 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVocal effort modeling in neural TTS for improving the intelligibility of synthetic speech in noise
Mar 29, 2022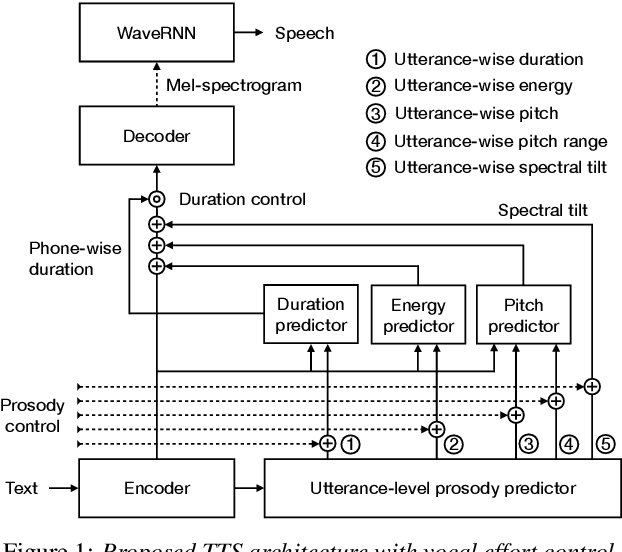
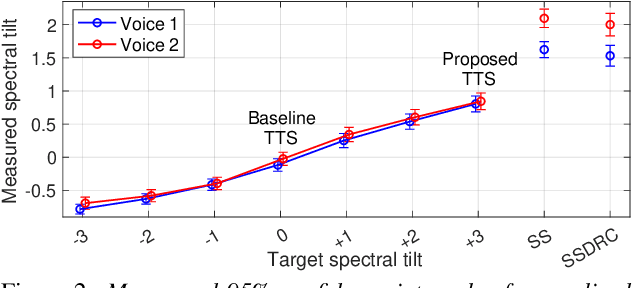
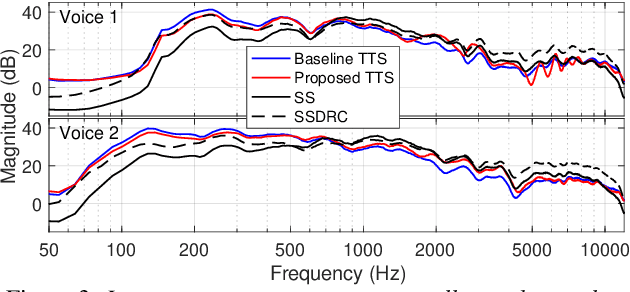
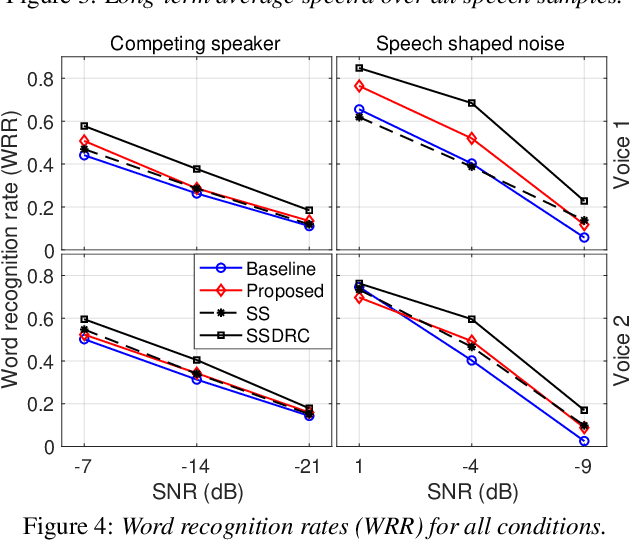
We present a neural text-to-speech (TTS) method that models natural vocal effort variation to improve the intelligibility of synthetic speech in the presence of noise. The method consists of first measuring the spectral tilt of unlabeled conventional speech data, and then conditioning a neural TTS model with normalized spectral tilt among other prosodic factors. Changing the spectral tilt parameter and keeping other prosodic factors unchanged enables effective vocal effort control at synthesis time independent of other prosodic factors. By extrapolation of the spectral tilt values beyond what has been seen in the original data, we can generate speech with high vocal effort levels, thus improving the intelligibility of speech in the presence of masking noise. We evaluate the intelligibility and quality of normal speech and speech with increased vocal effort in the presence of various masking noise conditions, and compare these to well-known speech intelligibility-enhancing algorithms. The evaluations show that the proposed method can improve the intelligibility of synthetic speech with little loss in speech quality.
Combining speakers of multiple languages to improve quality of neural voices
Aug 17, 2021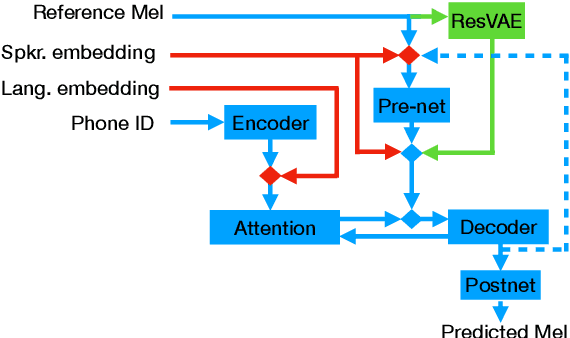

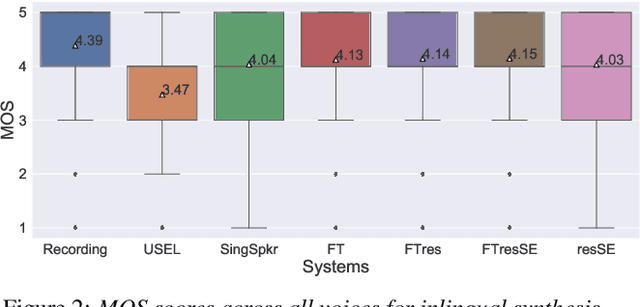
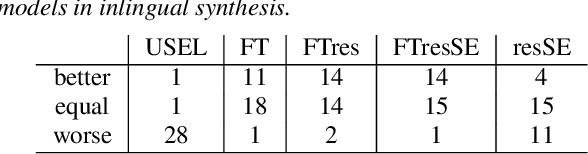
In this work, we explore multiple architectures and training procedures for developing a multi-speaker and multi-lingual neural TTS system with the goals of a) improving the quality when the available data in the target language is limited and b) enabling cross-lingual synthesis. We report results from a large experiment using 30 speakers in 8 different languages across 15 different locales. The system is trained on the same amount of data per speaker. Compared to a single-speaker model, when the suggested system is fine tuned to a speaker, it produces significantly better quality in most of the cases while it only uses less than $40\%$ of the speaker's data used to build the single-speaker model. In cross-lingual synthesis, on average, the generated quality is within $80\%$ of native single-speaker models, in terms of Mean Opinion Score.
Enhancing Speech Intelligibility in Text-To-Speech Synthesis using Speaking Style Conversion
Aug 13, 2020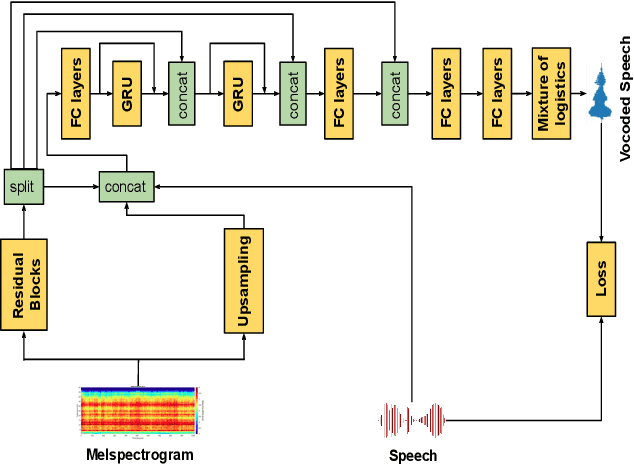
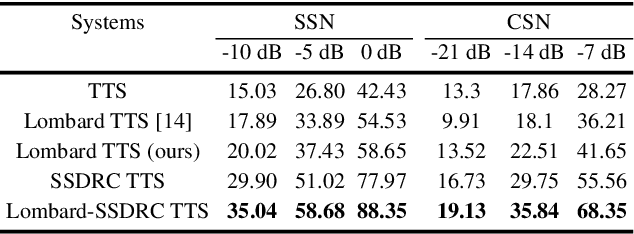
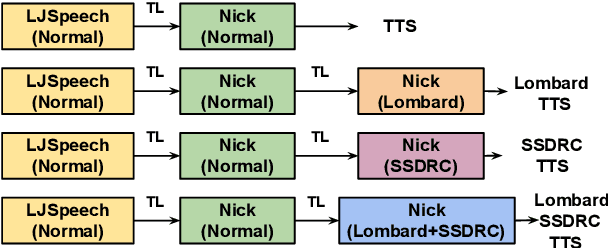
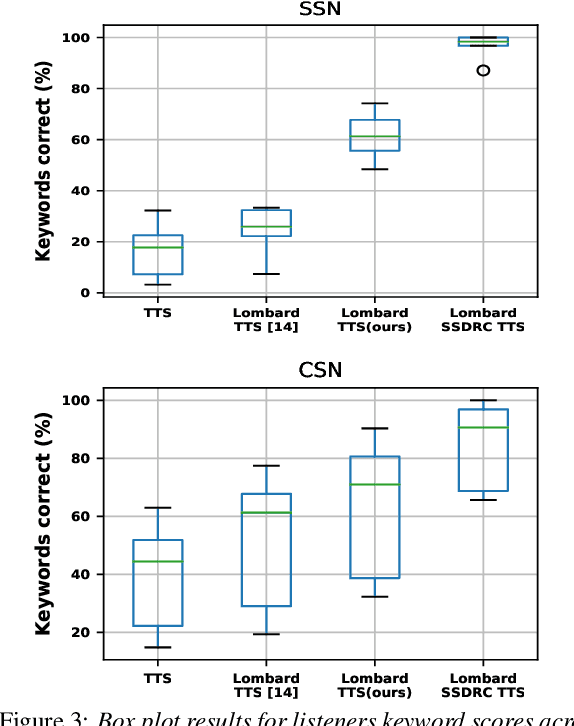
The increased adoption of digital assistants makes text-to-speech (TTS) synthesis systems an indispensable feature of modern mobile devices. It is hence desirable to build a system capable of generating highly intelligible speech in the presence of noise. Past studies have investigated style conversion in TTS synthesis, yet degraded synthesized quality often leads to worse intelligibility. To overcome such limitations, we proposed a novel transfer learning approach using Tacotron and WaveRNN based TTS synthesis. The proposed speech system exploits two modification strategies: (a) Lombard speaking style data and (b) Spectral Shaping and Dynamic Range Compression (SSDRC) which has been shown to provide high intelligibility gains by redistributing the signal energy on the time-frequency domain. We refer to this extension as Lombard-SSDRC TTS system. Intelligibility enhancement as quantified by the Intelligibility in Bits (SIIB-Gauss) measure shows that the proposed Lombard-SSDRC TTS system shows significant relative improvement between 110% and 130% in speech-shaped noise (SSN), and 47% to 140% in competing-speaker noise (CSN) against the state-of-the-art TTS approach. Additional subjective evaluation shows that Lombard-SSDRC TTS successfully increases the speech intelligibility with relative improvement of 455% for SSN and 104% for CSN in median keyword correction rate compared to the baseline TTS method.
Speaker Conditional WaveRNN: Towards Universal Neural Vocoder for Unseen Speaker and Recording Conditions
Aug 09, 2020
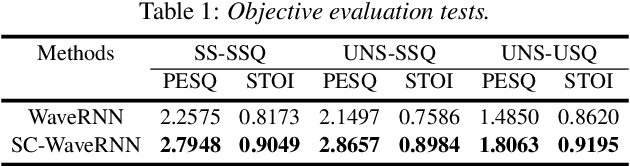
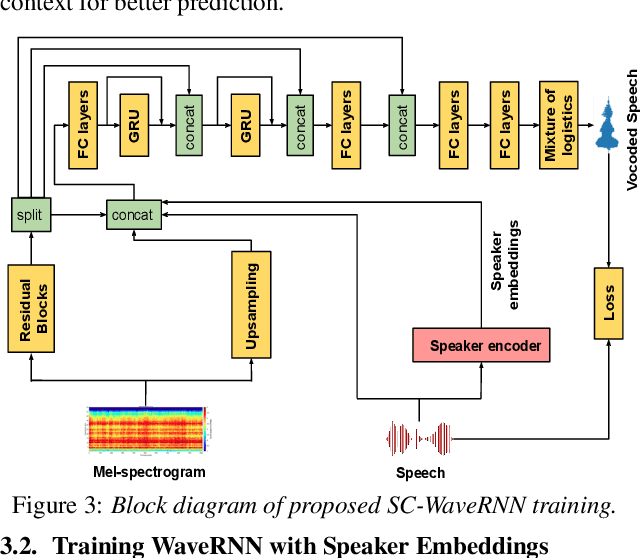
Recent advancements in deep learning led to human-level performance in single-speaker speech synthesis. However, there are still limitations in terms of speech quality when generalizing those systems into multiple-speaker models especially for unseen speakers and unseen recording qualities. For instance, conventional neural vocoders are adjusted to the training speaker and have poor generalization capabilities to unseen speakers. In this work, we propose a variant of WaveRNN, referred to as speaker conditional WaveRNN (SC-WaveRNN). We target towards the development of an efficient universal vocoder even for unseen speakers and recording conditions. In contrast to standard WaveRNN, SC-WaveRNN exploits additional information given in the form of speaker embeddings. Using publicly-available data for training, SC-WaveRNN achieves significantly better performance over baseline WaveRNN on both subjective and objective metrics. In MOS, SC-WaveRNN achieves an improvement of about 23% for seen speaker and seen recording condition and up to 95% for unseen speaker and unseen condition. Finally, we extend our work by implementing a multi-speaker text-to-speech (TTS) synthesis similar to zero-shot speaker adaptation. In terms of performance, our system has been preferred over the baseline TTS system by 60% over 15.5% and by 60.9% over 32.6%, for seen and unseen speakers, respectively.
Audiovisual Speech Synthesis using Tacotron2
Aug 03, 2020



Audiovisual speech synthesis is the problem of synthesizing a talking face while maximizing the coherency of the acoustic and visual speech. In this paper, we propose and compare two audiovisual speech synthesis systems for 3D face models. The first system is the AVTacotron2, which is an end-to-end text-to-audiovisual speech synthesizer based on the Tacotron2 architecture. AVTacotron2 converts a sequence of phonemes representing the sentence to synthesize into a sequence of acoustic features and the corresponding controllers of a face model. The output acoustic features are used to condition a WaveRNN to reconstruct the speech waveform, and the output facial controllers are used to generate the corresponding video of the talking face. The second audiovisual speech synthesis system is modular, where acoustic speech is synthesized from text using the traditional Tacotron2. The reconstructed acoustic speech signal is then used to drive the facial controls of the face model using an independently trained audio-to-facial-animation neural network. We further condition both the end-to-end and modular approaches on emotion embeddings that encode the required prosody to generate emotional audiovisual speech. We analyze the performance of the two systems and compare them to the ground truth videos using subjective evaluation tests. The end-to-end and modular systems are able to synthesize close to human-like audiovisual speech with mean opinion scores (MOS) of 4.1 and 3.9, respectively, compared to a MOS of 4.1 for the ground truth generated from professionally recorded videos. While the end-to-end system gives a better overall quality, the modular approach is more flexible and the quality of acoustic speech and visual speech synthesis is almost independent of each other.
Cumulant GAN
Jun 11, 2020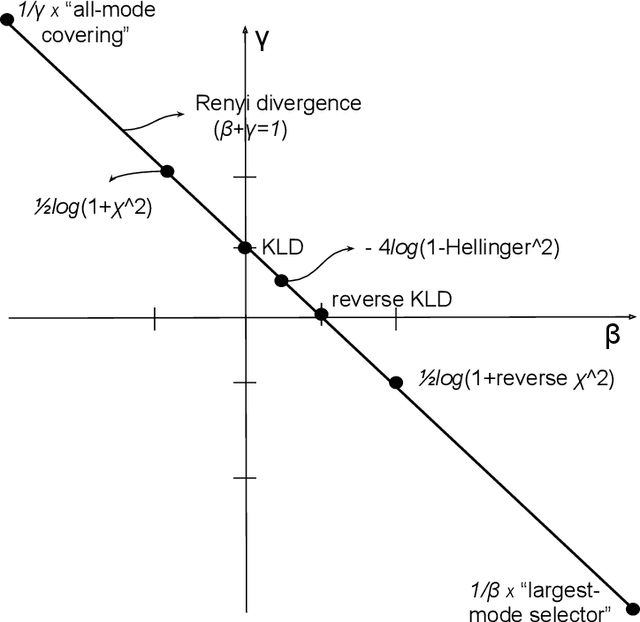
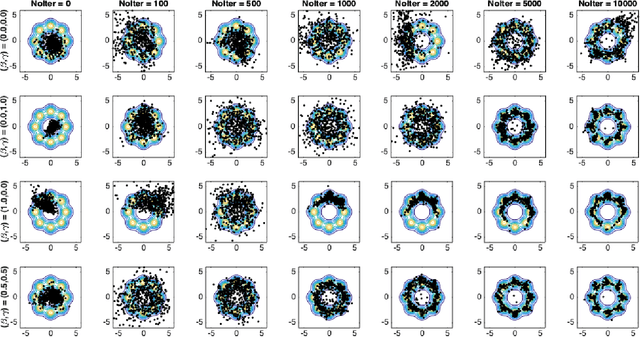
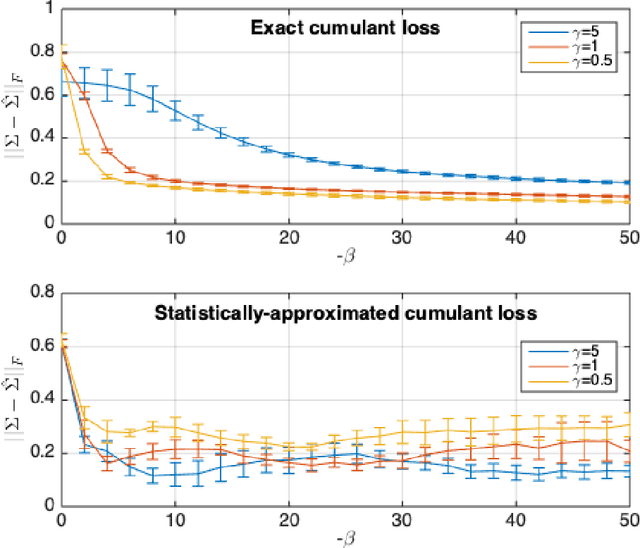
Despite the continuous improvements of Generative Adversarial Networks (GANs), stability and performance challenges still remain. In this work, we propose a novel loss function for GAN training aiming both for deeper theoretical understanding and improved performance of the underlying optimization problem. The new loss function is based on cumulant generating functions and relies on a recently-derived variational formula. We show that the corresponding optimization is equivalent to R\'enyi divergence minimization, thus offering a (partially) unified perspective of GAN losses: the R\'enyi family encompasses Kullback-Leibler divergence (KLD), reverse KLD, Hellinger distance and $\chi^2$-divergence. Wasserstein loss function is also included in the proposed cumulant GAN formulation. In terms of stability, we rigorously prove the convergence of the gradient descent algorithm for linear generator and linear discriminator for Gaussian distributions. Moreover, we numerically show that synthetic image generation trained on CIFAR-10 dataset is substantially improved in terms of inception score when weaker discriminators are considered.
A non-causal FFTNet architecture for speech enhancement
Jun 08, 2020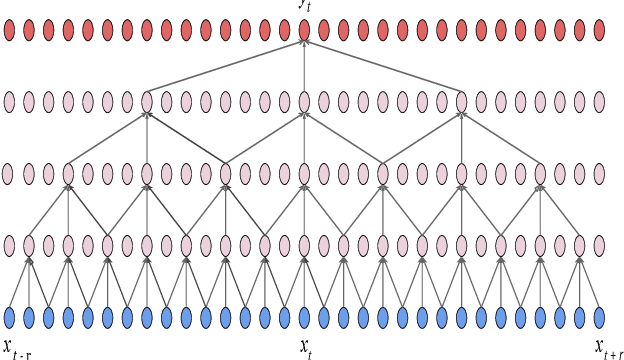
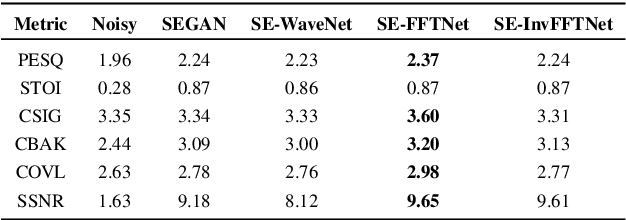
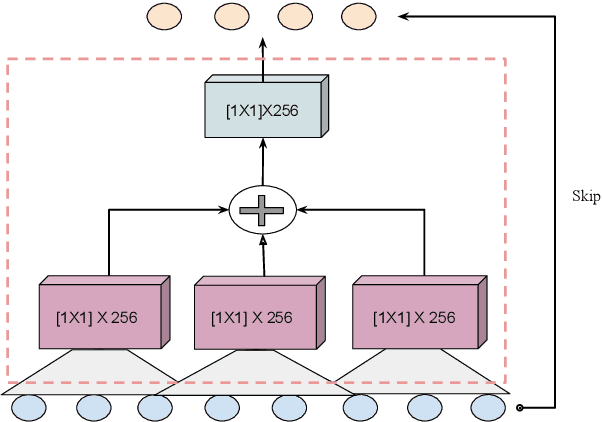

In this paper, we suggest a new parallel, non-causal and shallow waveform domain architecture for speech enhancement based on FFTNet, a neural network for generating high quality audio waveform. In contrast to other waveform based approaches like WaveNet, FFTNet uses an initial wide dilation pattern. Such an architecture better represents the long term correlated structure of speech in the time domain, where noise is usually highly non-correlated, and therefore it is suitable for waveform domain based speech enhancement. To further strengthen this feature of FFTNet, we suggest a non-causal FFTNet architecture, where the present sample in each layer is estimated from the past and future samples of the previous layer. By suggesting a shallow network and applying non-causality within certain limits, the suggested FFTNet for speech enhancement (SE-FFTNet) uses much fewer parameters compared to other neural network based approaches for speech enhancement like WaveNet and SEGAN. Specifically, the suggested network has considerably reduced model parameters: 32% fewer compared to WaveNet and 87% fewer compared to SEGAN. Finally, based on subjective and objective metrics, SE-FFTNet outperforms WaveNet in terms of enhanced signal quality, while it provides equally good performance as SEGAN. A Tensorflow implementation of the architecture is provided at 1 .
Maximum Voiced Frequency Estimation: Exploiting Amplitude and Phase Spectra
May 31, 2020
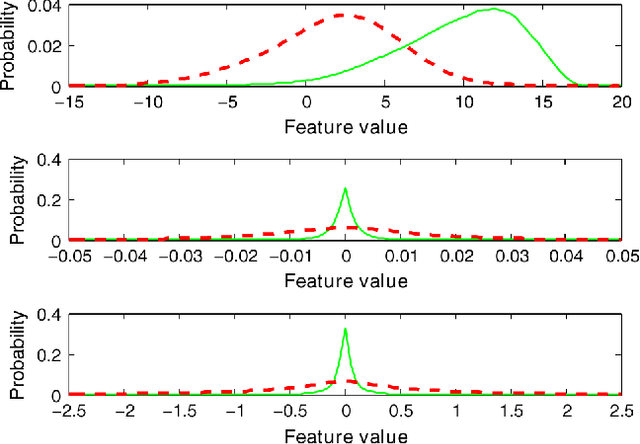
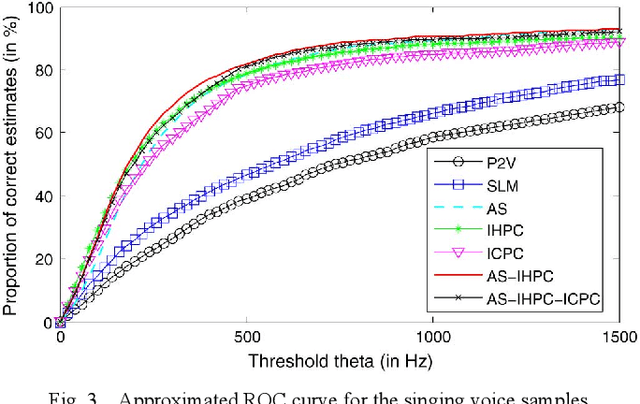
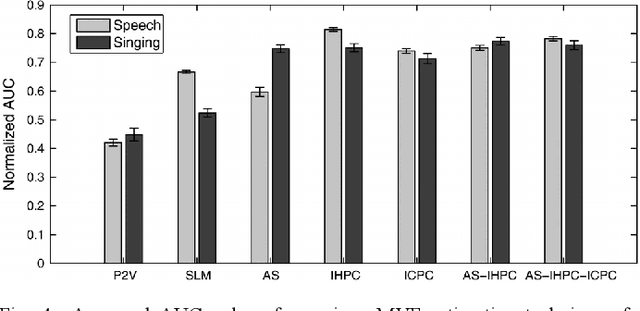
Maximum Voiced Frequency (MVF) is used in various speech models as the spectral boundary separating periodic and aperiodic components during the production of voiced sounds. Recent studies have shown that its proper estimation and modeling enhance the quality of statistical parametric speech synthesizers. Contrastingly, these same methods of MVF estimation have been reported to degrade the performance of singing voice synthesizers. This paper proposes a new approach for MVF estimation which exploits both amplitude and phase spectra. It is shown that phase conveys relevant information about the harmonicity of the voice signal, and that it can be jointly used with features derived from the amplitude spectrum. This information is further integrated into a maximum likelihood criterion which provides a decision about the MVF estimate. The proposed technique is compared to two state-of-the-art methods, and shows a superior performance in both objective and subjective evaluations. Perceptual tests indicate a drastic improvement in high-pitched voices.
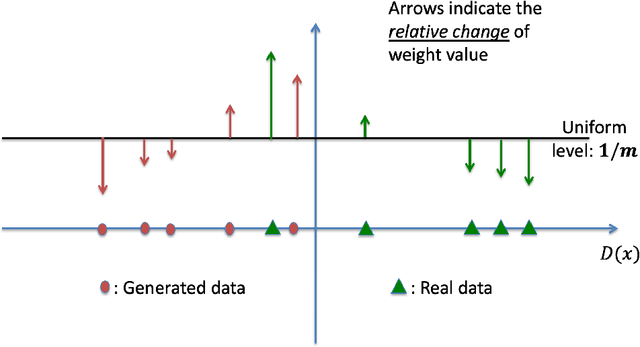
Training Generative Adversarial Networks with Weights
Nov 06, 2018
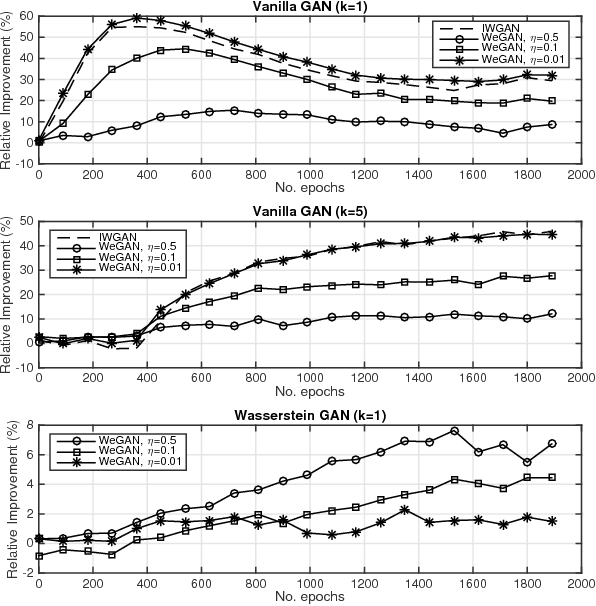
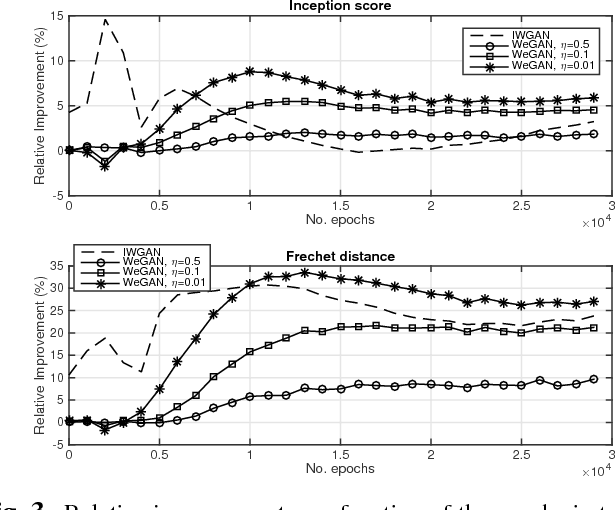
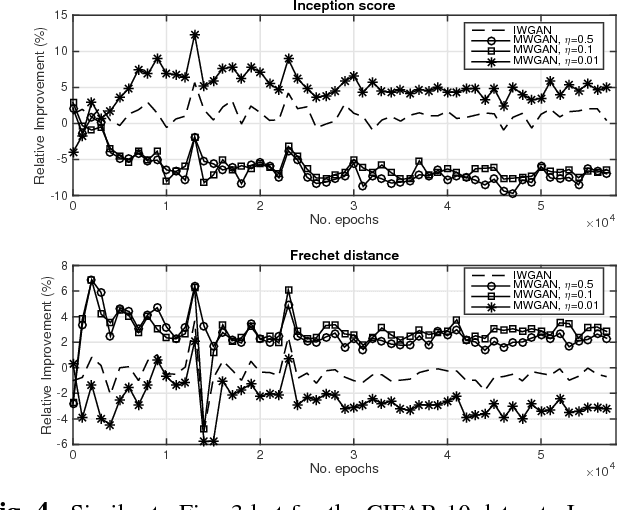
The impressive success of Generative Adversarial Networks (GANs) is often overshadowed by the difficulties in their training. Despite the continuous efforts and improvements, there are still open issues regarding their convergence properties. In this paper, we propose a simple training variation where suitable weights are defined and assist the training of the Generator. We provide theoretical arguments why the proposed algorithm is better than the baseline training in the sense of speeding up the training process and of creating a stronger Generator. Performance results showed that the new algorithm is more accurate in both synthetic and image datasets resulting in improvements ranging between 5% and 50%.
LD-SDS: Towards an Expressive Spoken Dialogue System based on Linked-Data
Oct 09, 2017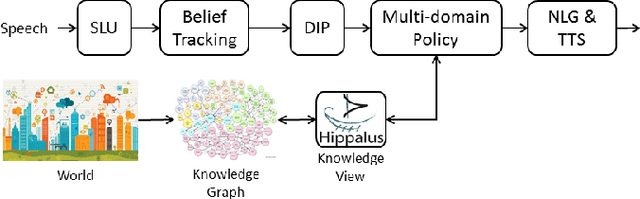
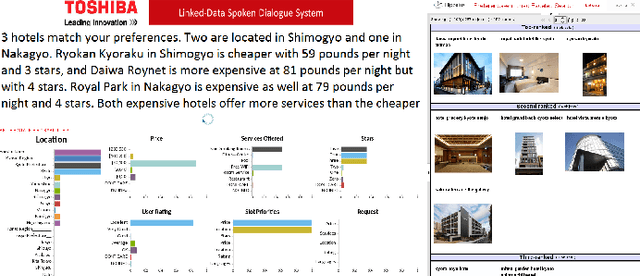

In this work we discuss the related challenges and describe an approach towards the fusion of state-of-the-art technologies from the Spoken Dialogue Systems (SDS) and the Semantic Web and Information Retrieval domains. We envision a dialogue system named LD-SDS that will support advanced, expressive, and engaging user requests, over multiple, complex, rich, and open-domain data sources that will leverage the wealth of the available Linked Data. Specifically, we focus on: a) improving the identification, disambiguation and linking of entities occurring in data sources and user input; b) offering advanced query services for exploiting the semantics of the data, with reasoning and exploratory capabilities; and c) expanding the typical information seeking dialogue model (slot filling) to better reflect real-world conversational search scenarios.