 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUni-ViGU: Towards Unified Video Generation and Understanding via A Diffusion-Based Video Generator
Apr 09, 2026Unified multimodal models integrating visual understanding and generation face a fundamental challenge: visual generation incurs substantially higher computational costs than understanding, particularly for video. This imbalance motivates us to invert the conventional paradigm: rather than extending understanding-centric MLLMs to support generation, we propose Uni-ViGU, a framework that unifies video generation and understanding by extending a video generator as the foundation. We introduce a unified flow method that performs continuous flow matching for video and discrete flow matching for text within a single process, enabling coherent multimodal generation. We further propose a modality-driven MoE-based framework that augments Transformer blocks with lightweight layers for text generation while preserving generative priors. To repurpose generation knowledge for understanding, we design a bidirectional training mechanism with two stages: Knowledge Recall reconstructs input prompts to leverage learned text-video correspondences, while Capability Refinement fine-tunes on detailed captions to establish discriminative shared representations. Experiments demonstrate that Uni-ViGU achieves competitive performance on both video generation and understanding, validating generation-centric architectures as a scalable path toward unified multimodal intelligence. Project Page and Code: https://fr0zencrane.github.io/uni-vigu-page/.
Suiren-1.0 Technical Report: A Family of Molecular Foundation Models
Mar 23, 2026We introduce Suiren-1.0, a family of molecular foundation models for the accurate modeling of diverse organic systems. Suiren-1.0 comprising three specialized variants (Suiren-Base, Suiren-Dimer, and Suiren-ConfAvg) is integrated within an algorithmic framework that bridges the gap between 3D conformational geometry and 2D statistical ensemble spaces. We first pre-train Suiren-Base (1.8B parameters) on a 70M-sample Density Functional Theory dataset using spatial self-supervision and SE(3)-equivariant architectures, achieving robust performance in quantum property prediction. Suiren-Dimer extends this capability through continued pre-training on 13.5M intermolecular interaction samples. To enable efficient downstream application, we propose Conformation Compression Distillation (CCD), a diffusion-based framework that distills complex 3D structural representations into 2D conformation-averaged representations. This yields the lightweight Suiren-ConfAvg, which generates high-fidelity representations from SMILES or molecular graphs. Our extensive evaluations demonstrate that Suiren-1.0 establishes state-of-the-art results across a range of tasks. All models and benchmarks are open-sourced.
SQL-ASTRA: Alleviating Sparse Feedback in Agentic SQL via Column-Set Matching and Trajectory Aggregation
Mar 17, 2026Agentic Reinforcement Learning (RL) shows promise for complex tasks, but Text-to-SQL remains mostly restricted to single-turn paradigms. A primary bottleneck is the credit assignment problem. In traditional paradigms, rewards are determined solely by the final-turn feedback, which ignores the intermediate process and leads to ambiguous credit evaluation. To address this, we propose Agentic SQL, a framework featuring a universal two-tiered reward mechanism designed to provide effective trajectory-level evaluation and dense step-level signals. First, we introduce Aggregated Trajectory Reward (ATR) to resolve multi-turn credit assignment. Using an asymmetric transition matrix, ATR aggregates process-oriented scores to incentivize continuous improvement. Leveraging Lyapunov stability theory, we prove ATR acts as an energy dissipation operator, guaranteeing a cycle-free policy and monotonic convergence. Second, Column-Set Matching Reward (CSMR) provides immediate step-level rewards to mitigate sparsity. By executing queries at each turn, CSMR converts binary (0/1) feedback into dense [0, 1] signals based on partial correctness. Evaluations on BIRD show a 5% gain over binary-reward GRPO. Notably, our approach outperforms SOTA Arctic-Text2SQL-R1-7B on BIRD and Spider 2.0 using identical models, propelling Text-to-SQL toward a robust multi-turn agent paradigm.
DyJR: Preserving Diversity in Reinforcement Learning with Verifiable Rewards via Dynamic Jensen-Shannon Replay
Mar 17, 2026While Reinforcement Learning (RL) enhances Large Language Model reasoning, on-policy algorithms like GRPO are sample-inefficient as they discard past rollouts. Existing experience replay methods address this by reusing accurate samples for direct policy updates, but this often incurs high computational costs and causes mode collapse via overfitting. We argue that historical data should prioritize sustaining diversity rather than simply reinforcing accuracy. To this end, we propose Dynamic Jensen-Shannon Replay (DyJR), a simple yet effective regularization framework using a dynamic reference distribution from recent trajectories. DyJR introduces two innovations: (1) A Time-Sensitive Dynamic Buffer that uses FIFO and adaptive sizing to retain only temporally proximal samples, synchronizing with model evolution; and (2) Jensen-Shannon Divergence Regularization, which replaces direct gradient updates with a distributional constraint to prevent diversity collapse. Experiments on mathematical reasoning and Text-to-SQL benchmarks demonstrate that DyJR significantly outperforms GRPO as well as baselines such as RLEP and Ex-GRPO, while maintaining training efficiency comparable to the original GRPO. Furthermore, from the perspective of Rank-$k$ token probability evolution, we show that DyJR enhances diversity and mitigates over-reliance on Rank-1 tokens, elucidating how specific sub-modules of DyJR influence the training dynamics.
PET-F2I: A Comprehensive Benchmark and Parameter-Efficient Fine-Tuning of LLMs for PET/CT Report Impression Generation
Mar 11, 2026PET/CT imaging is pivotal in oncology and nuclear medicine, yet summarizing complex findings into precise diagnostic impressions is labor-intensive. While LLMs have shown promise in medical text generation, their capability in the highly specialized domain of PET/CT remains underexplored. We introduce PET-F2I-41K (PET Findings-to-Impression Benchmark), a large-scale benchmark for PET/CT impression generation using LLMs, constructed from over 41k real-world reports. Using PET-F2I-41K, we conduct a comprehensive evaluation of 27 models across proprietary frontier LLMs, open-source generalist models, and medical-domain LLMs, and we develop a domain-adapted 7B model (PET-F2I-7B) fine-tuned from Qwen2.5-7B-Instruct via LoRA. Beyond standard NLG metrics (e.g., BLEU-4, ROUGE-L, BERTScore), we propose three clinically grounded metrics - Entity Coverage Rate (ECR), Uncovered Entity Rate (UER), and Factual Consistency Rate (FCR) - to assess diagnostic completeness and factual reliability. Experiments reveal that neither frontier nor medical-domain LLMs perform adequately in zero-shot settings. In contrast, PET-F2I-7B achieves substantial gains (e.g., 0.708 BLEU-4) and a 3.0x improvement in entity coverage over the strongest baseline, while offering advantages in cost, latency, and privacy. Beyond this modeling contribution, PET-F2I-41K establishes a standardized evaluation framework to accelerate the development of reliable and clinically deployable reporting systems for PET/CT.
Equivariant Asynchronous Diffusion: An Adaptive Denoising Schedule for Accelerated Molecular Conformation Generation
Mar 10, 2026Recent 3D molecular generation methods primarily use asynchronous auto-regressive or synchronous diffusion models. While auto-regressive models build molecules sequentially, they're limited by a short horizon and a discrepancy between training and inference. Conversely, synchronous diffusion models denoise all atoms at once, offering a molecule-level horizon but failing to capture the causal relationships inherent in hierarchical molecular structures. We introduce Equivariant Asynchronous Diffusion (EAD) to overcome these limitations. EAD is a novel diffusion model that combines the strengths of both approaches: it uses an asynchronous denoising schedule to better capture molecular hierarchy while maintaining a molecule-level horizon. Since these relationships are often complex, we propose a dynamic scheduling mechanism to adaptively determine the denoising timestep. Experimental results show that EAD achieves state-of-the-art performance in 3D molecular generation.
The Choice of Divergence: A Neglected Key to Mitigating Diversity Collapse in Reinforcement Learning with Verifiable Reward
Sep 09, 2025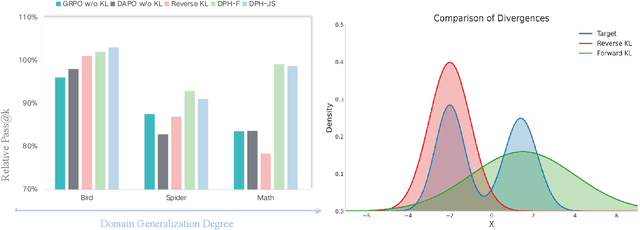

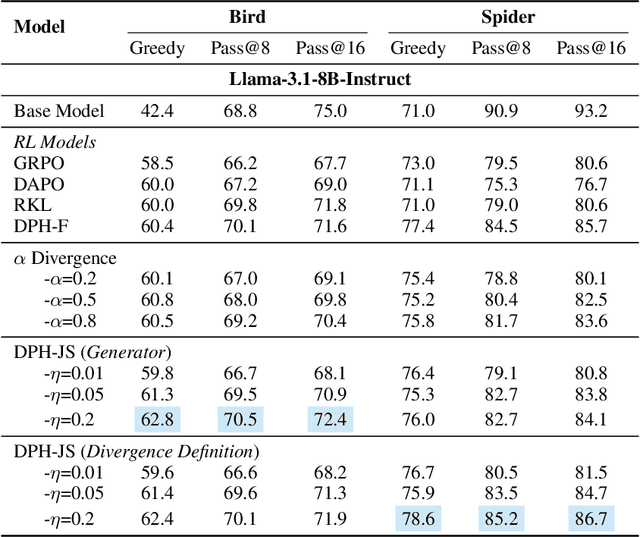
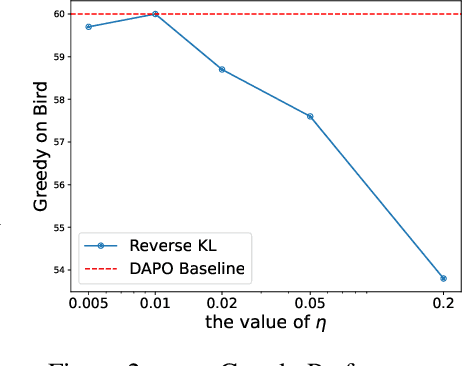
A central paradox in fine-tuning Large Language Models (LLMs) with Reinforcement Learning with Verifiable Reward (RLVR) is the frequent degradation of multi-attempt performance (Pass@k) despite improvements in single-attempt accuracy (Pass@1). This is often accompanied by catastrophic forgetting, where models lose previously acquired skills. While various methods have been proposed, the choice and function of the divergence term have been surprisingly unexamined as a proactive solution. We argue that standard RLVR objectives -- both those using the mode-seeking reverse KL-divergence and those forgoing a divergence term entirely -- lack a crucial mechanism for knowledge retention. The reverse-KL actively accelerates this decay by narrowing the policy, while its absence provides no safeguard against the model drifting from its diverse knowledge base. We propose a fundamental shift in perspective: using the divergence term itself as the solution. Our framework, Diversity-Preserving Hybrid RL (DPH-RL), leverages mass-covering f-divergences (like forward-KL and JS-divergence) to function as a rehearsal mechanism. By continuously referencing the initial policy, this approach forces the model to maintain broad solution coverage. Extensive experiments on math and SQL generation demonstrate that DPH-RL not only resolves the Pass@k degradation but improves both Pass@1 and Pass@k in- and out-of-domain. Additionally, DPH-RL is more training-efficient because it computes f-divergence using generator functions, requiring only sampling from the initial policy and no online reference model. Our work highlights a crucial, overlooked axis for improving RLVR, demonstrating that the proper selection of a divergence measure is a powerful tool for building more general and diverse reasoning models.
Uni-cot: Towards Unified Chain-of-Thought Reasoning Across Text and Vision
Aug 07, 2025
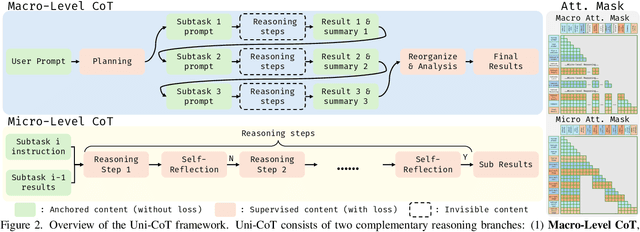

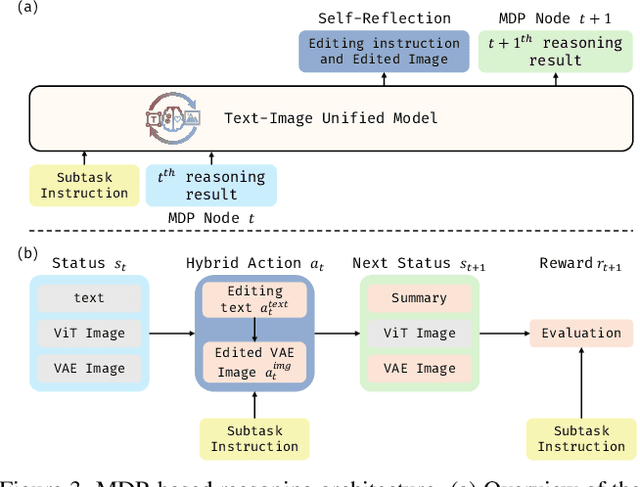
Chain-of-Thought (CoT) reasoning has been widely adopted to enhance Large Language Models (LLMs) by decomposing complex tasks into simpler, sequential subtasks. However, extending CoT to vision-language reasoning tasks remains challenging, as it often requires interpreting transitions of visual states to support reasoning. Existing methods often struggle with this due to limited capacity of modeling visual state transitions or incoherent visual trajectories caused by fragmented architectures. To overcome these limitations, we propose Uni-CoT, a Unified Chain-of-Thought framework that enables coherent and grounded multimodal reasoning within a single unified model. The key idea is to leverage a model capable of both image understanding and generation to reason over visual content and model evolving visual states. However, empowering a unified model to achieve that is non-trivial, given the high computational cost and the burden of training. To address this, Uni-CoT introduces a novel two-level reasoning paradigm: A Macro-Level CoT for high-level task planning and A Micro-Level CoT for subtask execution. This design significantly reduces the computational overhead. Furthermore, we introduce a structured training paradigm that combines interleaved image-text supervision for macro-level CoT with multi-task objectives for micro-level CoT. Together, these innovations allow Uni-CoT to perform scalable and coherent multi-modal reasoning. Furthermore, thanks to our design, all experiments can be efficiently completed using only 8 A100 GPUs with 80GB VRAM each. Experimental results on reasoning-driven image generation benchmark (WISE) and editing benchmarks (RISE and KRIS) indicates that Uni-CoT demonstrates SOTA performance and strong generalization, establishing Uni-CoT as a promising solution for multi-modal reasoning. Project Page and Code: https://sais-fuxi.github.io/projects/uni-cot/
Equivariant Spherical Transformer for Efficient Molecular Modeling
May 29, 2025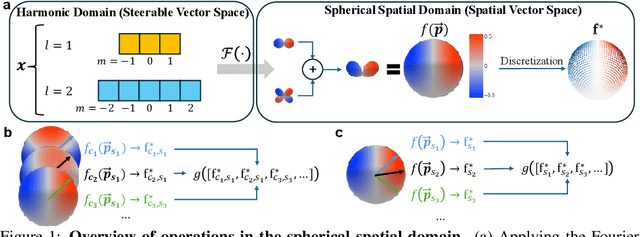
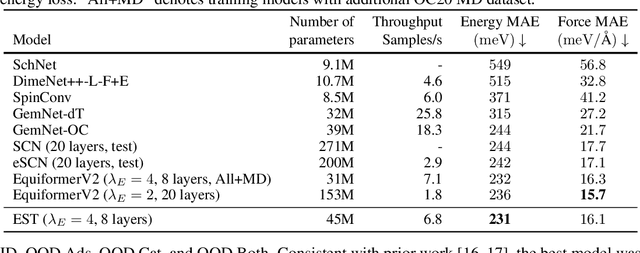
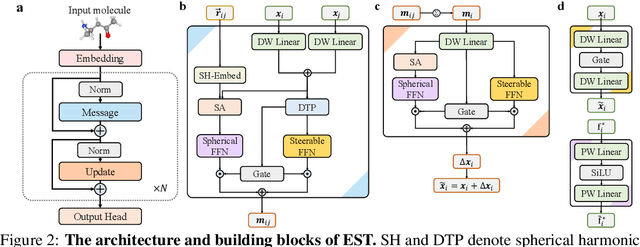
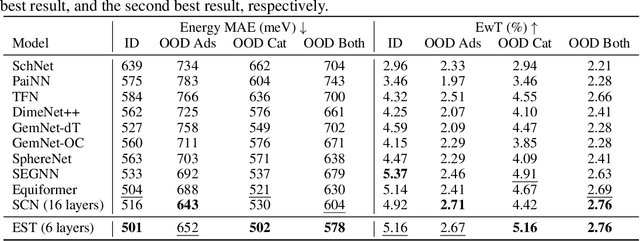
SE(3)-equivariant Graph Neural Networks (GNNs) have significantly advanced molecular system modeling by employing group representations. However, their message passing processes, which rely on tensor product-based convolutions, are limited by insufficient non-linearity and incomplete group representations, thereby restricting expressiveness. To overcome these limitations, we introduce the Equivariant Spherical Transformer (EST), a novel framework that leverages a Transformer structure within the spatial domain of group representations after Fourier transform. We theoretically and empirically demonstrate that EST can encompass the function space of tensor products while achieving superior expressiveness. Furthermore, EST's equivariant inductive bias is guaranteed through a uniform sampling strategy for the Fourier transform. Our experiments demonstrate state-of-the-art performance by EST on various molecular benchmarks, including OC20 and QM9.
VL-Rethinker: Incentivizing Self-Reflection of Vision-Language Models with Reinforcement Learning
Apr 10, 2025Recently, slow-thinking systems like GPT-o1 and DeepSeek-R1 have demonstrated great potential in solving challenging problems through explicit reflection. They significantly outperform the best fast-thinking models, such as GPT-4o, on various math and science benchmarks. However, their multimodal reasoning capabilities remain on par with fast-thinking models. For instance, GPT-o1's performance on benchmarks like MathVista, MathVerse, and MathVision is similar to fast-thinking models. In this paper, we aim to enhance the slow-thinking capabilities of vision-language models using reinforcement learning (without relying on distillation) to advance the state of the art. First, we adapt the GRPO algorithm with a novel technique called Selective Sample Replay (SSR) to address the vanishing advantages problem. While this approach yields strong performance, the resulting RL-trained models exhibit limited self-reflection or self-verification. To further encourage slow-thinking, we introduce Forced Rethinking, which appends a textual rethinking trigger to the end of initial rollouts in RL training, explicitly enforcing a self-reflection reasoning step. By combining these two techniques, our model, VL-Rethinker, advances state-of-the-art scores on MathVista, MathVerse, and MathVision to achieve 80.3%, 61.8%, and 43.9% respectively. VL-Rethinker also achieves open-source SoTA on multi-disciplinary benchmarks such as MMMU-Pro, EMMA, and MEGA-Bench, narrowing the gap with GPT-o1.