence. Therefore, any user has to further search for checking the accuracy of the answer or/and for finding more information about the entities of the response. At the same time there is a high proliferation of RDF Knowledge Graphs (KGs) over any real domain, that offer high quality structured data. For enabling the combination of ChatGPT and RDF KGs, we present a research prototype, called GPToLODS, which is able to enrich any ChatGPT response with more information from hundreds of RDF KGs. In particular, it identifies and annotates each entity of the response with statistics and hyperlinks to LODsyndesis KG (which contains integrated data from 400 RDF KGs and over 412 million entities). In this way, it is feasible to enrich the content of entities and to perform fact checking and validation for the facts of the response at real time.
CS563-QA: A Collection for Evaluating Question Answering Systems
Jul 02, 2019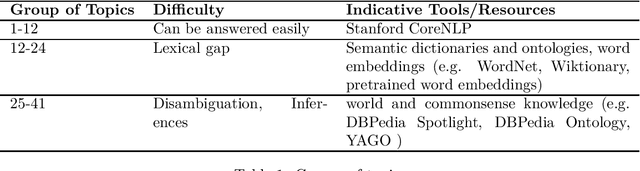



Question Answering (QA) is a challenging topic since it requires tackling the various difficulties of natural language understanding. Since evaluation is important not only for identifying the strong and weak points of the various techniques for QA, but also for facilitating the inception of new methods and techniques, in this paper we present a collection for evaluating QA methods over free text that we have created. Although it is a small collection, it contains cases of increasing difficulty, therefore it has an educational value and it can be used for rapid evaluation of QA systems.
LD-SDS: Towards an Expressive Spoken Dialogue System based on Linked-Data
Oct 09, 2017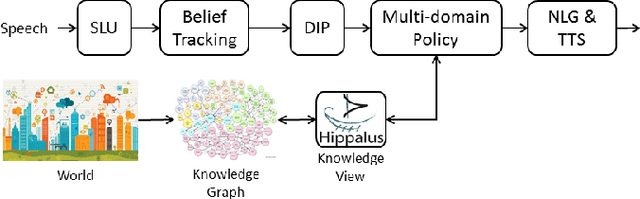
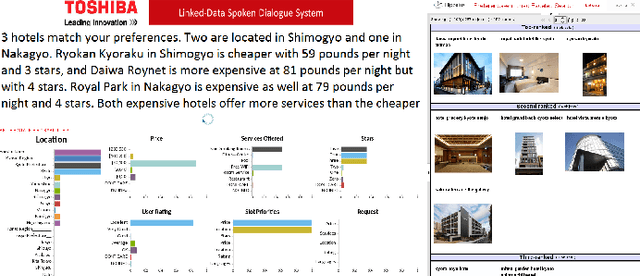

In this work we discuss the related challenges and describe an approach towards the fusion of state-of-the-art technologies from the Spoken Dialogue Systems (SDS) and the Semantic Web and Information Retrieval domains. We envision a dialogue system named LD-SDS that will support advanced, expressive, and engaging user requests, over multiple, complex, rich, and open-domain data sources that will leverage the wealth of the available Linked Data. Specifically, we focus on: a) improving the identification, disambiguation and linking of entities occurring in data sources and user input; b) offering advanced query services for exploiting the semantics of the data, with reasoning and exploratory capabilities; and c) expanding the typical information seeking dialogue model (slot filling) to better reflect real-world conversational search scenarios.
Tasks that Require, or can Benefit from, Matching Blank Nodes
Oct 30, 2014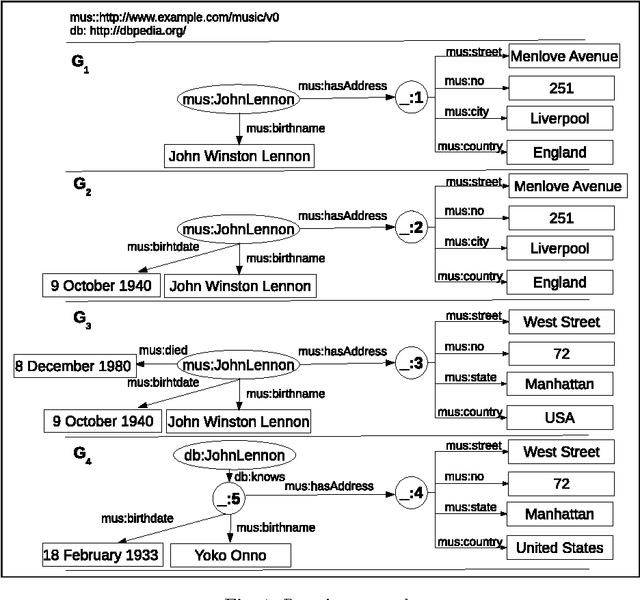

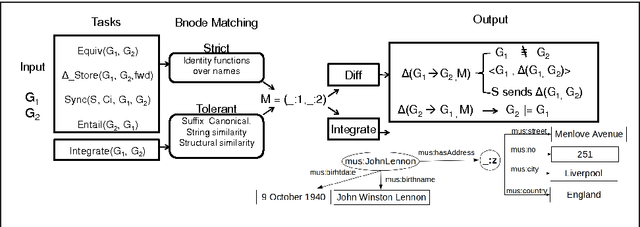
In various domains and cases, we observe the creation and usage of information elements which are unnamed. Such elements do not have a name, or may have a name that is not externally referable (usually meaningless and not persistent over time). This paper discusses why we will never `escape' from the problem of having to construct mappings between such unnamed elements in information systems. Since unnamed elements nowadays occur very often in the framework of the Semantic Web and Linked Data as blank nodes, the paper describes scenarios that can benefit from methods that compute mappings between the unnamed elements. For each scenario, the corresponding bnode matching problem is formally defined. Based on this analysis, we try to reach to more a general formulation of the problem, which can be useful for guiding the required technological advances. To this end, the paper finally discusses methods to realize blank node matching, the implementations that exist, and identifies open issues and challenges.