 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBias after Prompting: Persistent Discrimination in Large Language Models
Sep 09, 2025A dangerous assumption that can be made from prior work on the bias transfer hypothesis (BTH) is that biases do not transfer from pre-trained large language models (LLMs) to adapted models. We invalidate this assumption by studying the BTH in causal models under prompt adaptations, as prompting is an extremely popular and accessible adaptation strategy used in real-world applications. In contrast to prior work, we find that biases can transfer through prompting and that popular prompt-based mitigation methods do not consistently prevent biases from transferring. Specifically, the correlation between intrinsic biases and those after prompt adaptation remain moderate to strong across demographics and tasks -- for example, gender (rho >= 0.94) in co-reference resolution, and age (rho >= 0.98) and religion (rho >= 0.69) in question answering. Further, we find that biases remain strongly correlated when varying few-shot composition parameters, such as sample size, stereotypical content, occupational distribution and representational balance (rho >= 0.90). We evaluate several prompt-based debiasing strategies and find that different approaches have distinct strengths, but none consistently reduce bias transfer across models, tasks or demographics. These results demonstrate that correcting bias, and potentially improving reasoning ability, in intrinsic models may prevent propagation of biases to downstream tasks.
Is Your Model Fairly Certain? Uncertainty-Aware Fairness Evaluation for LLMs
May 29, 2025The recent rapid adoption of large language models (LLMs) highlights the critical need for benchmarking their fairness. Conventional fairness metrics, which focus on discrete accuracy-based evaluations (i.e., prediction correctness), fail to capture the implicit impact of model uncertainty (e.g., higher model confidence about one group over another despite similar accuracy). To address this limitation, we propose an uncertainty-aware fairness metric, UCerF, to enable a fine-grained evaluation of model fairness that is more reflective of the internal bias in model decisions compared to conventional fairness measures. Furthermore, observing data size, diversity, and clarity issues in current datasets, we introduce a new gender-occupation fairness evaluation dataset with 31,756 samples for co-reference resolution, offering a more diverse and suitable dataset for evaluating modern LLMs. We establish a benchmark, using our metric and dataset, and apply it to evaluate the behavior of ten open-source LLMs. For example, Mistral-7B exhibits suboptimal fairness due to high confidence in incorrect predictions, a detail overlooked by Equalized Odds but captured by UCerF. Overall, our proposed LLM benchmark, which evaluates fairness with uncertainty awareness, paves the way for developing more transparent and accountable AI systems.
Aligning LLMs by Predicting Preferences from User Writing Samples
May 27, 2025Accommodating human preferences is essential for creating aligned LLM agents that deliver personalized and effective interactions. Recent work has shown the potential for LLMs acting as writing agents to infer a description of user preferences. Agent alignment then comes from conditioning on the inferred preference description. However, existing methods often produce generic preference descriptions that fail to capture the unique and individualized nature of human preferences. This paper introduces PROSE, a method designed to enhance the precision of preference descriptions inferred from user writing samples. PROSE incorporates two key elements: (1) iterative refinement of inferred preferences, and (2) verification of inferred preferences across multiple user writing samples. We evaluate PROSE with several LLMs (i.e., Qwen2.5 7B and 72B Instruct, GPT-mini, and GPT-4o) on a summarization and an email writing task. We find that PROSE more accurately infers nuanced human preferences, improving the quality of the writing agent's generations over CIPHER (a state-of-the-art method for inferring preferences) by 33\%. Lastly, we demonstrate that ICL and PROSE are complementary methods, and combining them provides up to a 9\% improvement over ICL alone.
Evaluating Gender Bias Transfer between Pre-trained and Prompt-Adapted Language Models
Dec 04, 2024Large language models (LLMs) are increasingly being adapted to achieve task-specificity for deployment in real-world decision systems. Several previous works have investigated the bias transfer hypothesis (BTH) by studying the effect of the fine-tuning adaptation strategy on model fairness to find that fairness in pre-trained masked language models have limited effect on the fairness of models when adapted using fine-tuning. In this work, we expand the study of BTH to causal models under prompt adaptations, as prompting is an accessible, and compute-efficient way to deploy models in real-world systems. In contrast to previous works, we establish that intrinsic biases in pre-trained Mistral, Falcon and Llama models are strongly correlated (rho >= 0.94) with biases when the same models are zero- and few-shot prompted, using a pronoun co-reference resolution task. Further, we find that bias transfer remains strongly correlated even when LLMs are specifically prompted to exhibit fair or biased behavior (rho >= 0.92), and few-shot length and stereotypical composition are varied (rho >= 0.97). Our findings highlight the importance of ensuring fairness in pre-trained LLMs, especially when they are later used to perform downstream tasks via prompt adaptation.
PREDICT: Preference Reasoning by Evaluating Decomposed preferences Inferred from Candidate Trajectories
Oct 08, 2024



Accommodating human preferences is essential for creating AI agents that deliver personalized and effective interactions. Recent work has shown the potential for LLMs to infer preferences from user interactions, but they often produce broad and generic preferences, failing to capture the unique and individualized nature of human preferences. This paper introduces PREDICT, a method designed to enhance the precision and adaptability of inferring preferences. PREDICT incorporates three key elements: (1) iterative refinement of inferred preferences, (2) decomposition of preferences into constituent components, and (3) validation of preferences across multiple trajectories. We evaluate PREDICT on two distinct environments: a gridworld setting and a new text-domain environment (PLUME). PREDICT more accurately infers nuanced human preferences improving over existing baselines by 66.2\% (gridworld environment) and 41.0\% (PLUME).
Sample-Efficient Preference-based Reinforcement Learning with Dynamics Aware Rewards
Feb 28, 2024Preference-based reinforcement learning (PbRL) aligns a robot behavior with human preferences via a reward function learned from binary feedback over agent behaviors. We show that dynamics-aware reward functions improve the sample efficiency of PbRL by an order of magnitude. In our experiments we iterate between: (1) learning a dynamics-aware state-action representation (z^{sa}) via a self-supervised temporal consistency task, and (2) bootstrapping the preference-based reward function from (z^{sa}), which results in faster policy learning and better final policy performance. For example, on quadruped-walk, walker-walk, and cheetah-run, with 50 preference labels we achieve the same performance as existing approaches with 500 preference labels, and we recover 83\% and 66\% of ground truth reward policy performance versus only 38\% and 21\%. The performance gains demonstrate the benefits of explicitly learning a dynamics-aware reward model. Repo: \texttt{https://github.com/apple/ml-reed}.
Large Language Models as Generalizable Policies for Embodied Tasks
Oct 26, 2023
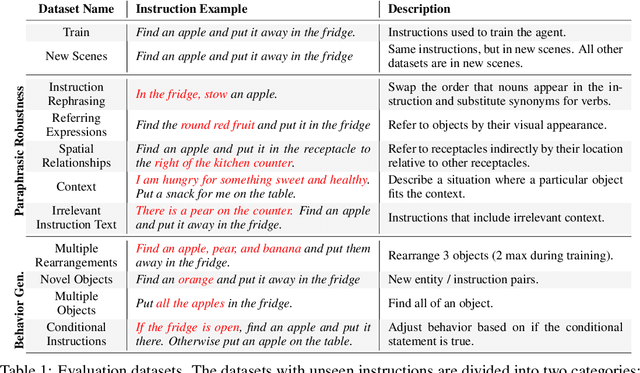
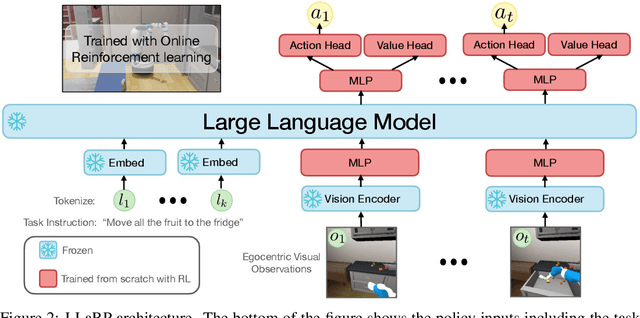
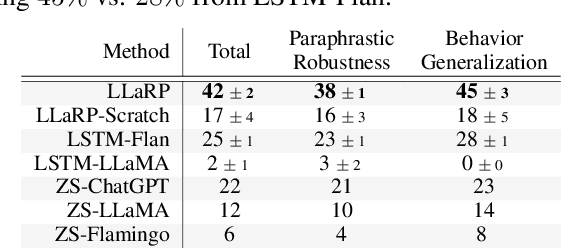
We show that large language models (LLMs) can be adapted to be generalizable policies for embodied visual tasks. Our approach, called Large LAnguage model Reinforcement Learning Policy (LLaRP), adapts a pre-trained frozen LLM to take as input text instructions and visual egocentric observations and output actions directly in the environment. Using reinforcement learning, we train LLaRP to see and act solely through environmental interactions. We show that LLaRP is robust to complex paraphrasings of task instructions and can generalize to new tasks that require novel optimal behavior. In particular, on 1,000 unseen tasks it achieves 42% success rate, 1.7x the success rate of other common learned baselines or zero-shot applications of LLMs. Finally, to aid the community in studying language conditioned, massively multi-task, embodied AI problems we release a novel benchmark, Language Rearrangement, consisting of 150,000 training and 1,000 testing tasks for language-conditioned rearrangement. Video examples of LLaRP in unseen Language Rearrangement instructions are at https://llm-rl.github.io.