 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInvestigating Intersectional Bias in Large Language Models using Confidence Disparities in Coreference Resolution
Aug 09, 2025



Large language models (LLMs) have achieved impressive performance, leading to their widespread adoption as decision-support tools in resource-constrained contexts like hiring and admissions. There is, however, scientific consensus that AI systems can reflect and exacerbate societal biases, raising concerns about identity-based harm when used in critical social contexts. Prior work has laid a solid foundation for assessing bias in LLMs by evaluating demographic disparities in different language reasoning tasks. In this work, we extend single-axis fairness evaluations to examine intersectional bias, recognizing that when multiple axes of discrimination intersect, they create distinct patterns of disadvantage. We create a new benchmark called WinoIdentity by augmenting the WinoBias dataset with 25 demographic markers across 10 attributes, including age, nationality, and race, intersected with binary gender, yielding 245,700 prompts to evaluate 50 distinct bias patterns. Focusing on harms of omission due to underrepresentation, we investigate bias through the lens of uncertainty and propose a group (un)fairness metric called Coreference Confidence Disparity which measures whether models are more or less confident for some intersectional identities than others. We evaluate five recently published LLMs and find confidence disparities as high as 40% along various demographic attributes including body type, sexual orientation and socio-economic status, with models being most uncertain about doubly-disadvantaged identities in anti-stereotypical settings. Surprisingly, coreference confidence decreases even for hegemonic or privileged markers, indicating that the recent impressive performance of LLMs is more likely due to memorization than logical reasoning. Notably, these are two independent failures in value alignment and validity that can compound to cause social harm.
Is Your Model Fairly Certain? Uncertainty-Aware Fairness Evaluation for LLMs
May 29, 2025The recent rapid adoption of large language models (LLMs) highlights the critical need for benchmarking their fairness. Conventional fairness metrics, which focus on discrete accuracy-based evaluations (i.e., prediction correctness), fail to capture the implicit impact of model uncertainty (e.g., higher model confidence about one group over another despite similar accuracy). To address this limitation, we propose an uncertainty-aware fairness metric, UCerF, to enable a fine-grained evaluation of model fairness that is more reflective of the internal bias in model decisions compared to conventional fairness measures. Furthermore, observing data size, diversity, and clarity issues in current datasets, we introduce a new gender-occupation fairness evaluation dataset with 31,756 samples for co-reference resolution, offering a more diverse and suitable dataset for evaluating modern LLMs. We establish a benchmark, using our metric and dataset, and apply it to evaluate the behavior of ten open-source LLMs. For example, Mistral-7B exhibits suboptimal fairness due to high confidence in incorrect predictions, a detail overlooked by Equalized Odds but captured by UCerF. Overall, our proposed LLM benchmark, which evaluates fairness with uncertainty awareness, paves the way for developing more transparent and accountable AI systems.
Still More Shades of Null: A Benchmark for Responsible Missing Value Imputation
Sep 11, 2024



We present Shades-of-NULL, a benchmark for responsible missing value imputation. Our benchmark includes state-of-the-art imputation techniques, and embeds them into the machine learning development lifecycle. We model realistic missingness scenarios that go beyond Rubin's classic Missing Completely at Random (MCAR), Missing At Random (MAR) and Missing Not At Random (MNAR), to include multi-mechanism missingness (when different missingness patterns co-exist in the data) and missingness shift (when the missingness mechanism changes between training and test). Another key novelty of our work is that we evaluate imputers holistically, based on the predictive performance, fairness and stability of the models that are trained and tested on the data they produce. We use Shades-of-NULL to conduct a large-scale empirical study involving 20,952 experimental pipelines, and find that, while there is no single best-performing imputation approach for all missingness types, interesting performance patterns do emerge when comparing imputer performance in simpler vs. more complex missingness scenarios. Further, while predictive performance, fairness and stability can be seen as orthogonal, we identify trade-offs among them that arise due to the combination of missingness scenario, the choice of an imputer, and the architecture of the model trained on the data post-imputation. We make Shades-of-NULL publicly available, and hope to enable researchers to comprehensively and rigorously evaluate new missing value imputation methods on a wide range of evaluation metrics, in plausible and socially meaningful missingness scenarios.
The Unbearable Weight of Massive Privilege: Revisiting Bias-Variance Trade-Offs in the Context of Fair Prediction
Feb 17, 2023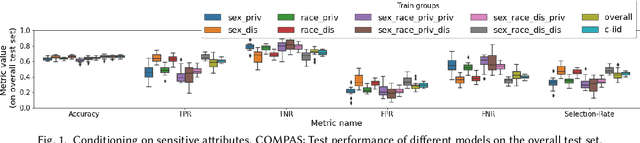

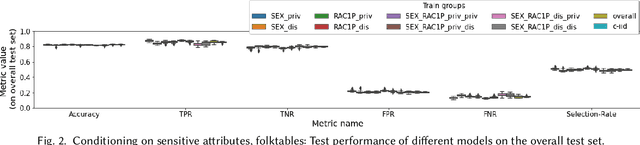

In this paper we revisit the bias-variance decomposition of model error from the perspective of designing a fair classifier: we are motivated by the widely held socio-technical belief that noise variance in large datasets in social domains tracks demographic characteristics such as gender, race, disability, etc. We propose a conditional-iid (ciid) model built from group-specific classifiers that seeks to improve on the trade-offs made by a single model (iid setting). We theoretically analyze the bias-variance decomposition of different models in the Gaussian Mixture Model, and then empirically test our setup on the COMPAS and folktables datasets. We instantiate the ciid model with two procedures that improve "fairness" by conditioning out undesirable effects: first, by conditioning directly on sensitive attributes, and second, by clustering samples into groups and conditioning on cluster membership (blind to protected group membership). Our analysis suggests that there might be principled procedures and concrete real-world use cases under which conditional models are preferred, and our striking empirical results strongly indicate that non-iid settings, such as the ciid setting proposed here, might be more suitable for big data applications in social contexts.
On Fairness and Stability: Is Estimator Variance a Friend or a Foe?
Feb 09, 2023



The error of an estimator can be decomposed into a (statistical) bias term, a variance term, and an irreducible noise term. When we do bias analysis, formally we are asking the question: "how good are the predictions?" The role of bias in the error decomposition is clear: if we trust the labels/targets, then we would want the estimator to have as low bias as possible, in order to minimize error. Fair machine learning is concerned with the question: "Are the predictions equally good for different demographic/social groups?" This has naturally led to a variety of fairness metrics that compare some measure of statistical bias on subsets corresponding to socially privileged and socially disadvantaged groups. In this paper we propose a new family of performance measures based on group-wise parity in variance. We demonstrate when group-wise statistical bias analysis gives an incomplete picture, and what group-wise variance analysis can tell us in settings that differ in the magnitude of statistical bias. We develop and release an open-source library that reconciles uncertainty quantification techniques with fairness analysis, and use it to conduct an extensive empirical analysis of our variance-based fairness measures on standard benchmarks.
Towards Substantive Conceptions of Algorithmic Fairness: Normative Guidance from Equal Opportunity Doctrines
Jul 11, 2022

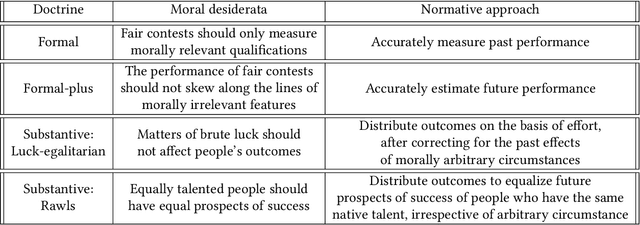
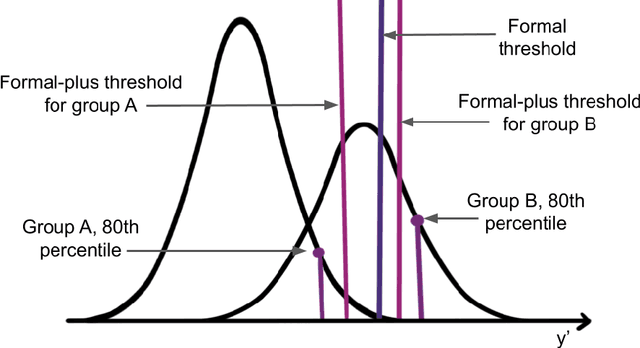
In this work we use Equal Oppportunity (EO) doctrines from political philosophy to make explicit the normative judgements embedded in different conceptions of algorithmic fairness. We contrast formal EO approaches that narrowly focus on fair contests at discrete decision points, with substantive EO doctrines that look at people's fair life chances more holistically over the course of a lifetime. We use this taxonomy to provide a moral interpretation of the impossibility results as the incompatibility between different conceptions of a fair contest -- foward-looking versus backward-looking -- when people do not have fair life chances. We use this result to motivate substantive conceptions of algorithmic fairness and outline two plausible procedures based on the luck-egalitarian doctrine of EO, and Rawls's principle of fair equality of opportunity.
Fairness as Equality of Opportunity: Normative Guidance from Political Philosophy
Jun 15, 2021

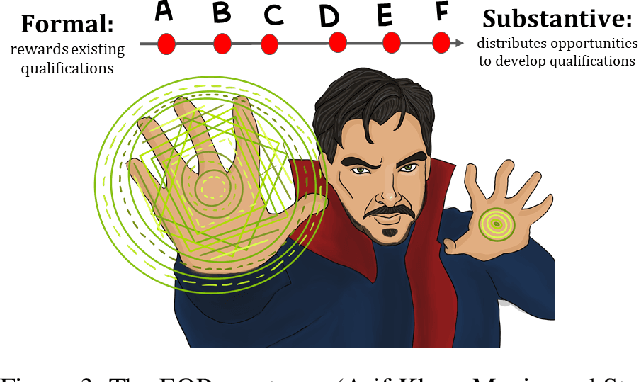

Recent interest in codifying fairness in Automated Decision Systems (ADS) has resulted in a wide range of formulations of what it means for an algorithmic system to be fair. Most of these propositions are inspired by, but inadequately grounded in, political philosophy scholarship. This paper aims to correct that deficit. We introduce a taxonomy of fairness ideals using doctrines of Equality of Opportunity (EOP) from political philosophy, clarifying their conceptions in philosophy and the proposed codification in fair machine learning. We arrange these fairness ideals onto an EOP spectrum, which serves as a useful frame to guide the design of a fair ADS in a given context. We use our fairness-as-EOP framework to re-interpret the impossibility results from a philosophical perspective, as the in-compatibility between different value systems, and demonstrate the utility of the framework with several real-world and hypothetical examples. Through our EOP-framework we hope to answer what it means for an ADS to be fair from a moral and political philosophy standpoint, and to pave the way for similar scholarship from ethics and legal experts.
The State of AI Ethics Report
May 19, 2021The 3rd edition of the Montreal AI Ethics Institute's The State of AI Ethics captures the most relevant developments in AI Ethics since October 2020. It aims to help anyone, from machine learning experts to human rights activists and policymakers, quickly digest and understand the field's ever-changing developments. Through research and article summaries, as well as expert commentary, this report distills the research and reporting surrounding various domains related to the ethics of AI, including: algorithmic injustice, discrimination, ethical AI, labor impacts, misinformation, privacy, risk and security, social media, and more. In addition, The State of AI Ethics includes exclusive content written by world-class AI Ethics experts from universities, research institutes, consulting firms, and governments. Unique to this report is "The Abuse and Misogynoir Playbook," written by Dr. Katlyn Tuner (Research Scientist, Space Enabled Research Group, MIT), Dr. Danielle Wood (Assistant Professor, Program in Media Arts and Sciences; Assistant Professor, Aeronautics and Astronautics; Lead, Space Enabled Research Group, MIT) and Dr. Catherine D'Ignazio (Assistant Professor, Urban Science and Planning; Director, Data + Feminism Lab, MIT). The piece (and accompanying infographic), is a deep-dive into the historical and systematic silencing, erasure, and revision of Black women's contributions to knowledge and scholarship in the United Stations, and globally. Exposing and countering this Playbook has become increasingly important following the firing of AI Ethics expert Dr. Timnit Gebru (and several of her supporters) at Google. This report should be used not only as a point of reference and insight on the latest thinking in the field of AI Ethics, but should also be used as a tool for introspection as we aim to foster a more nuanced conversation regarding the impacts of AI on the world.