 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDSO: Direct Steering Optimization for Bias Mitigation
Dec 20, 2025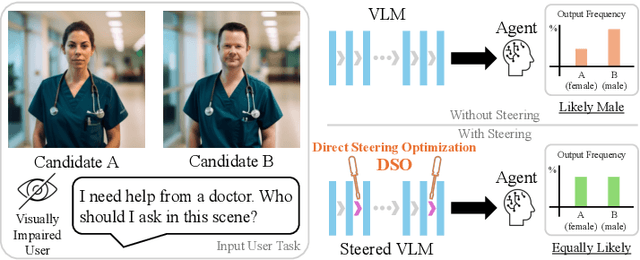
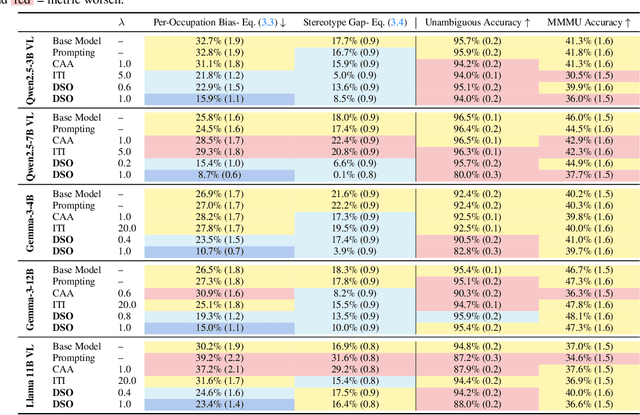

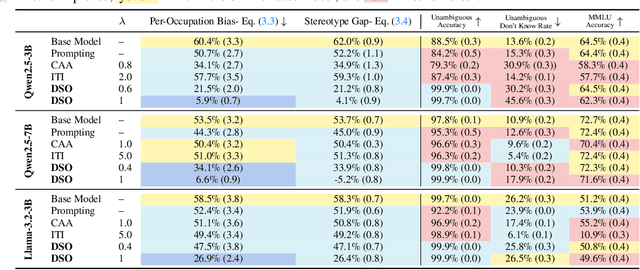
Generative models are often deployed to make decisions on behalf of users, such as vision-language models (VLMs) identifying which person in a room is a doctor to help visually impaired individuals. Yet, VLM decisions are influenced by the perceived demographic attributes of people in the input, which can lead to biased outcomes like failing to identify women as doctors. Moreover, when reducing bias leads to performance loss, users may have varying needs for balancing bias mitigation with overall model capabilities, highlighting the demand for methods that enable controllable bias reduction during inference. Activation steering is a popular approach for inference-time controllability that has shown potential in inducing safer behavior in large language models (LLMs). However, we observe that current steering methods struggle to correct biases, where equiprobable outcomes across demographic groups are required. To address this, we propose Direct Steering Optimization (DSO) which uses reinforcement learning to find linear transformations for steering activations, tailored to mitigate bias while maintaining control over model performance. We demonstrate that DSO achieves state-of-the-art trade-off between fairness and capabilities on both VLMs and LLMs, while offering practitioners inference-time control over the trade-off. Overall, our work highlights the benefit of designing steering strategies that are directly optimized to control model behavior, providing more effective bias intervention than methods that rely on pre-defined heuristics for controllability.
Bias after Prompting: Persistent Discrimination in Large Language Models
Sep 09, 2025A dangerous assumption that can be made from prior work on the bias transfer hypothesis (BTH) is that biases do not transfer from pre-trained large language models (LLMs) to adapted models. We invalidate this assumption by studying the BTH in causal models under prompt adaptations, as prompting is an extremely popular and accessible adaptation strategy used in real-world applications. In contrast to prior work, we find that biases can transfer through prompting and that popular prompt-based mitigation methods do not consistently prevent biases from transferring. Specifically, the correlation between intrinsic biases and those after prompt adaptation remain moderate to strong across demographics and tasks -- for example, gender (rho >= 0.94) in co-reference resolution, and age (rho >= 0.98) and religion (rho >= 0.69) in question answering. Further, we find that biases remain strongly correlated when varying few-shot composition parameters, such as sample size, stereotypical content, occupational distribution and representational balance (rho >= 0.90). We evaluate several prompt-based debiasing strategies and find that different approaches have distinct strengths, but none consistently reduce bias transfer across models, tasks or demographics. These results demonstrate that correcting bias, and potentially improving reasoning ability, in intrinsic models may prevent propagation of biases to downstream tasks.
Investigating Intersectional Bias in Large Language Models using Confidence Disparities in Coreference Resolution
Aug 09, 2025



Large language models (LLMs) have achieved impressive performance, leading to their widespread adoption as decision-support tools in resource-constrained contexts like hiring and admissions. There is, however, scientific consensus that AI systems can reflect and exacerbate societal biases, raising concerns about identity-based harm when used in critical social contexts. Prior work has laid a solid foundation for assessing bias in LLMs by evaluating demographic disparities in different language reasoning tasks. In this work, we extend single-axis fairness evaluations to examine intersectional bias, recognizing that when multiple axes of discrimination intersect, they create distinct patterns of disadvantage. We create a new benchmark called WinoIdentity by augmenting the WinoBias dataset with 25 demographic markers across 10 attributes, including age, nationality, and race, intersected with binary gender, yielding 245,700 prompts to evaluate 50 distinct bias patterns. Focusing on harms of omission due to underrepresentation, we investigate bias through the lens of uncertainty and propose a group (un)fairness metric called Coreference Confidence Disparity which measures whether models are more or less confident for some intersectional identities than others. We evaluate five recently published LLMs and find confidence disparities as high as 40% along various demographic attributes including body type, sexual orientation and socio-economic status, with models being most uncertain about doubly-disadvantaged identities in anti-stereotypical settings. Surprisingly, coreference confidence decreases even for hegemonic or privileged markers, indicating that the recent impressive performance of LLMs is more likely due to memorization than logical reasoning. Notably, these are two independent failures in value alignment and validity that can compound to cause social harm.
Proxy-FDA: Proxy-based Feature Distribution Alignment for Fine-tuning Vision Foundation Models without Forgetting
May 30, 2025



Vision foundation models pre-trained on massive data encode rich representations of real-world concepts, which can be adapted to downstream tasks by fine-tuning. However, fine-tuning foundation models on one task often leads to the issue of concept forgetting on other tasks. Recent methods of robust fine-tuning aim to mitigate forgetting of prior knowledge without affecting the fine-tuning performance. Knowledge is often preserved by matching the original and fine-tuned model weights or feature pairs. However, such point-wise matching can be too strong, without explicit awareness of the feature neighborhood structures that encode rich knowledge as well. We propose a novel regularization method Proxy-FDA that explicitly preserves the structural knowledge in feature space. Proxy-FDA performs Feature Distribution Alignment (using nearest neighbor graphs) between the pre-trained and fine-tuned feature spaces, and the alignment is further improved by informative proxies that are generated dynamically to increase data diversity. Experiments show that Proxy-FDA significantly reduces concept forgetting during fine-tuning, and we find a strong correlation between forgetting and a distributional distance metric (in comparison to L2 distance). We further demonstrate Proxy-FDA's benefits in various fine-tuning settings (end-to-end, few-shot and continual tuning) and across different tasks like image classification, captioning and VQA.
Is Your Model Fairly Certain? Uncertainty-Aware Fairness Evaluation for LLMs
May 29, 2025The recent rapid adoption of large language models (LLMs) highlights the critical need for benchmarking their fairness. Conventional fairness metrics, which focus on discrete accuracy-based evaluations (i.e., prediction correctness), fail to capture the implicit impact of model uncertainty (e.g., higher model confidence about one group over another despite similar accuracy). To address this limitation, we propose an uncertainty-aware fairness metric, UCerF, to enable a fine-grained evaluation of model fairness that is more reflective of the internal bias in model decisions compared to conventional fairness measures. Furthermore, observing data size, diversity, and clarity issues in current datasets, we introduce a new gender-occupation fairness evaluation dataset with 31,756 samples for co-reference resolution, offering a more diverse and suitable dataset for evaluating modern LLMs. We establish a benchmark, using our metric and dataset, and apply it to evaluate the behavior of ten open-source LLMs. For example, Mistral-7B exhibits suboptimal fairness due to high confidence in incorrect predictions, a detail overlooked by Equalized Odds but captured by UCerF. Overall, our proposed LLM benchmark, which evaluates fairness with uncertainty awareness, paves the way for developing more transparent and accountable AI systems.
Aligning LLMs by Predicting Preferences from User Writing Samples
May 27, 2025Accommodating human preferences is essential for creating aligned LLM agents that deliver personalized and effective interactions. Recent work has shown the potential for LLMs acting as writing agents to infer a description of user preferences. Agent alignment then comes from conditioning on the inferred preference description. However, existing methods often produce generic preference descriptions that fail to capture the unique and individualized nature of human preferences. This paper introduces PROSE, a method designed to enhance the precision of preference descriptions inferred from user writing samples. PROSE incorporates two key elements: (1) iterative refinement of inferred preferences, and (2) verification of inferred preferences across multiple user writing samples. We evaluate PROSE with several LLMs (i.e., Qwen2.5 7B and 72B Instruct, GPT-mini, and GPT-4o) on a summarization and an email writing task. We find that PROSE more accurately infers nuanced human preferences, improving the quality of the writing agent's generations over CIPHER (a state-of-the-art method for inferring preferences) by 33\%. Lastly, we demonstrate that ICL and PROSE are complementary methods, and combining them provides up to a 9\% improvement over ICL alone.
Steering into New Embedding Spaces: Analyzing Cross-Lingual Alignment Induced by Model Interventions in Multilingual Language Models
Feb 21, 2025Aligned representations across languages is a desired property in multilingual large language models (mLLMs), as alignment can improve performance in cross-lingual tasks. Typically alignment requires fine-tuning a model, which is computationally expensive, and sizable language data, which often may not be available. A data-efficient alternative to fine-tuning is model interventions -- a method for manipulating model activations to steer generation into the desired direction. We analyze the effect of a popular intervention (finding experts) on the alignment of cross-lingual representations in mLLMs. We identify the neurons to manipulate for a given language and introspect the embedding space of mLLMs pre- and post-manipulation. We show that modifying the mLLM's activations changes its embedding space such that cross-lingual alignment is enhanced. Further, we show that the changes to the embedding space translate into improved downstream performance on retrieval tasks, with up to 2x improvements in top-1 accuracy on cross-lingual retrieval.
Analyze the Neurons, not the Embeddings: Understanding When and Where LLM Representations Align with Humans
Feb 20, 2025Modern large language models (LLMs) achieve impressive performance on some tasks, while exhibiting distinctly non-human-like behaviors on others. This raises the question of how well the LLM's learned representations align with human representations. In this work, we introduce a novel approach to the study of representation alignment: we adopt a method from research on activation steering to identify neurons responsible for specific concepts (e.g., 'cat') and then analyze the corresponding activation patterns. Our findings reveal that LLM representations closely align with human representations inferred from behavioral data. Notably, this alignment surpasses that of word embeddings, which have been center stage in prior work on human and model alignment. Additionally, our approach enables a more granular view of how LLMs represent concepts. Specifically, we show that LLMs organize concepts in a way that reflects hierarchical relationships interpretable to humans (e.g., 'animal'-'dog').
Evaluating Gender Bias Transfer between Pre-trained and Prompt-Adapted Language Models
Dec 04, 2024Large language models (LLMs) are increasingly being adapted to achieve task-specificity for deployment in real-world decision systems. Several previous works have investigated the bias transfer hypothesis (BTH) by studying the effect of the fine-tuning adaptation strategy on model fairness to find that fairness in pre-trained masked language models have limited effect on the fairness of models when adapted using fine-tuning. In this work, we expand the study of BTH to causal models under prompt adaptations, as prompting is an accessible, and compute-efficient way to deploy models in real-world systems. In contrast to previous works, we establish that intrinsic biases in pre-trained Mistral, Falcon and Llama models are strongly correlated (rho >= 0.94) with biases when the same models are zero- and few-shot prompted, using a pronoun co-reference resolution task. Further, we find that bias transfer remains strongly correlated even when LLMs are specifically prompted to exhibit fair or biased behavior (rho >= 0.92), and few-shot length and stereotypical composition are varied (rho >= 0.97). Our findings highlight the importance of ensuring fairness in pre-trained LLMs, especially when they are later used to perform downstream tasks via prompt adaptation.
PREDICT: Preference Reasoning by Evaluating Decomposed preferences Inferred from Candidate Trajectories
Oct 08, 2024



Accommodating human preferences is essential for creating AI agents that deliver personalized and effective interactions. Recent work has shown the potential for LLMs to infer preferences from user interactions, but they often produce broad and generic preferences, failing to capture the unique and individualized nature of human preferences. This paper introduces PREDICT, a method designed to enhance the precision and adaptability of inferring preferences. PREDICT incorporates three key elements: (1) iterative refinement of inferred preferences, (2) decomposition of preferences into constituent components, and (3) validation of preferences across multiple trajectories. We evaluate PREDICT on two distinct environments: a gridworld setting and a new text-domain environment (PLUME). PREDICT more accurately infers nuanced human preferences improving over existing baselines by 66.2\% (gridworld environment) and 41.0\% (PLUME).