 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDSO: Direct Steering Optimization for Bias Mitigation
Dec 20, 2025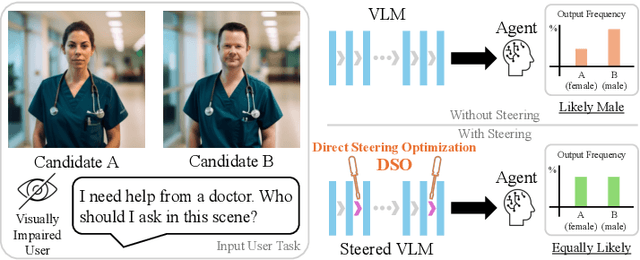
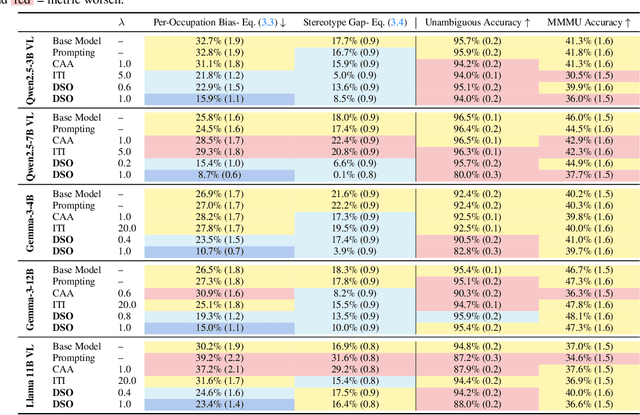

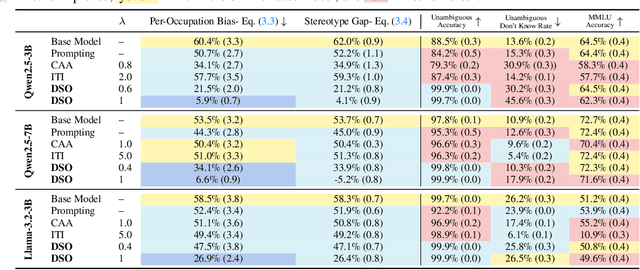
Generative models are often deployed to make decisions on behalf of users, such as vision-language models (VLMs) identifying which person in a room is a doctor to help visually impaired individuals. Yet, VLM decisions are influenced by the perceived demographic attributes of people in the input, which can lead to biased outcomes like failing to identify women as doctors. Moreover, when reducing bias leads to performance loss, users may have varying needs for balancing bias mitigation with overall model capabilities, highlighting the demand for methods that enable controllable bias reduction during inference. Activation steering is a popular approach for inference-time controllability that has shown potential in inducing safer behavior in large language models (LLMs). However, we observe that current steering methods struggle to correct biases, where equiprobable outcomes across demographic groups are required. To address this, we propose Direct Steering Optimization (DSO) which uses reinforcement learning to find linear transformations for steering activations, tailored to mitigate bias while maintaining control over model performance. We demonstrate that DSO achieves state-of-the-art trade-off between fairness and capabilities on both VLMs and LLMs, while offering practitioners inference-time control over the trade-off. Overall, our work highlights the benefit of designing steering strategies that are directly optimized to control model behavior, providing more effective bias intervention than methods that rely on pre-defined heuristics for controllability.
Bias after Prompting: Persistent Discrimination in Large Language Models
Sep 09, 2025A dangerous assumption that can be made from prior work on the bias transfer hypothesis (BTH) is that biases do not transfer from pre-trained large language models (LLMs) to adapted models. We invalidate this assumption by studying the BTH in causal models under prompt adaptations, as prompting is an extremely popular and accessible adaptation strategy used in real-world applications. In contrast to prior work, we find that biases can transfer through prompting and that popular prompt-based mitigation methods do not consistently prevent biases from transferring. Specifically, the correlation between intrinsic biases and those after prompt adaptation remain moderate to strong across demographics and tasks -- for example, gender (rho >= 0.94) in co-reference resolution, and age (rho >= 0.98) and religion (rho >= 0.69) in question answering. Further, we find that biases remain strongly correlated when varying few-shot composition parameters, such as sample size, stereotypical content, occupational distribution and representational balance (rho >= 0.90). We evaluate several prompt-based debiasing strategies and find that different approaches have distinct strengths, but none consistently reduce bias transfer across models, tasks or demographics. These results demonstrate that correcting bias, and potentially improving reasoning ability, in intrinsic models may prevent propagation of biases to downstream tasks.
Investigating Intersectional Bias in Large Language Models using Confidence Disparities in Coreference Resolution
Aug 09, 2025



Large language models (LLMs) have achieved impressive performance, leading to their widespread adoption as decision-support tools in resource-constrained contexts like hiring and admissions. There is, however, scientific consensus that AI systems can reflect and exacerbate societal biases, raising concerns about identity-based harm when used in critical social contexts. Prior work has laid a solid foundation for assessing bias in LLMs by evaluating demographic disparities in different language reasoning tasks. In this work, we extend single-axis fairness evaluations to examine intersectional bias, recognizing that when multiple axes of discrimination intersect, they create distinct patterns of disadvantage. We create a new benchmark called WinoIdentity by augmenting the WinoBias dataset with 25 demographic markers across 10 attributes, including age, nationality, and race, intersected with binary gender, yielding 245,700 prompts to evaluate 50 distinct bias patterns. Focusing on harms of omission due to underrepresentation, we investigate bias through the lens of uncertainty and propose a group (un)fairness metric called Coreference Confidence Disparity which measures whether models are more or less confident for some intersectional identities than others. We evaluate five recently published LLMs and find confidence disparities as high as 40% along various demographic attributes including body type, sexual orientation and socio-economic status, with models being most uncertain about doubly-disadvantaged identities in anti-stereotypical settings. Surprisingly, coreference confidence decreases even for hegemonic or privileged markers, indicating that the recent impressive performance of LLMs is more likely due to memorization than logical reasoning. Notably, these are two independent failures in value alignment and validity that can compound to cause social harm.
Is Your Model Fairly Certain? Uncertainty-Aware Fairness Evaluation for LLMs
May 29, 2025The recent rapid adoption of large language models (LLMs) highlights the critical need for benchmarking their fairness. Conventional fairness metrics, which focus on discrete accuracy-based evaluations (i.e., prediction correctness), fail to capture the implicit impact of model uncertainty (e.g., higher model confidence about one group over another despite similar accuracy). To address this limitation, we propose an uncertainty-aware fairness metric, UCerF, to enable a fine-grained evaluation of model fairness that is more reflective of the internal bias in model decisions compared to conventional fairness measures. Furthermore, observing data size, diversity, and clarity issues in current datasets, we introduce a new gender-occupation fairness evaluation dataset with 31,756 samples for co-reference resolution, offering a more diverse and suitable dataset for evaluating modern LLMs. We establish a benchmark, using our metric and dataset, and apply it to evaluate the behavior of ten open-source LLMs. For example, Mistral-7B exhibits suboptimal fairness due to high confidence in incorrect predictions, a detail overlooked by Equalized Odds but captured by UCerF. Overall, our proposed LLM benchmark, which evaluates fairness with uncertainty awareness, paves the way for developing more transparent and accountable AI systems.
Evaluating Gender Bias Transfer between Pre-trained and Prompt-Adapted Language Models
Dec 04, 2024Large language models (LLMs) are increasingly being adapted to achieve task-specificity for deployment in real-world decision systems. Several previous works have investigated the bias transfer hypothesis (BTH) by studying the effect of the fine-tuning adaptation strategy on model fairness to find that fairness in pre-trained masked language models have limited effect on the fairness of models when adapted using fine-tuning. In this work, we expand the study of BTH to causal models under prompt adaptations, as prompting is an accessible, and compute-efficient way to deploy models in real-world systems. In contrast to previous works, we establish that intrinsic biases in pre-trained Mistral, Falcon and Llama models are strongly correlated (rho >= 0.94) with biases when the same models are zero- and few-shot prompted, using a pronoun co-reference resolution task. Further, we find that bias transfer remains strongly correlated even when LLMs are specifically prompted to exhibit fair or biased behavior (rho >= 0.92), and few-shot length and stereotypical composition are varied (rho >= 0.97). Our findings highlight the importance of ensuring fairness in pre-trained LLMs, especially when they are later used to perform downstream tasks via prompt adaptation.
Fair SA: Sensitivity Analysis for Fairness in Face Recognition
Feb 09, 2022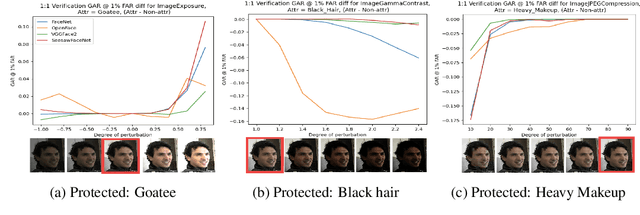



As the use of deep learning in high impact domains becomes ubiquitous, it is increasingly important to assess the resilience of models. One such high impact domain is that of face recognition, with real world applications involving images affected by various degradations, such as motion blur or high exposure. Moreover, images captured across different attributes, such as gender and race, can also challenge the robustness of a face recognition algorithm. While traditional summary statistics suggest that the aggregate performance of face recognition models has continued to improve, these metrics do not directly measure the robustness or fairness of the models. Visual Psychophysics Sensitivity Analysis (VPSA) [1] provides a way to pinpoint the individual causes of failure by way of introducing incremental perturbations in the data. However, perturbations may affect subgroups differently. In this paper, we propose a new fairness evaluation based on robustness in the form of a generic framework that extends VPSA. With this framework, we can analyze the ability of a model to perform fairly for different subgroups of a population affected by perturbations, and pinpoint the exact failure modes for a subgroup by measuring targeted robustness. With the increasing focus on the fairness of models, we use face recognition as an example application of our framework and propose to compactly visualize the fairness analysis of a model via AUC matrices. We analyze the performance of common face recognition models and empirically show that certain subgroups are at a disadvantage when images are perturbed, thereby uncovering trends that were not visible using the model's performance on subgroups without perturbations.
Robust Fruit Counting: Combining Deep Learning, Tracking, and Structure from Motion
Aug 02, 2018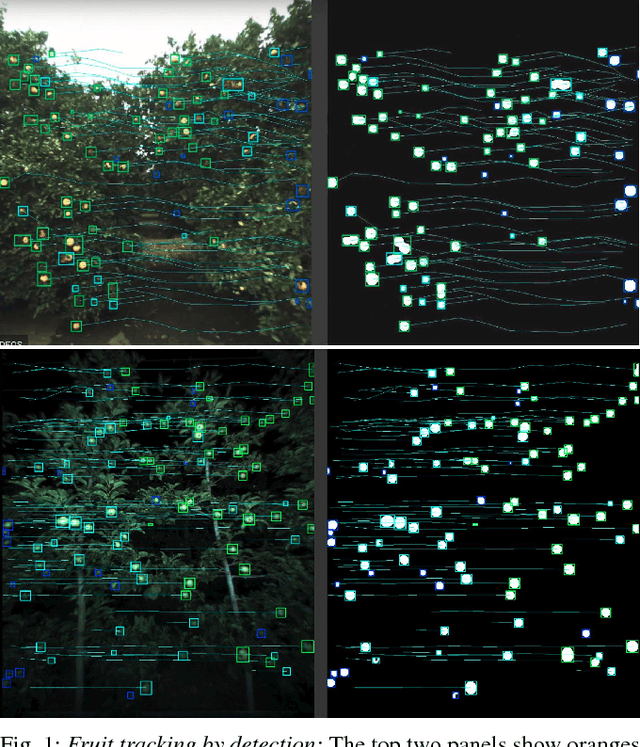
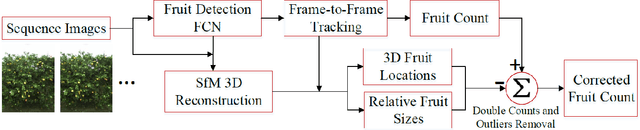
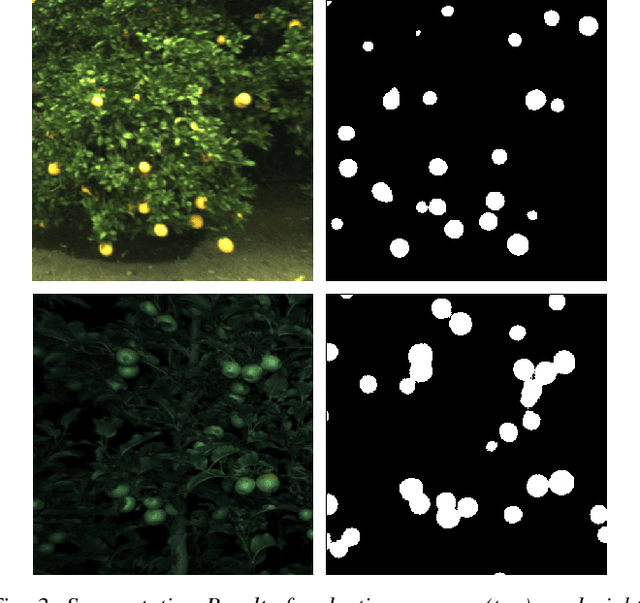

We present a novel fruit counting pipeline that combines deep segmentation, frame to frame tracking, and 3D localization to accurately count visible fruits across a sequence of images. Our pipeline works on image streams from a monocular camera, both in natural light, as well as with controlled illumination at night. We first train a Fully Convolutional Network (FCN) and segment video frame images into fruit and non-fruit pixels. We then track fruits across frames using the Hungarian Algorithm where the objective cost is determined from a Kalman Filter corrected Kanade-Lucas-Tomasi (KLT) Tracker. In order to correct the estimated count from tracking process, we combine tracking results with a Structure from Motion (SfM) algorithm to calculate relative 3D locations and size estimates to reject outliers and double counted fruit tracks. We evaluate our algorithm by comparing with ground-truth human-annotated visual counts. Our results demonstrate that our pipeline is able to accurately and reliably count fruits across image sequences, and the correction step can significantly improve the counting accuracy and robustness. Although discussed in the context of fruit counting, our work can extend to detection, tracking, and counting of a variety of other stationary features of interest such as leaf-spots, wilt, and blossom.