 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHealth Misinformation in Social Networks: A Survey of IT Approaches
Oct 24, 2024



In this paper, we present a comprehensive survey on the pervasive issue of medical misinformation in social networks from the perspective of information technology. The survey aims at providing a systematic review of related research and helping researchers and practitioners navigate through this fast-changing field. Specifically, we first present manual and automatic approaches for fact-checking. We then explore fake news detection methods, using content, propagation features, or source features, as well as mitigation approaches for countering the spread of misinformation. We also provide a detailed list of several datasets on health misinformation and of publicly available tools. We conclude the survey with a discussion on the open challenges and future research directions in the battle against health misinformation.
Linguistic Cues of Deception in a Multilingual April Fools' Day Context
Nov 09, 2021

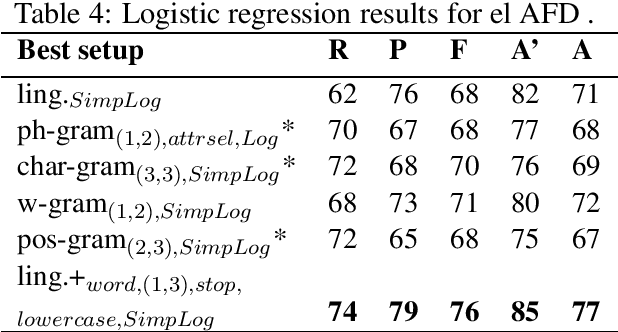
In this work we consider the collection of deceptive April Fools' Day(AFD) news articles as a useful addition in existing datasets for deception detection tasks. Such collections have an established ground truth and are relatively easy to construct across languages. As a result, we introduce a corpus that includes diachronic AFD and normal articles from Greek newspapers and news websites. On top of that, we build a rich linguistic feature set, and analyze and compare its deception cues with the only AFD collection currently available, which is in English. Following a current research thread, we also discuss the individualism/collectivism dimension in deception with respect to these two datasets. Lastly, we build classifiers by testing various monolingual and crosslingual settings. The results showcase that AFD datasets can be helpful in deception detection studies, and are in alignment with the observations of other deception detection works.
Deception detection in text and its relation to the cultural dimension of individualism/collectivism
May 26, 2021



Deception detection is a task with many applications both in direct physical and in computer-mediated communication. Our focus is on automatic deception detection in text across cultures. We view culture through the prism of the individualism/collectivism dimension and we approximate culture by using country as a proxy. Having as a starting point recent conclusions drawn from the social psychology discipline, we explore if differences in the usage of specific linguistic features of deception across cultures can be confirmed and attributed to norms in respect to the individualism/collectivism divide. We also investigate if a universal feature set for cross-cultural text deception detection tasks exists. We evaluate the predictive power of different feature sets and approaches. We create culture/language-aware classifiers by experimenting with a wide range of n-gram features based on phonology, morphology and syntax, other linguistic cues like word and phoneme counts, pronouns use, etc., and token embeddings. We conducted our experiments over 11 datasets from 5 languages i.e., English, Dutch, Russian, Spanish and Romanian, from six countries (US, Belgium, India, Russia, Mexico and Romania), and we applied two classification methods i.e, logistic regression and fine-tuned BERT models. The results showed that our task is fairly complex and demanding. There are indications that some linguistic cues of deception have cultural origins, and are consistent in the context of diverse domains and dataset settings for the same language. This is more evident for the usage of pronouns and the expression of sentiment in deceptive language. The results of this work show that the automatic deception detection across cultures and languages cannot be handled in a unified manner, and that such approaches should be augmented with knowledge about cultural differences and the domains of interest.
LD-SDS: Towards an Expressive Spoken Dialogue System based on Linked-Data
Oct 09, 2017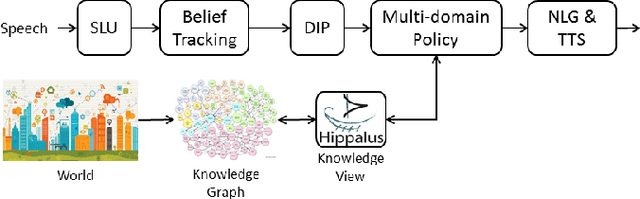
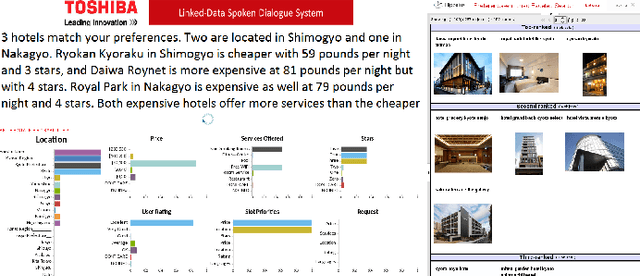

In this work we discuss the related challenges and describe an approach towards the fusion of state-of-the-art technologies from the Spoken Dialogue Systems (SDS) and the Semantic Web and Information Retrieval domains. We envision a dialogue system named LD-SDS that will support advanced, expressive, and engaging user requests, over multiple, complex, rich, and open-domain data sources that will leverage the wealth of the available Linked Data. Specifically, we focus on: a) improving the identification, disambiguation and linking of entities occurring in data sources and user input; b) offering advanced query services for exploiting the semantics of the data, with reasoning and exploratory capabilities; and c) expanding the typical information seeking dialogue model (slot filling) to better reflect real-world conversational search scenarios.