 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAudiovisual Speech Synthesis using Tacotron2
Aug 03, 2020



Audiovisual speech synthesis is the problem of synthesizing a talking face while maximizing the coherency of the acoustic and visual speech. In this paper, we propose and compare two audiovisual speech synthesis systems for 3D face models. The first system is the AVTacotron2, which is an end-to-end text-to-audiovisual speech synthesizer based on the Tacotron2 architecture. AVTacotron2 converts a sequence of phonemes representing the sentence to synthesize into a sequence of acoustic features and the corresponding controllers of a face model. The output acoustic features are used to condition a WaveRNN to reconstruct the speech waveform, and the output facial controllers are used to generate the corresponding video of the talking face. The second audiovisual speech synthesis system is modular, where acoustic speech is synthesized from text using the traditional Tacotron2. The reconstructed acoustic speech signal is then used to drive the facial controls of the face model using an independently trained audio-to-facial-animation neural network. We further condition both the end-to-end and modular approaches on emotion embeddings that encode the required prosody to generate emotional audiovisual speech. We analyze the performance of the two systems and compare them to the ground truth videos using subjective evaluation tests. The end-to-end and modular systems are able to synthesize close to human-like audiovisual speech with mean opinion scores (MOS) of 4.1 and 3.9, respectively, compared to a MOS of 4.1 for the ground truth generated from professionally recorded videos. While the end-to-end system gives a better overall quality, the modular approach is more flexible and the quality of acoustic speech and visual speech synthesis is almost independent of each other.
Speaker-Independent Speech-Driven Visual Speech Synthesis using Domain-Adapted Acoustic Models
May 15, 2019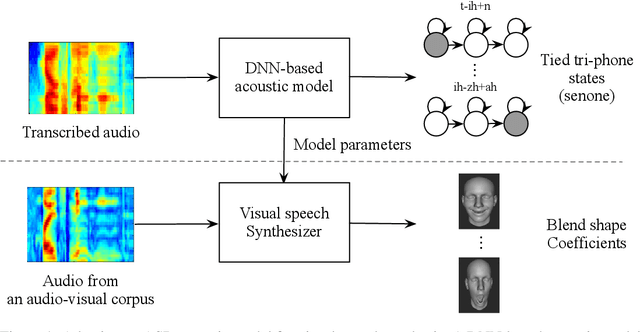

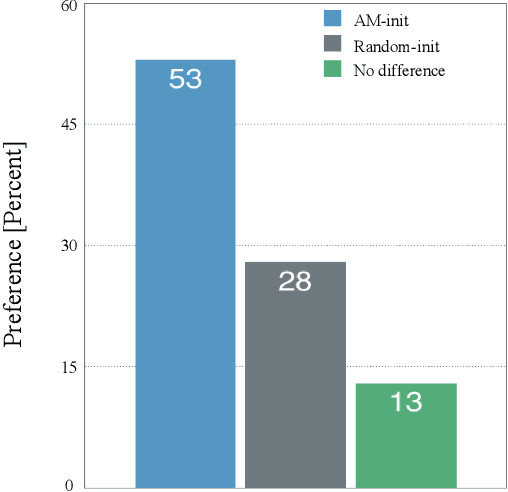
Speech-driven visual speech synthesis involves mapping features extracted from acoustic speech to the corresponding lip animation controls for a face model. This mapping can take many forms, but a powerful approach is to use deep neural networks (DNNs). However, a limitation is the lack of synchronized audio, video, and depth data required to reliably train the DNNs, especially for speaker-independent models. In this paper, we investigate adapting an automatic speech recognition (ASR) acoustic model (AM) for the visual speech synthesis problem. We train the AM on ten thousand hours of audio-only data. The AM is then adapted to the visual speech synthesis domain using ninety hours of synchronized audio-visual speech. Using a subjective assessment test, we compared the performance of the AM-initialized DNN to one with a random initialization. The results show that viewers significantly prefer animations generated from the AM-initialized DNN than the ones generated using the randomly initialized model. We conclude that visual speech synthesis can significantly benefit from the powerful representation of speech in the ASR acoustic models.